Personae
Personae 是一个专为量化交易打造的开源项目,集成了深度强化学习与监督学习的前沿算法及模拟交易环境。它旨在解决金融市场中策略开发与验证的难题,通过提供标准化的代码实现和回测框架,帮助研究者将学术理论快速转化为可评估的交易策略。
该项目特别适合人工智能研究人员、量化开发者以及对算法交易感兴趣的学生使用。Personae 内置了多种经典算法的实现,包括用于连续控制交易的 DDPG、Double-DQN、Dueling-DQN 和策略梯度方法,以及用于时间序列价格预测的 DA-RNN、TreNet 和 LSTM 模型。其独特亮点在于构建了一个基于 Gym 风格的金融市场模拟环境,支持股票和期货数据的交互,能够直接为各类模型提供训练所需的回归或序列数据。
尽管项目提示输入特征较为基础且建议用户自定义优化,但它为探索不同神经网络架构在金融场景下的表现提供了坚实的起点。无论是想复现论文成果,还是希望搭建自己的智能交易代理,Personae 都是一个功能全面且易于扩展的技术底座。
使用场景
某量化初创团队的研究员正试图构建一个能自动适应市场波动的股票交易策略,但受限于传统统计模型的僵化,难以捕捉非线性规律。
没有 Personae 时
- 算法复现成本极高:研究员需从零编写 DDPG、Double DQN 等复杂的深度强化学习代码,耗费数周时间调试网络架构,严重拖慢策略迭代速度。
- 缺乏统一回测环境:自行搭建的模拟交易市场功能简陋,不支持期货与股票的统一接口,且难以处理做空机制,导致策略验证结果与实际表现偏差巨大。
- 特征工程盲目低效:只能使用简单的日线数据作为输入,缺乏如 DA-RNN 或 TreNet 等先进的时间序列注意力机制模型,无法有效提取趋势特征,预测准确率长期低迷。
- 基线对比困难:由于缺乏标准化的实验框架,难以将新策略与经典算法(如 Policy Gradient 或 LSTM)进行公平的性能基准对比,无法证明策略优越性。
使用 Personae 后
- 即插即用前沿算法:直接调用 Personae 内置的 TensorFlow 版本 DDPG、Dueling-DQN 及 DA-RNN 等实现,将算法部署时间从数周缩短至几天,快速验证想法。
- 标准化仿真环境:利用其自带的 Gym 风格金融市场环境,无缝切换股票与期货数据,获得更贴近真实的交易反馈,显著提升了回测的可信度。
- 高级模型提升精度:应用集成的双阶段注意力机制(DA-RNN)和混合神经网络(TreNet),有效捕捉长短期依赖关系,在相同数据下大幅提升了价格预测的准确度。
- 清晰的效果评估:基于统一的实验设置,轻松生成总收益与基准收益的对比图表,直观量化新策略相对于传统方法的超额收益,加速决策流程。
Personae 通过提供标准化的深度学习和强化学习实现及仿真环境,让量化团队能将精力从重复造轮子转移到核心策略创新上,显著缩短了从理论到实盘的周期。
运行环境要求
- Linux
- 可选
- 若使用 GPU 加速,需 NVIDIA GPU 支持 CUDA 8.0 及 cuDNN 6 (基于官方 Docker 镜像 nvidia/cuda:8.0-cudnn6-runtime)
未说明
快速开始
![]()
![]()
![]()
![]()
Personae - 强化学习与监督学习方法及量化交易环境
Personae 是一个实现深度强化学习和监督学习领域论文中提出的方法,并将其应用于金融市场的代码库。
目前,Personae 包含 4 种强化学习实现、3 种监督学习实现,以及一个支持股票和期货的金融市场模拟环境。(做空功能仍在开发中)
更多强化学习和监督学习方法正在持续更新中!
警告
本项目正在进行重构,
计划从 2018 年 8 月 24 日开始,持续到大约 2018 年 9 月 1 日——也就是我成功找到工作的那一天。
注意事项
- 输入特征较为简单。
- 日度频率显然不够。
- 建议用户根据自身需求替换此处的特征。
内容
深度确定性策略梯度 (DDPG)
使用 TensorFlow 实现 DDPG。arXiv:1509.02971: Continuous control with deep reinforcement learning
双 DQN
使用 TensorFlow 实现双 DQN。arXiv:1509.06461: Deep Reinforcement Learning with Double Q-learning
斗士-DQN
使用 TensorFlow 实现斗士-DQN。arXiv:1511.06581: Dueling Network Architectures for Deep Reinforcement Learning
策略梯度
使用 TensorFlow 实现策略梯度。NIPS. Vol. 99. 1999: Policy gradient methods for reinforcement learning with function approximation
DA-RNN (DualAttnRNN)
使用 TensorFlow 实现 arXiv:1704.02971 中提出的 DA-RNN。arXiv:1704.02971: A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction
TreNet (HNN)
使用 TensorFlow 实现 TreNet。IJCAI 2017. Hybrid Neural Networks for Learning the Trend in Time Series
Naive-LSTM (LSTM)
使用 TensorFlow 实现简单的 LSTM 模型。arXiv:1506.02078: Visualizing and Understanding Recurrent Networks
环境
实现了一个基础的金融市场模拟环境。
- 市场
实现了市场、交易者和持仓等组件,作为一个 gym 环境(无需依赖 gym 库),可以为 RL 或 SL 模型提供回归或序列数据生成的环境。
目前,市场支持股票数据和期货数据。
此外,更多功能正在持续开发中。
实验
- 深度确定性策略梯度 (DDPG)
- 双 DQN
- 斗士-DQN
- 策略梯度 (PG)
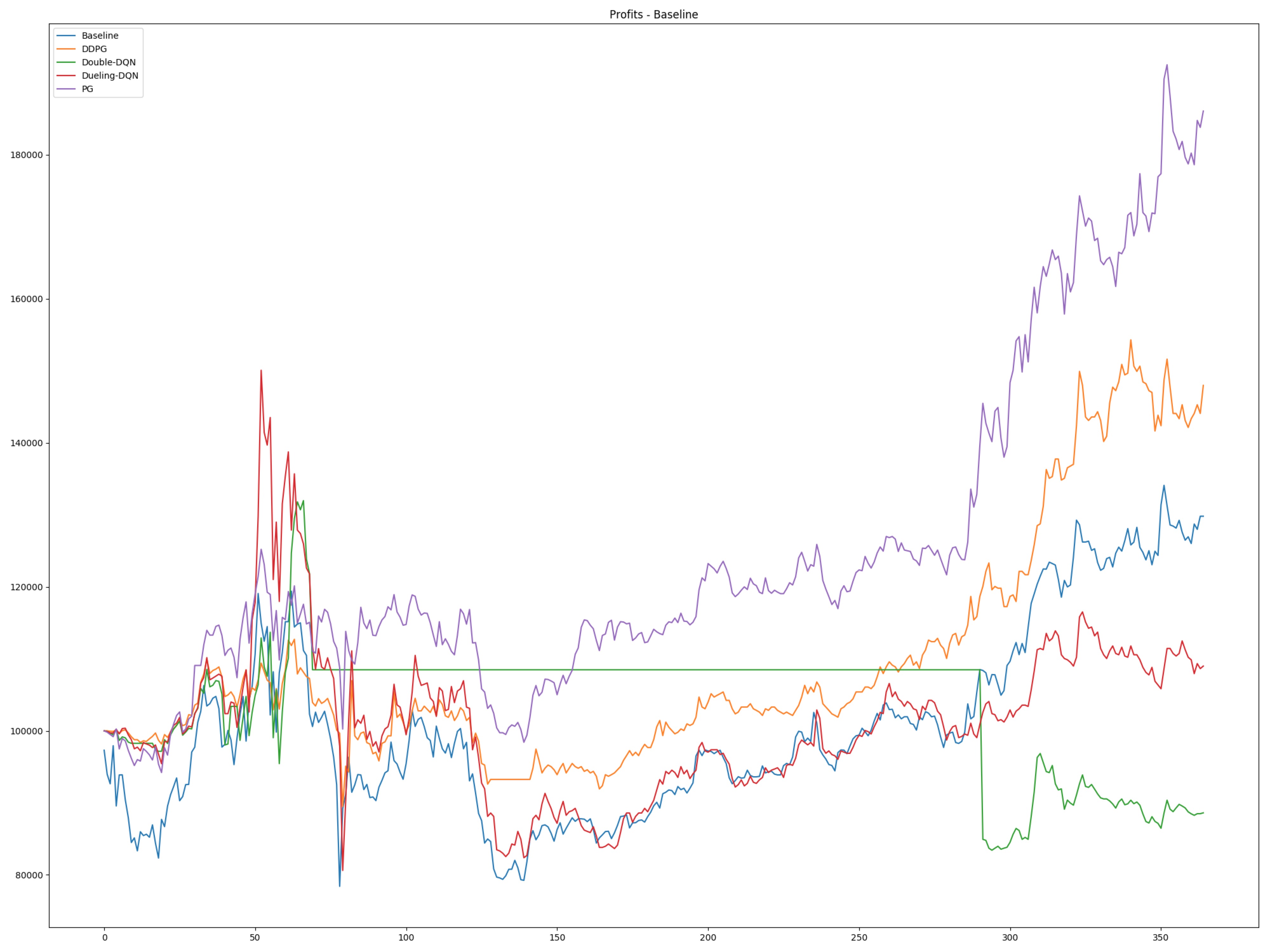
使用 2012 年 1 月 1 日至 2018 年 1 月 1 日的股票数据集训练一个代理在股票市场上进行交易,其中 70% 为训练数据,30% 为测试数据。
 总收益与基准收益。(测试集)
总收益与基准收益。(测试集)
- DA-RNN (DualAttnRNN)
- Naive-LSTM (LSTM)
- TreNet (HNN)
使用 2008 年 1 月 1 日至 2018 年 1 月 1 日的股票数据集训练一个预测模型来预测股价,其中 70% 为训练数据,30% 为测试数据。
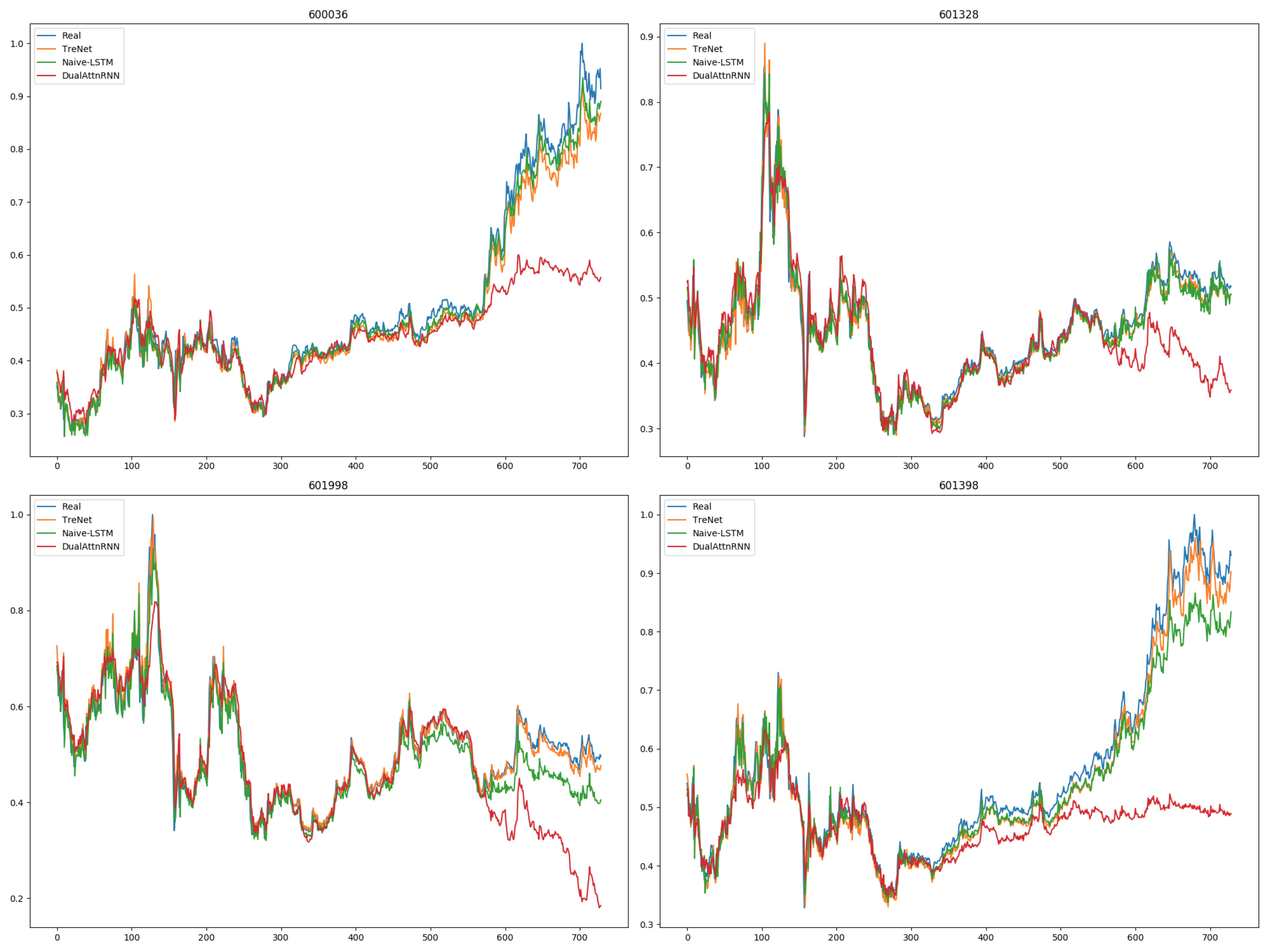 对 4 只银行股的价格预测实验。(测试集)
对 4 只银行股的价格预测实验。(测试集)
需求
在开始测试之前,需要满足以下要求。
- Python 3.5
- TensorFlow 1.4
- numpy
- scipy
- pandas
- rqalpha
- sklearn
- tushare
- matplotlib
- mongoengine
- CUDA(可选)
- ta-lib(可选)
- Docker(可选)
- PyTorch(可选)
建议使用 Docker,这样可以避免手动安装所有依赖项,直接运行整个项目。
此外,您还可以使用 Ansible 运行 CUDA-Playbook 和 Docker-Playbook,以安装 CUDA 和 Nvidia-Docker,从而在 Docker 容器中运行测试。
使用方法
如果您使用 Docker
关于基础镜像
该项目的基础镜像是 ceruleanwang/personae,而 personae 继承自 ceruleanwang/quant-base。
镜像 ceruleanwang/quant-base 继承自 nvidia/cuda:8.0-cudnn6-runtime。因此,请确保您的 CUDA 和 cuDNN 版本正确。
指令
首先,您需要确保 MongoDB 中已存储股票数据。
如果没有,您可以使用本项目中的爬虫来抓取股票或期货数据,但在开始之前,务必确保 MongoDB 服务正在运行。
如果 MongoDB 服务未运行,您也可以通过以下命令启动一个 MongoDB 容器(可选):
docker run -p 27017:27017 -v /data/db:/data/db -d --network=your_network mongo
然后,您可以使用爬虫抓取股票数据,命令如下:
docker run -t -v local_project_dir:docker_project_dir --network=your_network ceruleanwang/personae spider/stock_spider.py
同样,您也可以使用以下命令抓取期货数据:
docker run -t -v local_project_dir:docker_project_dir --network=your_network ceruleanwang/personae spider/future_spider.py
请注意设置您想要抓取的股票或期货代码,默认的股票代码是:
stock_codes = ["600036", "601328", "601998", "601398"]
默认的期货代码是:
future_codes = ["AU88", "RB88", "CU88", "AL88"]
这些代码可以在以下文件中修改:
之后,您只需运行模型即可:
docker run -t -v local_project_dir:docker_project_dir --network=yuor_network ceruleanwang/personae algorithm/RL 或 SL/algorithm_name.py
如果您使用 Conda
您可以自行创建一个环境,安装 Python 3.5 及所有所需依赖项,然后按照自己的方式运行算法。
需要注意的是,在 mongoengine 的配置中,hostname 必须设置为您自己的。
关于训练与测试
目前,所有使用 TensorFlow 实现的模型都支持持久化。在训练或测试模型时,您可以修改许多参数。 例如,以下代码展示了一些可以被修改的参数:
env = Market(codes, start_date="2008-01-01", end_date="2018-01-01", **{
"market": market,
"mix_index_state": True,
"training_data_ratio": training_data_ratio,
})
algorithm = Algorithm(tf.Session(config=config), env, env.trader.action_space, env.data_dim, **{
"mode": mode,
"episodes": episode,
"enable_saver": True,
"enable_summary_writer": True,
"save_path": os.path.join(CHECKPOINTS_DIR, "RL", model_name, market, "model"),
"summary_path": os.path.join(CHECKPOINTS_DIR, "RL", model_name, market, "summary"),
})
待办事项
- 更多论文的实现。
- 更多高频股票数据。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。
crawl4ai
Crawl4AI 是一款专为大语言模型(LLM)设计的开源网络爬虫与数据提取工具。它的核心使命是将纷繁复杂的网页内容转化为干净、结构化的 Markdown 格式,直接服务于检索增强生成(RAG)、智能体构建及各类数据管道,让 AI 能更轻松地“读懂”互联网。 传统爬虫往往面临反爬机制拦截、动态内容加载困难以及输出格式杂乱等痛点,导致后续数据处理成本高昂。Crawl4AI 通过内置自动化的三级反机器人检测、代理升级策略以及对 Shadow DOM 的深度支持,有效突破了这些障碍。它能智能移除同意弹窗,处理深层链接,并具备长任务崩溃恢复能力,确保数据采集的稳定与高效。 这款工具特别适合开发者、AI 研究人员及数据工程师使用。无论是需要为本地模型构建知识库,还是搭建大规模自动化信息采集流程,Crawl4AI 都提供了极高的可控性与灵活性。作为 GitHub 上备受瞩目的开源项目,它完全免费开放,无需繁琐的注册或昂贵的 API 费用,让用户能够专注于数据价值本身而非采集难题。
meilisearch
Meilisearch 是一个开源的极速搜索服务,专为现代应用和网站打造,开箱即用。它能帮助开发者快速集成高质量的搜索功能,无需复杂的配置或额外的数据预处理。传统搜索方案往往需要大量调优才能实现准确结果,而 Meilisearch 内置了拼写容错、同义词识别、即时响应等实用特性,并支持 AI 驱动的混合搜索(结合关键词与语义理解),显著提升用户查找信息的体验。 Meilisearch 特别适合 Web 开发者、产品团队或初创公司使用,尤其适用于需要快速上线搜索功能的场景,如电商网站、内容平台或 SaaS 应用。它提供简洁的 RESTful API 和多种语言 SDK,部署简单,资源占用低,本地开发或生产环境均可轻松运行。对于希望在不依赖大型云服务的前提下,为用户提供流畅、智能搜索体验的团队来说,Meilisearch 是一个高效且友好的选择。
Made-With-ML
Made-With-ML 是一个面向实战的开源项目,旨在帮助开发者系统掌握从设计、开发到部署和迭代生产级机器学习应用的完整流程。它解决了许多人在学习机器学习时“会训练模型但不会上线”的痛点,强调将软件工程最佳实践与 ML 技术结合,构建可靠、可维护的端到端系统。 该项目特别适合三类人群:一是希望将模型真正落地的开发者(包括软件工程师、数据科学家);二是刚毕业、想补齐工业界所需技能的学生;三是需要理解技术边界以更好推动产品的技术管理者或产品经理。 Made-With-ML 的亮点在于注重第一性原理讲解,避免盲目调包;同时覆盖 MLOps 关键环节(如实验跟踪、模型测试、服务部署、CI/CD 等),并支持在 Python 生态内平滑扩展训练与推理任务,无需切换语言或复杂基础设施。课程内容结构清晰,配有详细代码示例和视频导览,兼顾理论深度与工程实用性。