Deep-Metric-Learning-Baselines
Deep-Metric-Learning-Baselines 是一个基于 PyTorch 的深度学习度量学习框架,为研究人员提供了完整且易于扩展的训练与评估流水线。它集成了多种主流损失函数(如 Triplet Loss、Margin Loss、ProxyNCA)、采样策略(包括随机采样、半硬采样等)以及标准数据集(CUB200、CARS196、Stanford Online Products 等),帮助用户快速验证和对比不同方法在图像检索、人脸识别等任务上的表现。
这个框架最大的特点是模块化设计,让你可以轻松添加新的损失函数、采样器或网络架构,无需从零搭建基础组件,从而专注于核心算法创新。特别适合计算机视觉领域的研究者和开发者使用,能显著降低实验门槛,提升研究效率。
如果你正在从事度量学习相关研究,这个工具能帮你节省大量重复性工作,快速建立实验基准。
使用场景
某电商平台算法团队正在开发"以图搜款"功能,需要训练一个模型让用户上传街拍照片就能找到相似商品。团队5名成员需要在2周内验证多种深度度量学习方案,数据包含15万张服饰图片,覆盖800多个品类。
没有 Deep-Metric-Learning-Baselines 时
- 重复造轮子耗时费力:工程师小张需要手写Triplet Loss、ProxyNCA等损失函数,光是调试Margin Loss的采样策略就花了3天,代码还频繁出现维度不匹配错误
- 算法对比不公平:不同论文的实现细节差异大,小王复现的N-Pair Loss与原始论文效果差距明显,无法确定是参数问题还是实现bug,团队内部争论不休
- 组合实验效率低:想测试"ResNet50+Distance Sampling+Margin Loss"组合,需要手动修改数据加载、采样逻辑和训练循环,每次尝试都要重写大量胶水代码
- 评估指标实现困难:召回率@K、NMI等指标计算复杂,小李花了整整一周才实现完整的评估流程,结果与论文数据仍有偏差
使用 Deep-Metric-Learning-Baselines 后
- 一键启动标准化训练:团队直接调用
Standard_Training.py,15分钟就跑通第一个Triplet Loss基线,所有接口统一,无需担心底层实现细节 - 公平对比即插即用:通过修改配置文件即可切换ProxyNCA、N-Pair等损失函数,内置的采样策略确保实验条件一致,2天内完成5种算法的横向评测
- 模块化组合灵活:在
losses.py中自由组合Distance Sampling与Margin Loss,通过参数配置快速尝试20多种方案,代码复用率达90%以上 - 开箱即用的评估体系:直接调用
evaluate.py获取标准指标,与论文结果对齐准确,团队将精力集中在模型优化而非工程实现
核心价值:Deep-Metric-Learning-Baselines 将算法验证周期从3周压缩至3天,让团队专注创新而非重复劳动,最终准时上线功能并提升搜索准确率12%。
运行环境要求
- 未说明
需要 NVIDIA GPU,支持 CUDA 8 或 CUDA 9(未指定具体显卡型号和显存大小)
未说明
快速开始
易于扩展的基础深度度量学习流水线
Karsten Roth (karsten.rh1@gmail.com), Biagio Brattoli (biagio.brattoli@gmail.com)
在学术工作中使用此仓库时,请引用
@misc{roth2020revisiting,
title={Revisiting Training Strategies and Generalization Performance in Deep Metric Learning},
author={Karsten Roth and Timo Milbich and Samarth Sinha and Prateek Gupta and Björn Ommer and Joseph Paul Cohen},
year={2020},
eprint={2002.08473},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
基于该仓库的扩展版本,我们进行了深度度量学习的全面比较与评估:
https://arxiv.org/abs/2002.08473
新发布的代码可在此处找到:https://github.com/Confusezius/Revisiting_Deep_Metric_Learning_PyTorch
其中包含更多的损失函数、采样器、评估指标和日志记录选项!
使用方法请参见第3节,实验结果请参见第4节
1. 概述
本仓库包含一个完整且易于扩展的流水线,用于测试和实现当前及新的深度度量学习方法。作为参考和测试,本仓库实现了以下组件:
损失函数
- Triplet Loss(三元组损失)(https://arxiv.org/abs/1412.6622)
- Margin Loss(间隔损失)(https://arxiv.org/abs/1706.07567)
- ProxyNCA(代理NCA损失)(https://arxiv.org/abs/1703.07464)
- N-Pair Loss(N对损失)(https://papers.nips.cc/paper/6200-improved-deep-metric-learning-with-multi-class-n-pair-loss-objective.pdf)
采样方法
- Random Sampling(随机采样)
- Softhard Sampling(软难采样,困难元组采样的软版本)
- Semihard Sampling(半难采样)(https://arxiv.org/abs/1503.03832)
- Distance Sampling(距离采样)(https://arxiv.org/abs/1706.07567)
- N-Pair Sampling(N对采样)(https://papers.nips.cc/paper/6200-improved-deep-metric-learning-with-multi-class-n-pair-loss-objective.pdf)
数据集
- CUB200-2011 (http://www.vision.caltech.edu/visipedia/CUB-200.html)
- CARS196 (https://ai.stanford.edu/~jkrause/cars/car_dataset.html)
- Stanford Online Products (http://cvgl.stanford.edu/projects/lifted_struct/)
- In-Shop Clothes (http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/InShopRetrieval.html, 从 https://drive.google.com/drive/folders/0B7EVK8r0v71pVDZFQXRsMDZCX1E 下载。感谢 KunHe 提供链接!)
- (可选)PKU Vehicle-ID (https://www.pkuml.org/resources/pku-vds.html)
网络架构
- ResNet50 (https://arxiv.org/abs/1512.03385)
- GoogLeNet (https://arxiv.org/abs/1409.4842)
[注:此版本遵循官方torchvision实现,与原始版本有所不同。]
注意: PKU Vehicle-ID 是_(可选的)_,因为没有直接下载该数据集的方式,它需要特殊许可。但是,如果该数据集可用(结构如2.2节所示),则可以直接使用。
1.1 相关仓库:
- Metric Learning with Mined Interclass Characteristics
- Metric Learning by dividing the embedding space
- Deep Metric Learning to Rank
2. 仓库与数据集结构
2.1 仓库结构
Repository
│ ### 通用文件
│ README.md
│ requirements.txt
│ installer.sh
|
| ### 主脚本
| Standard_Training.py (主训练脚本)
| losses.py (损失函数和采样实现集合)
│ datasets.py (所有数据集的数据加载器)
│
│ ### 工具脚本
| auxiliaries.py (实用工具集合)
| evaluate.py (评估函数集合)
│
│ ### 网络脚本
| netlib.py (ResNet50实现)
| googlenet.py (GoogLeNet实现)
│
│
└───Training Results (训练过程中生成)
| │ e.g. cub200/Training_Run_Name
| │ e.g. cars196/Training_Run_Name
|
│
└───Datasets (应添加到此,如果不想设置路径)
| │ cub200
| │ cars196
| │ online_products
| │ in-shop
| │ vehicle_id
2.2 数据集结构
CUB200-2011/CARS196
cub200/cars196
└───images
| └───001.Black_footed_Albatross
| │ Black_Footed_Albatross_0001_796111
| │ ...
| ...
Online Products
online_products
└───images
| └───bicycle_final
| │ 111085122871_0.jpg
| ...
|
└───Info_Files
| │ bicycle.txt
| │ ...
In-Shop Clothes
in-shop
└─img
| └─MEN
| └─Denim
| └─id_00000080
| │ 01_1_front.jpg
| │ ...
| ...
| ...
| ...
|
└─Eval
| │ list_eval_partition.txt
PKU Vehicle ID
vehicle_id
└───image
| │ <img>.jpg
| | ...
|
└───train_test_split
| | test_list_800.txt
| | ...
3. 使用流水线
[1.] 环境要求
该流水线基于 Python3(即通过安装 Miniconda https://conda.io/miniconda.html)和 Pytorch 1.0.0/1 构建。已在 cuda 8 和 cuda 9 环境下测试。
要安装所需的库,可以直接查看 requirements.txt 或创建 conda 环境:
conda create -n <Env_Name> python=3.6
激活环境
conda activate <Env_Name>
然后运行
bash installer.sh
注意,对于 k均值聚类(kMeans)和最近邻(Nearest Neighbour)计算,我们使用了 faiss 库,如果需要速度,可以将这些计算移动到GPU上。然而,在大多数情况下,faiss 已经足够快,使得评估指标的计算不会成为瓶颈。
注意: 如果不想使用 faiss 而想使用标准的 sklearn,只需在导入库时使用 auxiliaries_nofaiss.py 替换 auxiliaries.py。
[2.] 示例运行
主脚本是 Standard_Training.py。如果不带输入参数运行,将执行在 CUB200-2011 数据集上使用 Marginloss(边际损失)和 Distance-sampling(距离采样)对 ResNet50 进行训练。
否则,可以使用以下标志来使用不同的损失函数(loss)、采样方法(sampling)、架构(arch)和数据集(dataset)进行训练:
python Standard_Training.py --dataset <dataset> --loss <loss> --sampling <sampling> --arch <arch> --k_vals <k_vals> --embed_dim <embed_dim>
以下标志可用:
<dataset> <- cub200, cars196, online_products, in-shop, vehicle_id<loss> <- marginloss, triplet, npair, proxynca<sampling> <- distance, semihard, random, npair<arch> <- resnet50, googlenet<k_vals> <- 要评估的 Recall @ k 值列表,例如 1 2 4 8<embed_dim> <- 网络嵌入维度。默认值:ResNet50 为 128,GoogLeNet 为 512。
对于所有其他训练相关的参数(例如 batch-size(批大小)、num. training epochs(训练轮数)等),只需参考 Standard_Training.py 中的输入参数。
注意:如果希望为最终的线性嵌入层(linear embedding layer)使用不同的学习率(learning rate),需要将标志 --fc_lr_mul 设置为非零值(即 10,如各种实现中所做的那样)。
最后,要决定使用哪个 GPU(图形处理器)以及存储网络权重、样本恢复(sample recoveries)和指标(metrics)的训练文件夹名称,请设置:
python Standard_Training.py --gpu <gpu_id> --savename <name_of_training_run>
如果未设置 --savename,将基于开始日期选择一个默认名称。
如果希望简单地使用标准参数并获得接近文献结果的效果(或多或少取决于随机种子和整体训练调度),请参考 sample_training_runs.sh,其中包含一系列可执行的单行命令。
[3.] 关于可扩展性的实现说明:
要扩展或测试其他采样或损失方法,只需执行:
对于基于批次的采样(Batch-based Sampling):
在 losses.py 中,添加采样方法,该方法应作用于一个批次(batch)以及相应的标签集,例如:
def new_sampling(self, batch, label, **additional_parameters): ...
如果需要与现有损失函数一起运行,此函数应返回一个包含相对于批次的索引的元组列表,例如对于返回三元组的采样方法:
return [(anchor_idx, positive_idx, negative_idx) for anchor_idx, positive_idx, negative_idx in zip(anchor_idxs, positive_idxs, negative_idxs)]
同时,别忘了在 Sampler.__init__() 中添加一个句柄。
对于特定数据的采样(Data-specific Sampling):
要影响用于生成批次的数据样本,请在 datasets.py 中编辑 BaseTripletDataset。
对于新的损失函数(Loss Functions):
只需添加一个继承自 torch.nn.Module(PyTorch 模块基类)的新类。参考其他损失变体以了解如何实现。通常,需要包含一个 Sampler 类的实例,该实例将在 forward()(前向传播)期间通过调用 self.sampler_instance.give(batch, labels, **additional_parameters) 提供采样的数据元组。最后,将损失函数包含在 loss_select() 函数中。参数可以通过字典表示法传递(参见其他示例),如果添加了可学习的参数,请将它们包含在 to_optim 列表中。
[4.] 存储的数据:
默认情况下,会保存以下文件:
Name_of_Training_Run
| checkpoint.pth.tar -> 包含网络 state-dict(状态字典)
| hypa.pkl -> 包含所有网络参数的 pickle(Python 序列化格式)文件
| 可直接用于重新创建网络
| log_train_Base.csv -> 记录的训练数据(CSV 格式)
| log_val_Base.csv -> 记录的测试指标(CSV 格式)
| Parameter_Info.txt -> 所有参数以可读文本文件形式存储
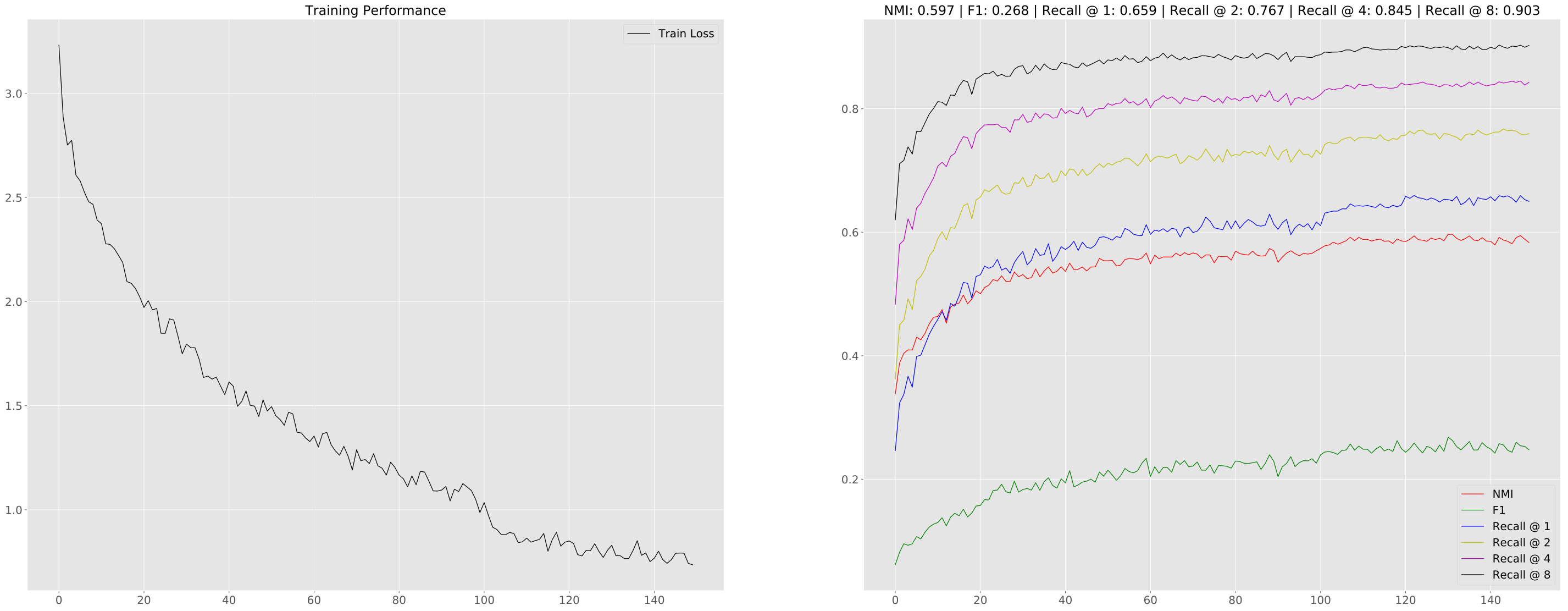
| InfoPlot_Base.svg -> 训练/测试指标进展的图形化总结
| sample_recoveries.png -> 最佳验证权重下的样本恢复结果
| 作为合理性测试
 注意: 红色表示查询图像,绿色显示相应的最近邻。
注意: 红色表示查询图像,绿色显示相应的最近邻。
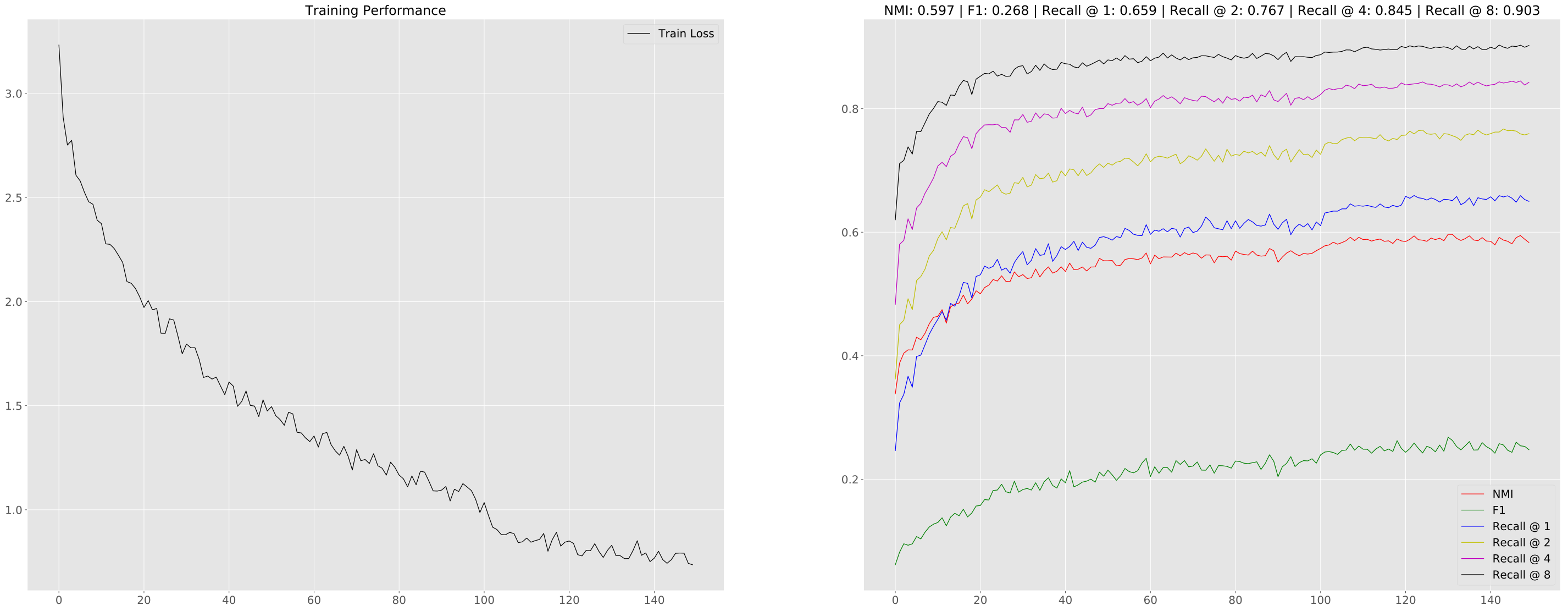 注意: 摘要图中的标题显示整个运行过程中的最佳测试指标。
注意: 摘要图中的标题显示整个运行过程中的最佳测试指标。
[5.] 附加说明:
最后,在检查相应运行时,以下几个标志可能值得关注:
--dist_measure: 如果设置,将计算每轮迭代后的平均类内距离(intraclass-distances)与平均类间距离(interclass distances)之比
(通过质心距离(center-of-mass distances)度量),并存储/绘制该值
--grad_measure: 如果设置,将从嵌入层到最后一层卷积层(conv. layer)的平均(绝对)梯度存储在 Pickle-File(Pickle 文件)中。这可用于检查每次迭代期间特征的变化
更多详情,请参考 auxiliaries.py 中的相应类。
4. 结果
这些结果是通过运行 sample_training_runs.sh 中的相应命令获得的性能估计。请注意,学习率调度(learning rate scheduling)可能未完全优化,因此这些值仅应作为参考/预期,而非通过更多调整所能最终达到的性能。
另请注意,结果对所使用的随机种子(seed)有不可忽视的依赖性。
CUB200
| 架构 | 损失/采样 | NMI | F1 | Recall @ 1 -- 2 -- 4 -- 8 |
|---|---|---|---|---|
| ResNet50 | Margin/Distance | 68.2 | 38.7 | 63.4 -- 74.9 -- 86.0 -- 90.4 |
| ResNet50 | Triplet/Softhard | 66.2 | 35.5 | 61.2 -- 73.2 -- 82.4 -- 89.5 |
| ResNet50 | NPair/None | 65.4 | 33.8 | 59.0 -- 71.3 -- 81.1 -- 88.8 |
| ResNet50 | ProxyNCA/None | 68.1 | 38.1 | 64.0 -- 75.4 -- 84.2 -- 90.5 |
Cars196
| 架构 | 损失/采样 | NMI | F1 | Recall @ 1 -- 2 -- 4 -- 8 |
|---|---|---|---|---|
| ResNet50 | Margin/Distance | 67.2 | 37.6 | 79.3 -- 87.1 -- 92.1 -- 95.4 |
| ResNet50 | Triplet/Softhard | 64.4 | 32.4 | 75.4 -- 84.2 -- 90.1 -- 94.1 |
| ResNet50 | NPair/None | 62.3 | 30.1 | 69.5 -- 80.2 -- 87.3 -- 92.1 |
| ResNet50 | ProxyNCA/None | 66.3 | 35.8 | 80.0 -- 87.2 -- 91.8 -- 95.1 |
Online Products
| 架构 | 损失/采样 | NMI | F1 | Recall @ 1 -- 10 -- 100 -- 1000 |
|---|---|---|---|---|
| ResNet50 | Margin/Distance | 89.6 | 34.9 | 76.1 -- 88.7 -- 95.1 -- 98.3 |
| ResNet50 | Triplet/Softhard | 89.1 | 33.7 | 74.3 -- 87.6 -- 94.9 -- 98.5 |
| ResNet50 | NPair/None | 88.8 | 31.1 | 70.9 -- 85.2 -- 93.8 -- 98.2 |
In-Shop Clothes
| 架构 | 损失/采样 | NMI | F1 | Recall @ 1 -- 10 -- 20 -- 30 -- 50 |
|---|---|---|---|---|
| ResNet50 | Margin/Distance | 88.2 | 27.7 | 84.5 -- 96.1 -- 97.4 -- 97.9 -- 98.5 |
| ResNet50 | Triplet/Semihard | 89.0 | 30.8 | 83.9 -- 96.3 -- 97.6 -- 98.4 -- 98.8 |
| ResNet50 | NPair/None | 88.0 | 27.6 | 80.9 -- 95.0 -- 96.6 -- 97.5 -- 98.2 |
注意:
- 关于 Vehicle-ID:由于测试集数量、训练集规模以及公开可访问性较低,暂不提供结果。
- 关于 Online Products 和 In-Shop Clothes 的 ProxyNCA:由于类别数量过多,所需的代理数量对于有效训练而言过高(>10000 个代理)。
待办事项:
- 修复
requirements.txt中的版本 - 添加实现的结果
- 完善注释
- 添加 Inception-BN
- 添加 Lifted Structure Loss
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。