OpenMemory
OpenMemory 是一个专为大语言模型(LLM)和智能体设计的认知记忆引擎。它旨在解决 AI 应用普遍存在的“失忆”问题,让模型拥有真实的长期记忆,而不仅仅是依赖传统的向量数据库或 RAG 技术。通过 OpenMemory,开发者可以让无状态的模型记住用户偏好、历史对话及关键上下文,使应用不再“健忘”。
OpenMemory 非常适合构建 AI 应用的开发者使用,支持 Python 和 Node.js 环境。它采用本地优先架构,支持 SQLite 或 Postgres 自托管,确保数据隐私与控制权。OpenMemory 提供了丰富的集成方案,可无缝对接 LangChain、CrewAI、AutoGen 等主流框架,甚至能作为 VS Code 插件或 Claude Desktop 的本地记忆存储。
技术亮点方面,OpenMemory 不仅支持记忆的可解释性追踪,让用户了解为何特定信息被召回,还内置了 GitHub、Notion、Google Drive 等多种数据连接器,方便直接导入外部知识。无论是构建个人智能助手还是企业级多用户记忆系统,OpenMemory 都能提供灵活且持久的记忆支持。
使用场景
某软件开发团队在构建AI代码助手时,需要让模型记住每个开发者的个性化编码习惯和项目特定规则。
没有 OpenMemory 时
- 开发者每次重启IDE都要重新输入缩进风格、命名规范等偏好设置
- 跨设备使用时(如从MacBook切换到公司PC)需要手动同步配置文件
- 团队协作时无法共享项目专属的代码模板和架构约束
- 模型无法记住历史对话中的特殊约定(如特定业务术语的缩写规则)
- 需要为每个项目维护独立的配置文件,导致管理复杂度指数级上升
使用 OpenMemory 后
- 开发者首次设置的编码偏好(如Python的PEP8严格模式)自动持久化存储
- 通过用户ID关联,跨设备使用VS Code时自动同步个性化配置
- 团队共享的项目记忆库自动记录架构决策(如"订单服务采用CQRS模式")
- 历史对话中的特殊约定(如"CRM模块用user代替customer")被自动关联到代码上下文
- 通过标签系统统一管理多项目配置,SDK自动根据当前工作目录匹配对应记忆
核心价值:OpenMemory让AI代码助手具备持续记忆能力,开发者只需设置一次即可跨设备、跨会话、跨项目保持个性化体验,团队知识自动沉淀为可复用的智能资产。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
🚧 本项目目前正在全面重写中
预计会出现破坏性变更和潜在Bug。
如发现任何问题,请提交GitHub Issue并附上详细信息,以便跟踪和修复。
OpenMemory
为AI代理提供真正的长期记忆。不是RAG,不是向量数据库。支持自托管,基于Python + Node。




OpenMemory是一个面向大型语言模型(LLM)和代理的认知内存引擎。
- 🧠 真正的长期记忆(不只是表中的嵌入向量)
- 💾 自托管,本地优先(支持SQLite/Postgres)
- 🐍 Python + 🟦 Node SDK
- 🧩 集成:LangChain、CrewAI、AutoGen、Streamlit、MCP、VS Code
- 📥 数据源:GitHub、Notion、Google Drive、OneDrive、网络爬虫
- 🔍 可解释的检索轨迹(查看记忆被召回的原因)
你的模型保持无状态。你的应用不再失忆。
☁️ 一键部署
快速启动共享的OpenMemory后端(包含HTTP API + MCP + 仪表盘):



当需要嵌入式本地内存时使用SDK,当需要多用户组织级内存时使用服务器。
1. TL;DR – 10秒快速上手
🐍 Python(本地优先)
安装:
pip install openmemory-py
使用:
from openmemory.client import Memory
mem = Memory()
mem.add("用户偏好深色模式", user_id="u1")
results = mem.search("偏好设置", user_id="u1")
await mem.delete("memory_id")
注意:
add、search、get、delete是异步方法。在异步上下文中使用await。
🔗 OpenAI
mem = Memory()
client = mem.openai.register(OpenAI(), user_id="u1")
resp = client.chat.completions.create(...)
🧱 LangChain
from openmemory.integrations.langchain import OpenMemoryChatMessageHistory
history = OpenMemoryChatMessageHistory(memory=mem, user_id="u1")
🤝 CrewAI / AutoGen / Streamlit
OpenMemory专为代理框架和UI提供底层支持:
- Crew风格代理:使用
Memory作为共享长期存储 - AutoGen风格编排:将对话和工具调用存储为情景记忆
- Streamlit应用:通过
user_id为每个用户提供持久化内存
具体集成模式请参阅文档中的集成章节。
🟦 Node / JavaScript(本地优先)
安装:
npm install openmemory-js
使用:
import { Memory } from "openmemory-js"
const mem = new Memory()
await mem.add("用户喜欢辣食", { user_id: "u1" })
const results = await mem.search("食物偏好", { user_id: "u1" })
await mem.delete("memory_id")
适用于以下场景:
- Node后端
- 命令行工具
- 本地工具
- 需要持久化内存但不想运行独立服务的场景
📥 数据连接器
直接从外部数据源导入数据到内存:
# python
github = mem.source("github")
await github.connect(token="ghp_...")
await github.ingest_all(repo="owner/repo")
// javascript
const github = await mem.source("github")
await github.connect({ token: "ghp_..." })
await github.ingest_all({ repo: "owner/repo" })
支持的数据连接器:github、notion、google_drive、google_sheets、google_slides、onedrive、web_crawler
2. 运行模式:SDK、服务器、MCP
OpenMemory可以内嵌运行在应用中,也可以作为中心化服务运行。
2.1 Python SDK
- ✅ 默认使用本地SQLite
- ✅ 支持外部数据库(通过配置)
- ✅ 适合LangChain / LangGraph / CrewAI / 笔记本使用
文档:https://openmemory.cavira.app/docs/sdks/python
2.2 Node SDK
- 与Python相同认知模型
- 适合JS/TS应用
- 可本地运行或连接中心化后端
文档:https://openmemory.cavira.app/docs/sdks/javascript
2.3 后端服务器(多用户 + 仪表盘 + MCP)
适用于需要以下功能的场景:
- 组织级内存
- HTTP API
- 仪表盘
- 支持Claude / Cursor / Windsurf的MCP服务
从源码运行:
git clone https://github.com/CaviraOSS/OpenMemory.git
cd OpenMemory
cp .env.example .env
cd backend
npm install
npm run dev # 默认监听8080端口
或使用Docker(API + MCP):
docker compose up --build -d
可选:启用仪表盘服务:
docker compose --profile ui up --build -d
使用Doppler管理配置(推荐用于托管仪表盘/API的URL):
cd OpenMemory
tools/ops/compose_with_doppler.sh up -d --build
检查服务状态:
docker compose ps
curl -f http://localhost:8080/health
后端暴露以下接口:
/api/memory/*– 内存操作接口/api/temporal/*– 时序知识图谱/mcp– MCP服务- 仪表盘UI(启用
ui配置时)
3. 为什么选择OpenMemory(对比RAG,对比"纯向量"方案)
LLM在消息间会遗忘所有状态。
大多数"记忆"方案本质上只是RAG流水线:
- 文本被切分
- 转换为向量存储
- 通过相似度检索
它们无法理解:
- 某条信息是事实、事件、偏好还是情感
- 其时效性/重要性
- 与其他记忆的关联
- 特定时间点的真值状态
云服务记忆API带来:
- 供应商锁定
- 延迟问题
- 不透明的行为
- 隐私风险
OpenMemory为你提供真正的记忆系统:
- 🧠 多区域记忆(情景、语义、程序、情感、反思)
- ⏱ 时序推理(知晓特定时间的真值状态)
- 📉 衰减与强化机制(替代简单的TTL)
- 🕸 路标图(可遍历的关联链接)
- 🔍 可解释的检索轨迹(查看被召回的节点及其原因)
- 🏠 自托管,本地优先,数据完全可控
- 🔌 SDK + 服务器 + VS Code + MCP
它表现得像一个真正的内存模块,而非"加了营销文案的向量数据库"。
4. 传统方式 vs OpenMemory
Vector DB + LangChain(重度云依赖,流程繁琐):
import os
import time
from langchain.chains import ConversationChain
from langchain.memory import VectorStoreRetrieverMemory
from langchain_community.vectorstores import Pinecone
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ["PINECONE_API_KEY"] = "sk-..."
os.environ["OPENAI_API_KEY"] = "sk-..."
time.sleep(3) # 云端预热
embeddings = OpenAIEmbeddings()
pinecone = Pinecone.from_existing_index(embeddings, index_name="my-memory")
retriever = pinecone.as_retriever(search_kwargs={"k": 2})
memory = VectorStoreRetrieverMemory(retriever=retriever)
conversation = ConversationChain(llm=ChatOpenAI(), memory=memory)
conversation.predict(input="I'm allergic to peanuts")
OpenMemory(3行代码,本地文件,无厂商锁定):
from openmemory.client import Memory
mem = Memory()
mem.add("user allergic to peanuts", user_id="user123")
results = mem.search("allergies", user_id="user123")
✅ 零云配置 • ✅ 本地SQLite • ✅ 支持离线 • ✅ 自主数据库,自主架构
5. 核心功能概览
多维度内存
情景记忆(事件)、语义记忆(事实)、程序记忆(技能)、情感记忆(感受)、反思记忆(洞察)。时间知识图谱(Temporal knowledge graph)
valid_from/valid_to时间窗口,时点真相,随时间演进。复合评分机制
显著度+时效性+共激活度,不局限于余弦距离。衰减引擎
按维度自适应遗忘,替代硬性TTL设置。可解释召回
通过"航路点(waypoint)"追踪显示上下文使用的具体节点。嵌入支持
兼容OpenAI、Gemini、Ollama、AWS,支持合成回退。集成能力
支持LangChain、CrewAI、AutoGen、Streamlit、MCP、VS Code等IDE。数据连接器
支持从GitHub、Notion、Google Drive、Google表格/幻灯片、OneDrive、网络爬虫导入数据。迁移工具
支持从Mem0、Zep、Supermemory等迁移记忆数据。
若您正在开发智能代理、协作助手、日志系统、知识工作者或编程助手,OpenMemory能让这些系统从"金鱼记忆"升级为真正具备记忆能力的智能体。
6. MCP与IDE工作流
OpenMemory内置原生MCP服务器,任何支持MCP的客户端均可将其作为工具使用。
Claude / Claude Code
claude mcp add --transport http openmemory http://localhost:8080/mcp
Cursor / Windsurf
.mcp.json配置:
{
"mcpServers": {
"openmemory": {
"type": "http",
"url": "http://localhost:8080/mcp"
}
}
}
支持的工具包括:
openmemory_queryopenmemory_storeopenmemory_listopenmemory_getopenmemory_reinforce
您的IDE助手可直接查询、存储、列举和强化记忆,无需手动编写每个调用。
7. 时间知识图谱
OpenMemory将时间作为核心维度处理。
核心概念
valid_from/valid_to- 真值时间窗口- 自动演进 - 新事实自动闭合旧记录
- 置信衰减 - 旧事实渐进式失效
- 时点查询 - "X时间点什么为真?"
- 时间线 - 重建实体历史
- 变更检测 - 识别状态变更时间点
示例
POST /api/temporal/fact
{
"subject": "CompanyX",
"predicate": "has_CEO",
"object": "Alice",
"valid_from": "2021-01-01"
}
后续更新:
POST /api/temporal/fact
{
"subject": "CompanyX",
"predicate": "has_CEO",
"object": "Bob",
"valid_from": "2024-04-10"
}
Alice的任期自动闭合,时间线查询保持逻辑完整。
8. 命令行工具(opm)
opm命令行工具可直接与引擎/服务器通信。
安装
cd packages/openmemory-js
npm install
npm run build
npm link # 将`opm`添加到系统路径
使用示例
# 启动API服务器
opm serve
# 新终端中:
opm health
opm add "Recall that I prefer TypeScript over Python" --tags preference
opm query "language preference"
支持命令
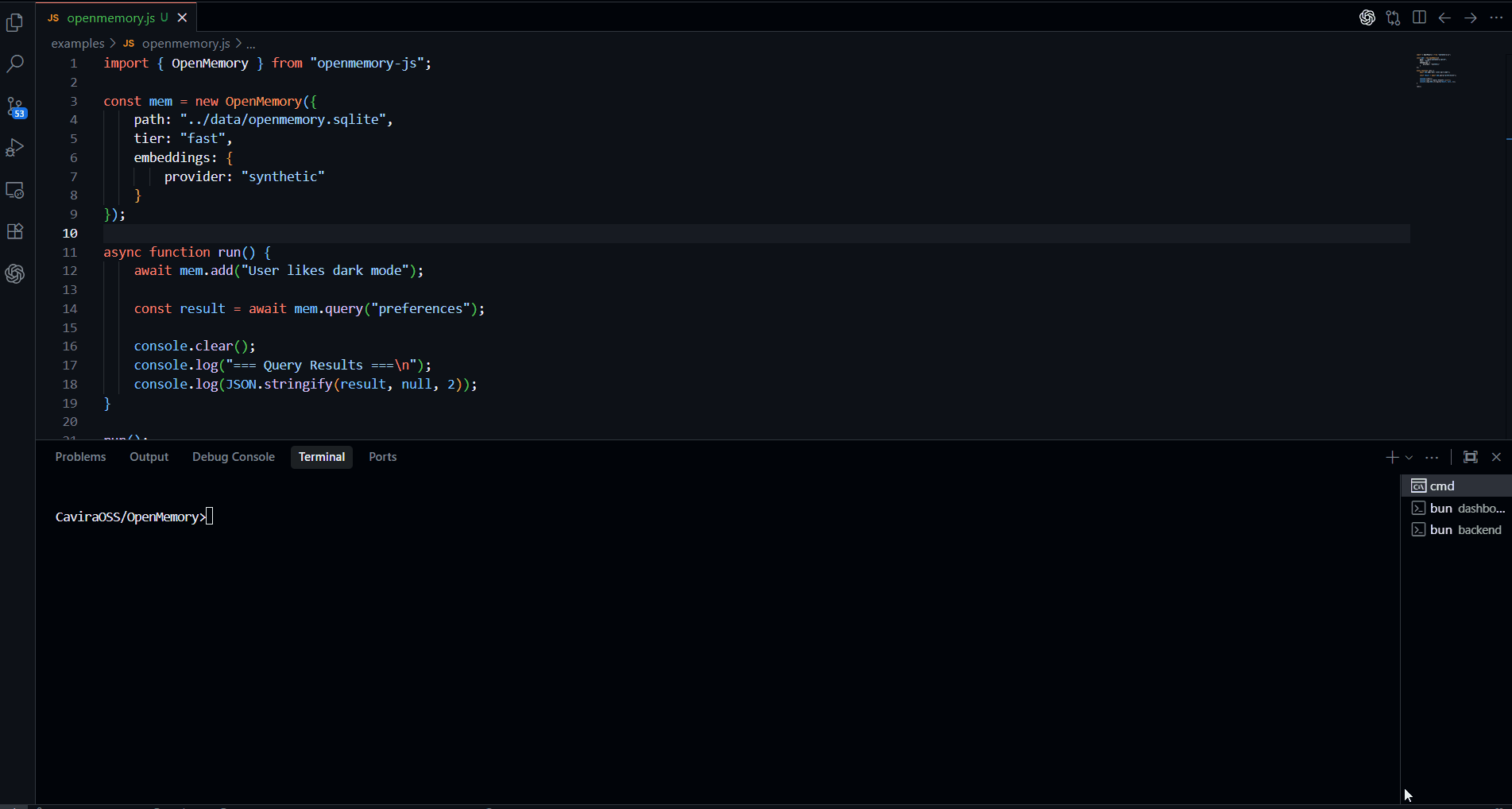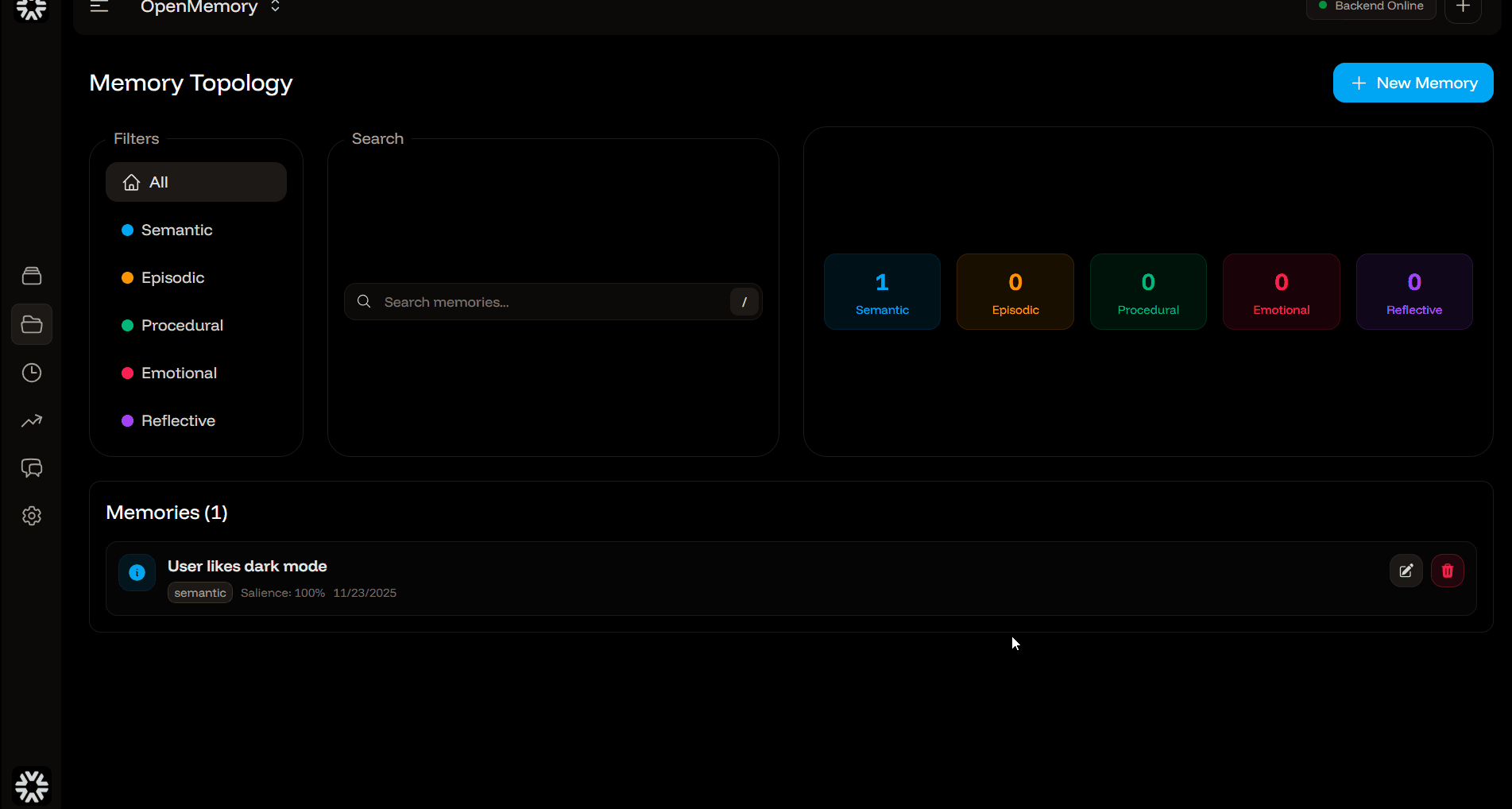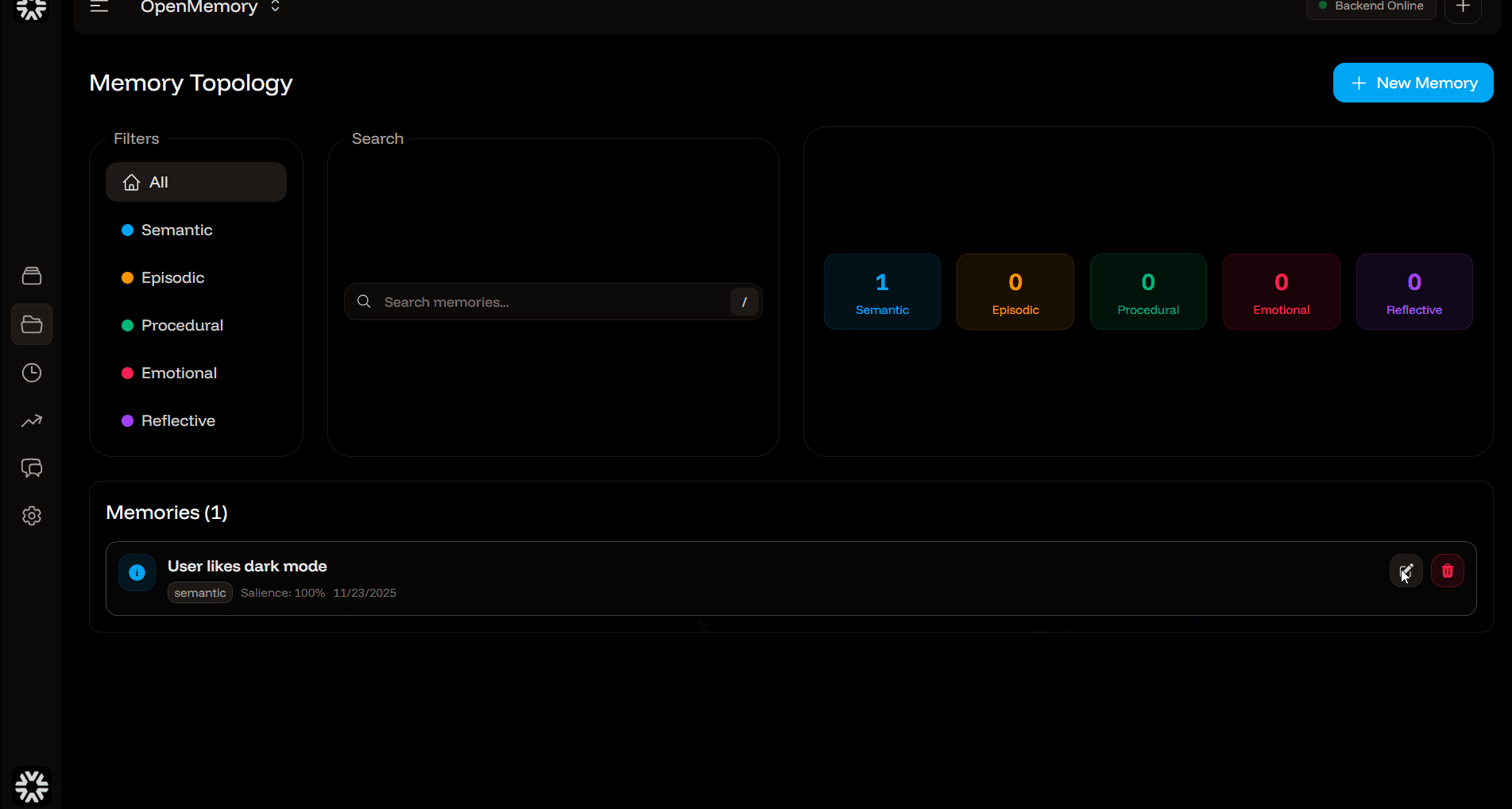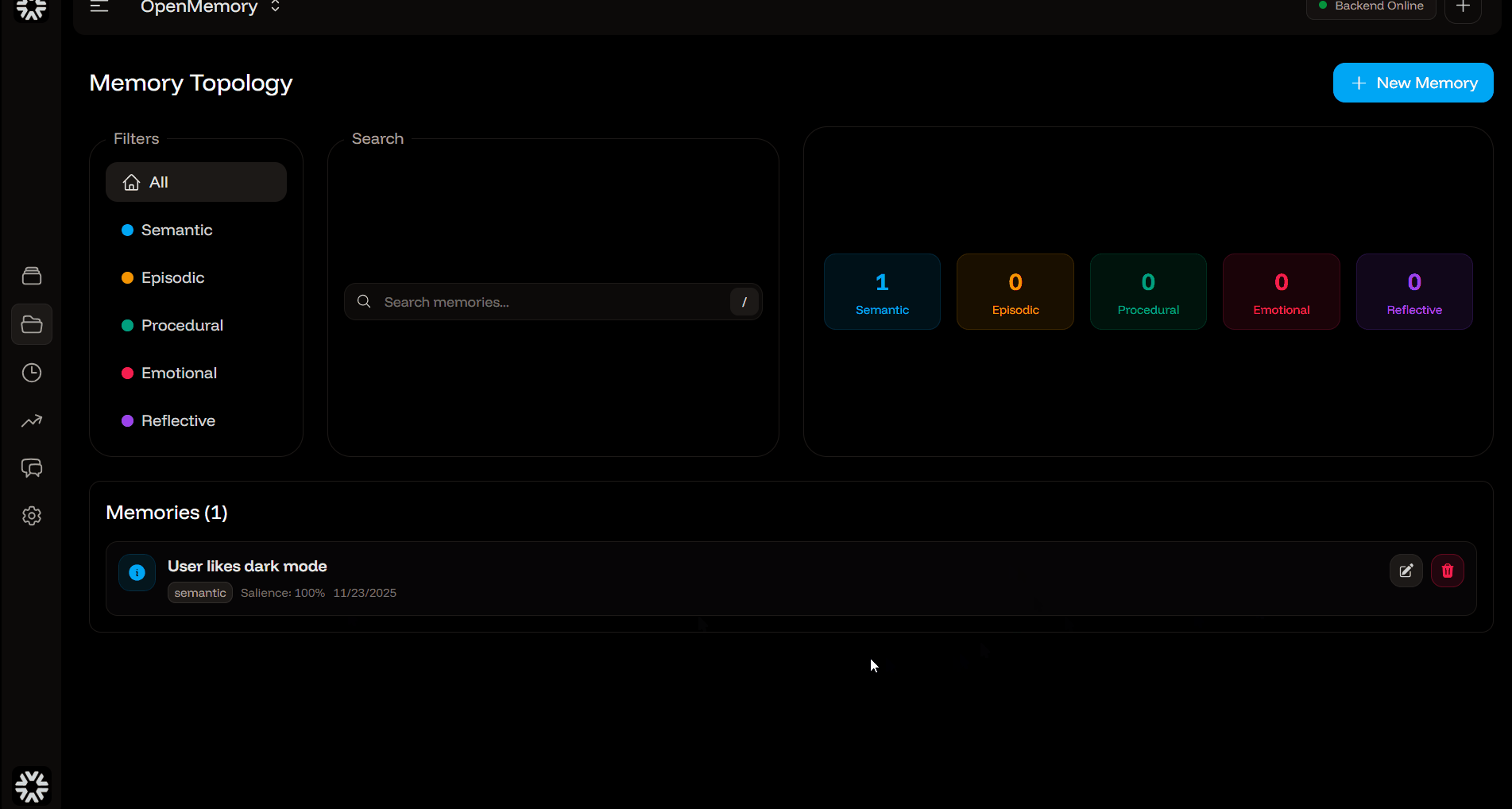
opm add "user prefers dark mode" --user u1 --tags prefs
opm query "preferences" --user u1 --limit 5
opm list --user u1
opm delete <id>
opm reinforce <id>
opm stats
适用于脚本编写、调试及非LLM流水线的记忆管理。
9. 架构设计(高层视图)
OpenMemory采用**分层内存分解(Hierarchical Memory Decomposition)**架构,叠加时间图谱层。
graph TB
classDef inputStyle fill:#eceff1,stroke:#546e7a,stroke-width:2px,color:#37474f
classDef processStyle fill:#e3f2fd,stroke:#1976d2,stroke-width:2px,color:#0d47a1
classDef sectorStyle fill:#fff3e0,stroke:#f57c00,stroke-width:2px,color:#e65100
classDef storageStyle fill:#fce4ec,stroke:#c2185b,stroke-width:2px,color:#880e4f
classDef engineStyle fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px,color:#4a148c
classDef outputStyle fill:#e8f5e9,stroke:#388e3c,stroke-width:2px,color:#1b5e20
classDef graphStyle fill:#e1f5fe,stroke:#0277bd,stroke-width:2px,color:#01579b
INPUT[输入 / 查询]:::inputStyle
CLASSIFIER[维度分类器]:::processStyle
EPISODIC[情景记忆]:::sectorStyle
SEMANTIC[语义记忆]:::sectorStyle
PROCEDURAL[程序记忆]:::sectorStyle
EMOTIONAL[情感记忆]:::sectorStyle
REFLECTIVE[反思记忆]:::sectorStyle
EMBED[嵌入引擎]:::processStyle
SQLITE[(SQLite/Postgres<br/>记忆数据 / 向量 / 航路点)]:::storageStyle
TEMPORAL[(时间图谱)]:::storageStyle
subgraph RECALL_ENGINE["召回引擎"]
VECTOR[向量搜索]:::engineStyle
WAYPOINT[航路点图]:::engineStyle
SCORING[复合评分]:::engineStyle
DECAY[衰减引擎]:::engineStyle
end
subgraph TKG["时间知识图谱"]
FACTS[事实存储]:::graphStyle
TIMELINE[时间线]:::graphStyle
end
CONSOLIDATE[整合处理]:::processStyle
REFLECT[反思处理]:::processStyle
OUTPUT[召回结果 + 追踪]:::outputStyle
INPUT --> CLASSIFIER
CLASSIFIER --> EPISODIC
CLASSIFIER --> SEMANTIC
CLASSIFIER --> PROCEDURAL
CLASSIFIER --> EMOTIONAL
CLASSIFIER --> REFLECTIVE
EPISODIC --> EMBED
SEMANTIC --> EMBED
PROCEDURAL --> EMBED
EMOTIONAL --> EMBED
REFLECTIVE --> EMBED
EMBED --> SQLITE
EMBED --> TEMPORAL
SQLITE --> VECTOR
SQLITE --> WAYPOINT
SQLITE --> DECAY
TEMPORAL --> FACTS
FACTS --> TIMELINE
VECTOR --> SCORING
WAYPOINT --> SCORING
DECAY --> SCORING
TIMELINE --> SCORING
SCORING --> CONSOLIDATE
CONSOLIDATE --> REFLECT
REFLECT --> OUTPUT
OUTPUT -.->|强化| WAYPOINT
OUTPUT -.->|显著度| DECAY
10. 数据迁移
OpenMemory提供迁移工具支持从其他记忆系统导入数据。
支持来源:
- Mem0
- Zep
- Supermemory
示例命令:
cd migrate
python -m migrate --from zep --api-key ZEP_KEY --verify
(详见migrate/目录及文档中各提供商的具体命令)
11. 路线图
- 🧬 可学习的扇区分类器(可在您的数据上训练)
- 🕸 联邦学习/集群内存节点(Federated / clustered memory nodes)
- 🤝 更深入的 LangGraph / CrewAI / AutoGen 集成
- 🔭 内存可视化工具 2.0
- 🔐 可插拔的静态加密(Pluggable encryption at rest)
点击 Star 关注项目进展。
12. 贡献指南
欢迎提交问题反馈和 Pull Request。
- Bug 反馈: https://github.com/CaviraOSS/OpenMemory/issues
- 功能请求: 使用 GitHub 问题模板
- 进行重大更改前,请先发起讨论或提交小型设计 PR
13. 许可证
OpenMemory 采用 Apache 2.0 许可证。详情请参阅 LICENSE 文件。
版本历史
v1.3.02025/12/20v1.2.32025/12/12v1.2.22025/12/061.2.12025/11/231.2.02025/11/051.1.12025/10/301.1.02025/10/261.0.02025/10/26常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。