tensorflow-DeepFM
tensorflow-DeepFM 是基于 TensorFlow 框架实现的 DeepFM 模型开源项目,专注于点击率(CTR)预测及回归任务。它巧妙结合了因子分解机(FM)与深度神经网络(DNN)的优势,能够同时自动学习低阶和高阶特征交互,有效解决了传统模型在特征组合挖掘上的局限性,从而提升预测精度。
tensorflow-DeepFM 非常适合从事推荐系统、广告算法的研究人员及开发者使用。它不仅支持分类与回归两种任务模式,还允许用户灵活配置是否启用 FM 或 DNN 组件。tensorflow-DeepFM 提供了完整的数据预处理示例及训练代码,支持早停(early_stopping)和模型重拟合等功能,曾助力团队在 Kaggle 竞赛中获得优异成绩。无论是学术研究还是工业界落地,tensorflow-DeepFM 都为处理稀疏特征数据提供了一个高效、易用的基准方案。
使用场景
某电商平台的算法团队正在优化广告点击率(CTR)预估模型,面对海量稀疏的用户行为数据,传统方法效果遭遇瓶颈。
没有 tensorflow-DeepFM 时
- 特征交叉严重依赖人工经验,难以捕捉高阶隐含关系,不仅耗时且关键特征易遗漏。
- 传统逻辑回归模型对稀疏特征表达能力弱,AUC 指标长期停滞在 0.75 左右,难以突破性能瓶颈。
- 单独使用 FM 或 DNN 无法兼顾低阶与高阶特征交互,导致模型泛化能力不足,线上效果不稳定。
- 数据格式转换繁琐,缺乏统一的训练框架,导致迭代实验效率低下,难以快速响应业务需求。
使用 tensorflow-DeepFM 后
- tensorflow-DeepFM 自动学习低阶和高阶特征交互,无需人工构造交叉特征,直接节省 80% 的特征工程时间。
- 结合 FM 与 DNN 优势,有效处理稀疏输入,CTR 预估 AUC 提升至 0.82,直接显著增加广告收入。
- 支持灵活配置 embedding_size 及网络层数,可快速适配不同业务场景的分类或回归任务,灵活性极高。
- 内置标准化数据接口与早停机制,训练流程规范化,模型迭代周期从周缩短至天,研发效率大幅提升。
核心价值在于通过端到端的特征交互学习,大幅提升了稀疏数据下的预测精度与研发效率。
运行环境要求
- 未说明
未说明
未说明

快速开始
tensorflow-DeepFM
本项目包含了 DeepFM(基于因子分解机的神经网络)[1] 的 TensorFlow 实现。
新闻
- DeepFM 的一个修改版本被用于赢得 Kaggle Mercari 价格建议挑战赛 的第 4 名。查看 此处 的幻灯片,了解我们如何处理包含序列的字段,以及如何将各种 FM(因子分解机)组件整合到深度模型中。
使用方法
输入格式
本实现要求输入数据采用以下格式:
- Xi: [[ind1_1, ind1_2, ...], [ind2_1, ind2_2, ...], ..., [indi_1, indi_2, ..., indi_j, ...], ...]
- indi_j 是数据集中样本 i 的特征字段 j 的特征索引
- Xv: [[val1_1, val1_2, ...], [val2_1, val2_2, ...], ..., [vali_1, vali_2, ..., vali_j, ...], ...]
- vali_j 是数据集中样本 i 的特征字段 j 的特征值
- vali_j 可以是二进制(1/0,用于二进制/类别特征)或浮点数(例如 10.24,用于数值特征)
- y: 数据集中每个样本的目标值(分类任务为 1/0,回归任务为数值)
请参阅 example/DataReader.py 查看如何为 DeepFM 准备所需格式数据的示例。
初始化并训练模型
import tensorflow as tf
from sklearn.metrics import roc_auc_score
# params
dfm_params = {
"use_fm": True,
"use_deep": True,
"embedding_size": 8,
"dropout_fm": [1.0, 1.0],
"deep_layers": [32, 32],
"dropout_deep": [0.5, 0.5, 0.5],
"deep_layers_activation": tf.nn.relu,
"epoch": 30,
"batch_size": 1024,
"learning_rate": 0.001,
"optimizer_type": "adam",
"batch_norm": 1,
"batch_norm_decay": 0.995,
"l2_reg": 0.01,
"verbose": True,
"eval_metric": roc_auc_score,
"random_seed": 2017
}
# prepare training and validation data in the required format
Xi_train, Xv_train, y_train = prepare(...)
Xi_valid, Xv_valid, y_valid = prepare(...)
# init a DeepFM model
dfm = DeepFM(**dfm_params)
# fit a DeepFM model
dfm.fit(Xi_train, Xv_train, y_train)
# make prediction
dfm.predict(Xi_valid, Xv_valid)
# evaluate a trained model
dfm.evaluate(Xi_valid, Xv_valid, y_valid)
您可以在训练中如下使用 early_stopping(早停):
dfm.fit(Xi_train, Xv_train, y_train, Xi_valid, Xv_valid, y_valid, early_stopping=True)
您可以如下在整个训练集和验证集上重新拟合模型:
dfm.fit(Xi_train, Xv_train, y_train, Xi_valid, Xv_valid, y_valid, early_stopping=True, refit=True)
您可以通过将参数 use_fm 或 use_dnn 设置为 False 来仅使用 FM(因子分解机)或 DNN(深度神经网络)部分。
回归
本实现也支持回归任务。要将 DeepFM 用于回归,您可以将 loss_type 设置为 mse(均方误差)。相应地,您应该使用用于回归的 eval_metric(评估指标),例如 mse 或 mae(平均绝对误差)。
示例
文件夹 example 包含了 DeepFM/FM/DNN 模型在 Kaggle Porto Seguro 安全驾驶员预测竞赛 中的使用示例。
请从竞赛网站下载数据并将其放入 example/data 文件夹中。
要为此数据集训练 DeepFM 模型,运行
$ cd example
$ python main.py
请参阅 example/DataReader.py 了解如何将原始数据集解析为 DeepFM 所需的格式。
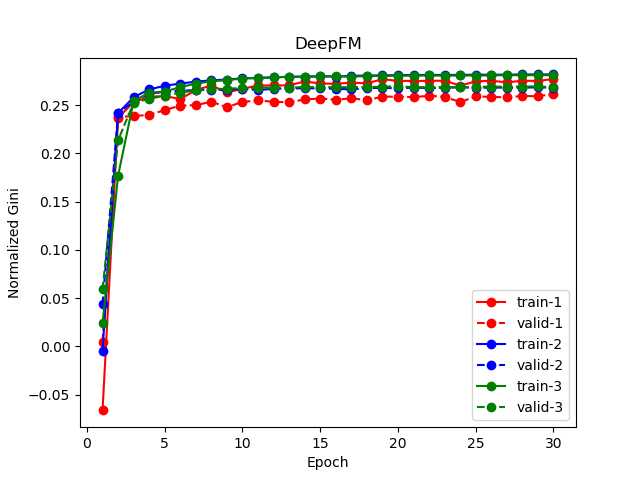
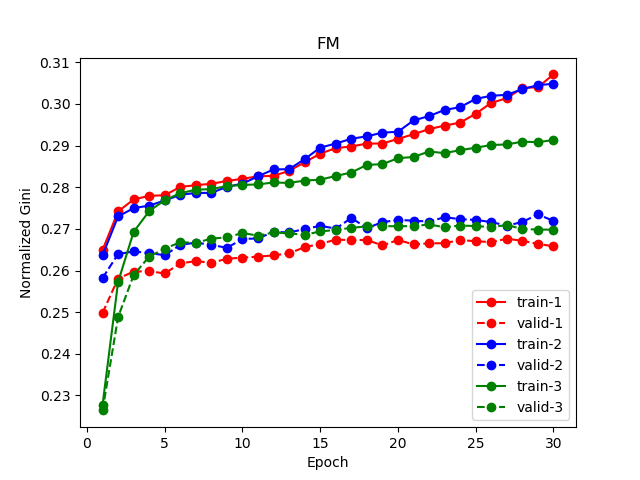
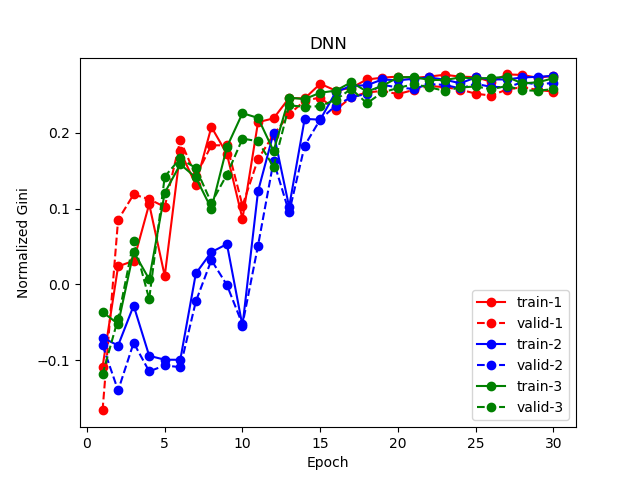
性能
DeepFM
FM
DNN
一些提示
- 为了获得合理的性能,您应该调整每个模型的参数。
- 您也可以尝试 ensemble(集成)这些模型,或将它们与其他模型(例如 XGBoost 或 LightGBM)集成。
参考文献
[1] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Huifeng Guo, Ruiming Tang, Yunming Yey, Zhenguo Li, Xiuqiang He.
致谢
本项目从以下项目获得灵感:
- He Xiangnan 的 neural_factorization_machine
- Jian Zhang 的 YellowFin(yellowfin 优化器取自此处)
许可证
MIT
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。
gpt4free
gpt4free 是一个由社区驱动的开源项目,旨在聚合多种可访问的大型语言模型(LLM)和媒体生成接口,让用户能更灵活、便捷地使用前沿 AI 能力。它解决了直接调用各类模型时面临的接口分散、门槛高或成本昂贵等痛点,通过统一的标准将不同提供商的资源整合在一起。 无论是希望快速集成 AI 功能的开发者、需要多模型对比测试的研究人员,还是想免费体验最新技术的普通用户,都能从中受益。gpt4free 提供了丰富的使用方式:既包含易于上手的 Python 和 JavaScript 客户端库,也支持部署本地图形界面(GUI),更提供了兼容 OpenAI 标准的 REST API,方便无缝替换现有应用后端。 其技术亮点在于强大的多提供商支持架构,能够动态调度包括 Opus、Gemini、DeepSeek 等多种主流模型资源,并支持 Docker 一键部署及本地推理。项目秉持社区优先原则,在降低使用门槛的同时,也为贡献者提供了扩展新接口的便利框架,是探索和利用多样化 AI 资源的实用工具。
gstack
gstack 是 Y Combinator CEO Garry Tan 亲自开源的一套 AI 工程化配置,旨在将 Claude Code 升级为你的虚拟工程团队。面对单人开发难以兼顾产品战略、架构设计、代码审查及质量测试的挑战,gstack 提供了一套标准化解决方案,帮助开发者实现堪比二十人团队的高效产出。 这套配置特别适合希望提升交付效率的创始人、技术负责人,以及初次尝试 Claude Code 的开发者。gstack 的核心亮点在于内置了 15 个具有明确职责的 AI 角色工具,涵盖 CEO、设计师、工程经理、QA 等职能。用户只需通过简单的斜杠命令(如 `/review` 进行代码审查、`/qa` 执行测试、`/plan-ceo-review` 规划功能),即可自动化处理从需求分析到部署上线的全链路任务。 所有操作基于 Markdown 和斜杠命令,无需复杂配置,完全免费且遵循 MIT 协议。gstack 不仅是一套工具集,更是一种现代化的软件工厂实践,让单人开发者也能拥有严谨的工程流程。
meilisearch
Meilisearch 是一个开源的极速搜索服务,专为现代应用和网站打造,开箱即用。它能帮助开发者快速集成高质量的搜索功能,无需复杂的配置或额外的数据预处理。传统搜索方案往往需要大量调优才能实现准确结果,而 Meilisearch 内置了拼写容错、同义词识别、即时响应等实用特性,并支持 AI 驱动的混合搜索(结合关键词与语义理解),显著提升用户查找信息的体验。 Meilisearch 特别适合 Web 开发者、产品团队或初创公司使用,尤其适用于需要快速上线搜索功能的场景,如电商网站、内容平台或 SaaS 应用。它提供简洁的 RESTful API 和多种语言 SDK,部署简单,资源占用低,本地开发或生产环境均可轻松运行。对于希望在不依赖大型云服务的前提下,为用户提供流畅、智能搜索体验的团队来说,Meilisearch 是一个高效且友好的选择。
awesome-claude-skills
awesome-claude-skills 是一个精心整理的开源资源库,旨在帮助用户挖掘和扩展 Claude AI 的潜力。它不仅仅是一份列表,更提供了实用的“技能(Skills)”模块,让 Claude 从单纯的文本生成助手,进化为能执行复杂工作流的智能代理。 许多用户在使用 AI 时,常受限于其无法直接操作外部软件或处理特定格式文件的痛点。awesome-claude-skills 通过预设的工作流解决了这一问题:它不仅能教会 Claude 专业地处理 Word、PDF 等文档,进行代码开发与数据分析,还能借助 Composio 插件连接 Slack、邮箱及数百种常用应用,实现发送邮件、创建任务等自动化操作。这使得重复性任务变得标准化且可复用,极大提升了工作效率。 无论是希望优化日常办公流程的普通用户、需要处理复杂文档的研究人员,还是寻求将 AI 深度集成到开发管线中的开发者,都能从中找到适合的解决方案。其独特的技术亮点在于“技能”的可定制性与强大的应用连接能力,让用户无需编写复杂代码,即可通过简单的配置让 Claude 具备跨平台执行真实任务的能力。如果你希望让 Claude