MemAgent
MemAgent 是一款专为处理超长文本上下文而设计的开源框架,旨在让大语言模型在不改变底层架构的前提下,轻松应对从几千字到数百万字的巨量信息。它主要解决了传统模型受限于固定上下文窗口、难以处理长文档且计算成本高昂的痛点。通过引入创新的多轮卷积强化学习(Multi-Conv RL)机制,MemAgent 能够以线性时间复杂度高效处理任意长度的输入,实现了从 8K 训练长度向 350 万 token 任务的神奇“外推”,且在极长语境下性能损失极低。
这一工具特别适合 AI 研究人员、大模型开发者以及需要处理长篇法律文档、学术著作或复杂代码库的技术团队使用。其核心亮点在于无需重新设计模型结构,仅通过端到端的强化学习训练,即可赋予模型卓越的长文记忆与理解能力。官方已开放 7B 和 14B 版本的模型权重,并提供了便捷的快速启动脚本,支持本地 vLLM 部署及在线服务集成,让用户能迅速体验在百万级 token 语境下进行高精度问答的强大功能。
使用场景
某法律科技团队需要构建一个智能系统,用于自动分析长达数百万字的跨国并购案卷(包含数十年间的合同、邮件及法庭记录),并从中提取关键风险点。
没有 MemAgent 时
- 上下文截断导致信息遗漏:传统大模型受限于固定窗口(如 128K),被迫对案卷进行切片处理,导致跨章节的关键证据链断裂,无法识别隐蔽的长期依赖关系。
- 检索增强生成(RAG)精度不足:依赖向量数据库检索片段时,常因语义匹配偏差丢失核心细节,且难以处理需要通读全文才能理解的复杂逻辑推理。
- 推理成本与延迟极高:为覆盖长文本需多次调用模型或堆叠计算资源,导致单次分析耗时数小时,无法满足业务实时性要求。
- 模型性能随长度急剧下降:现有长文本模型在处理超过训练长度(如从 32K 扩展到百万级)时,准确率大幅跳水,无法保证法律结论的可靠性。
使用 MemAgent 后
- 无损处理超长上下文:MemAgent 凭借独特的记忆机制,直接端到端处理 350 万字以上的完整案卷,无需切片即可捕捉跨越数十万 token 的关键线索。
- 端到端强化学习优化:通过多轮对话独立的 RL 训练,MemAgent 在 512K 甚至 3.5M 长度的测试中保持 95% 以上的准确率,精准定位深层风险。
- 线性扩展的计算效率:突破传统计算瓶颈,资源消耗随文本长度呈线性增长而非指数爆炸,将原本数小时的分析任务缩短至分钟级。
- 卓越的长度外推能力:即使在远超训练数据长度(从 32K 外推至 3.5M)的场景下,性能损失仍控制在 5% 以内,确保法律分析的严谨性。
MemAgent 通过强化学习驱动的记忆架构,彻底解决了超大篇幅文档分析中的信息断层与性能衰减难题,让全量上下文理解成为现实。
运行环境要求
- Linux
- 必需
- 基于 vLLM 部署,需 NVIDIA GPU
- 14B 模型示例命令使用 `--tensor_parallel_size 2`,暗示至少需要 2 张显卡或多卡并行以承载显存
- 具体显存需求未明确说明,但运行 3.5M token 上下文任务通常需要高显存(建议 80GB+ 总显存或量化版本)
未说明(建议大容量以支持长上下文数据处理)
快速开始



MemAgent:基于多轮强化学习的记忆智能体重塑长上下文大模型
[!IMPORTANT] 🔥 最新消息!!!
- [2025/07] 我们提供了一个快速入门脚本,让使用MemAgent变得极其简单,请参阅下方的快速入门部分。
- [2025/06] 我们发布了RL-MemAgent-14B和RL-MemAgent-7B模型,在350万 token 上下文的任务中实现了几乎无损的性能。
📖引言
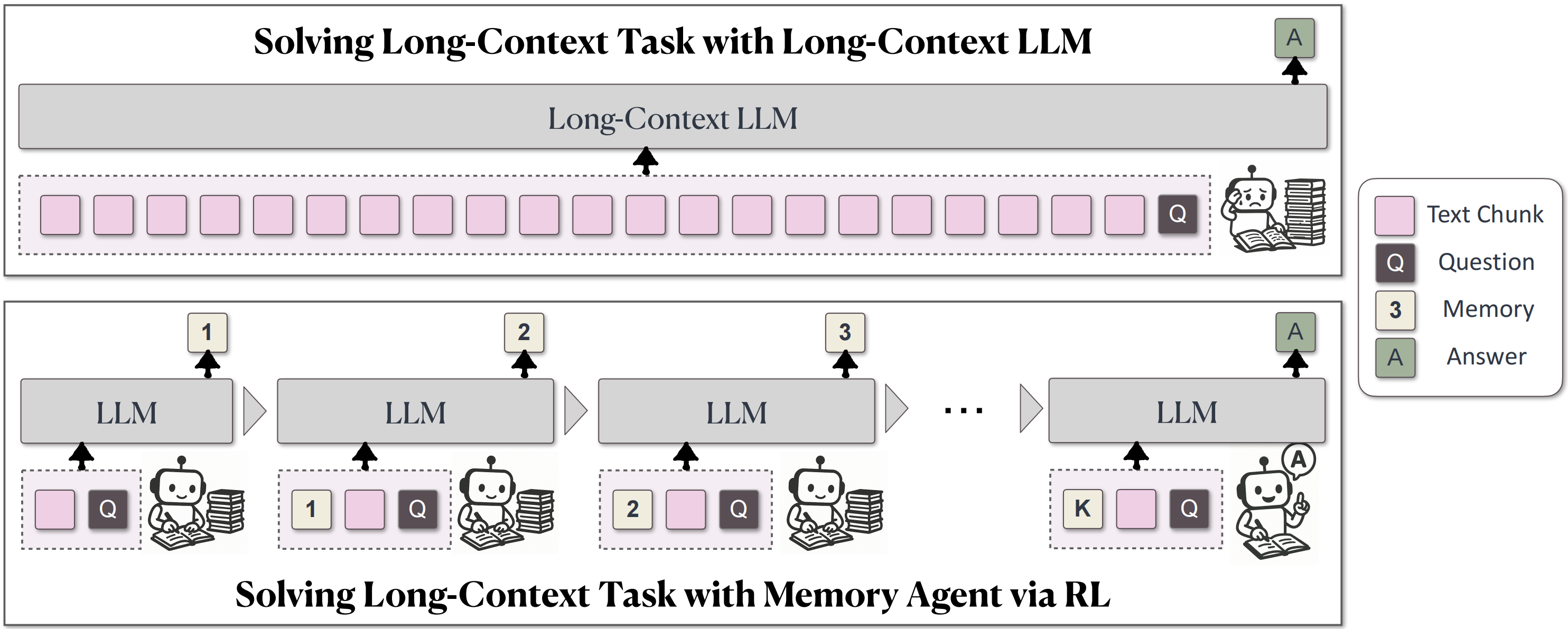
我们提出了一种全新的长上下文处理框架——MemAgent,它通过端到端的强化学习直接优化长上下文任务,而无需改变底层模型架构。MemAgent展现了卓越的长上下文能力,能够在3.5万文本上训练的8K上下文基础上,外推至350万的问答任务,性能损失低于5%,并在51.2万 RULER 测试中达到95%以上的准确率。
亮点:
- 🚀 新型记忆机制 引入了MemAgent架构,能够在固定上下文窗口内处理任意长度的输入,突破了传统上下文窗口长度的限制。
- ⚡ 线性时间复杂度 打破了长文本处理中的计算瓶颈,实现了资源消耗与文本长度的线性增长。
- 🎯 强化学习驱动的外推 通过MemAgent架构的强化学习训练,使模型能够在外推至更长文本时保持极低的性能下降。
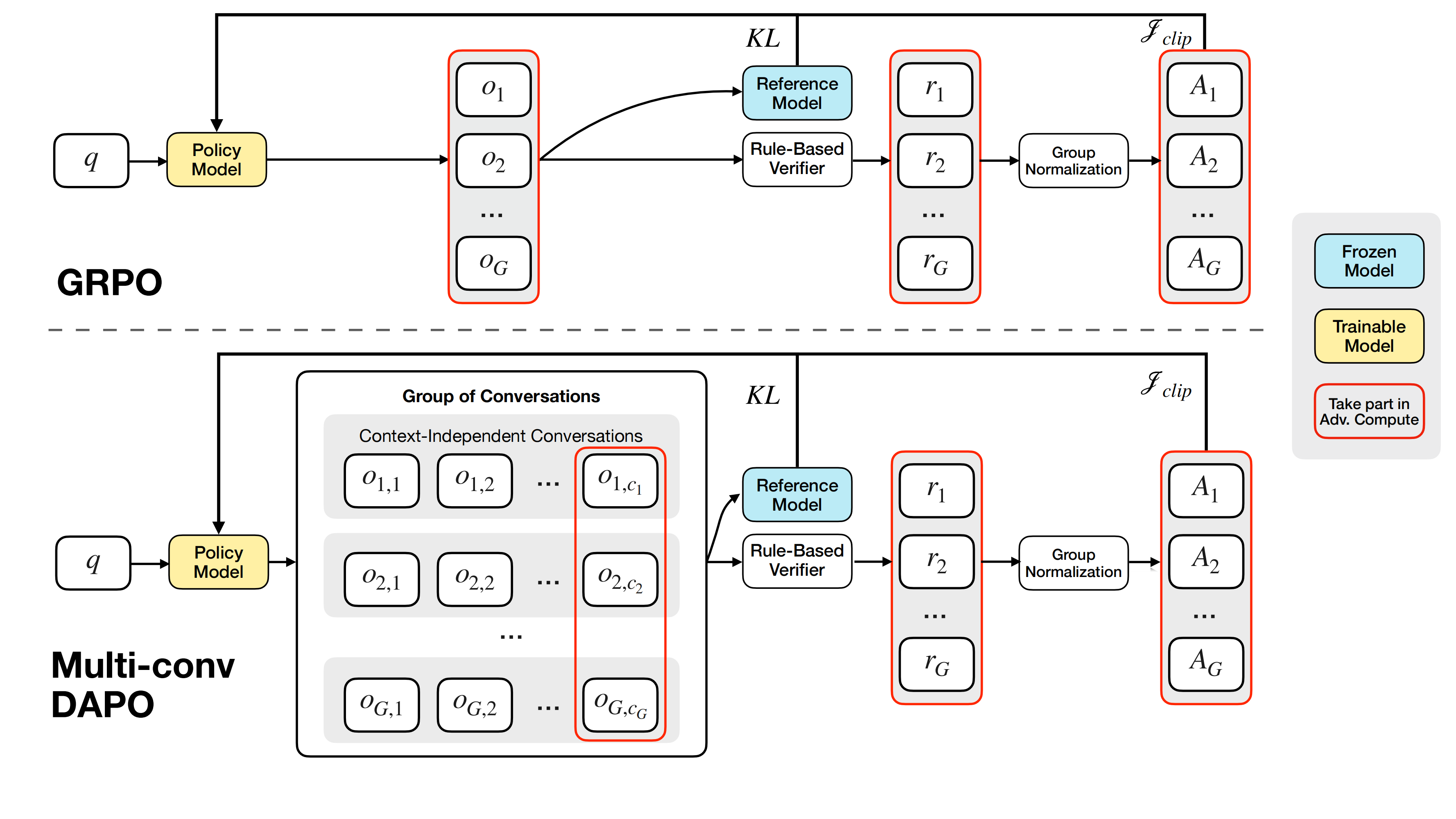
多轮强化学习框架
我们使用可验证奖励的强化学习(RLVR)来训练MemAgent,并扩展了DAPO算法,以支持多轮独立于上下文的对话中代理工作流的端到端优化。

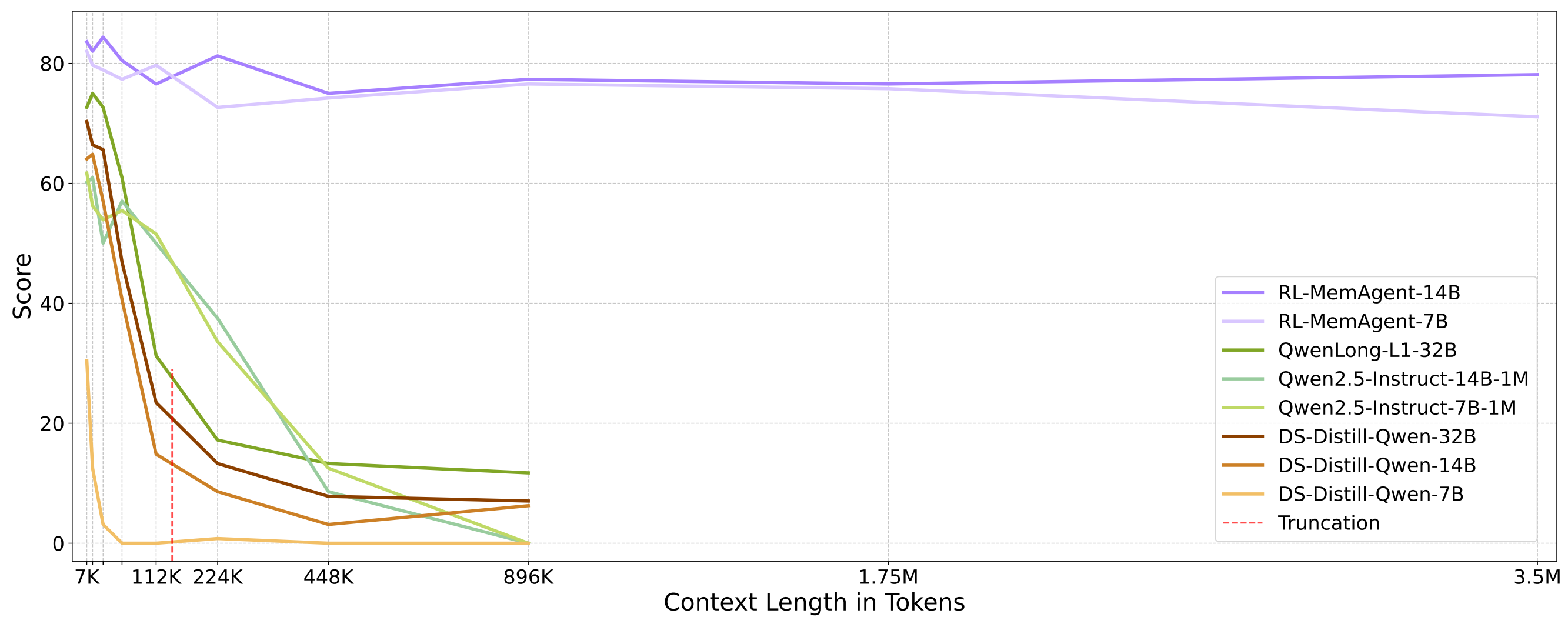
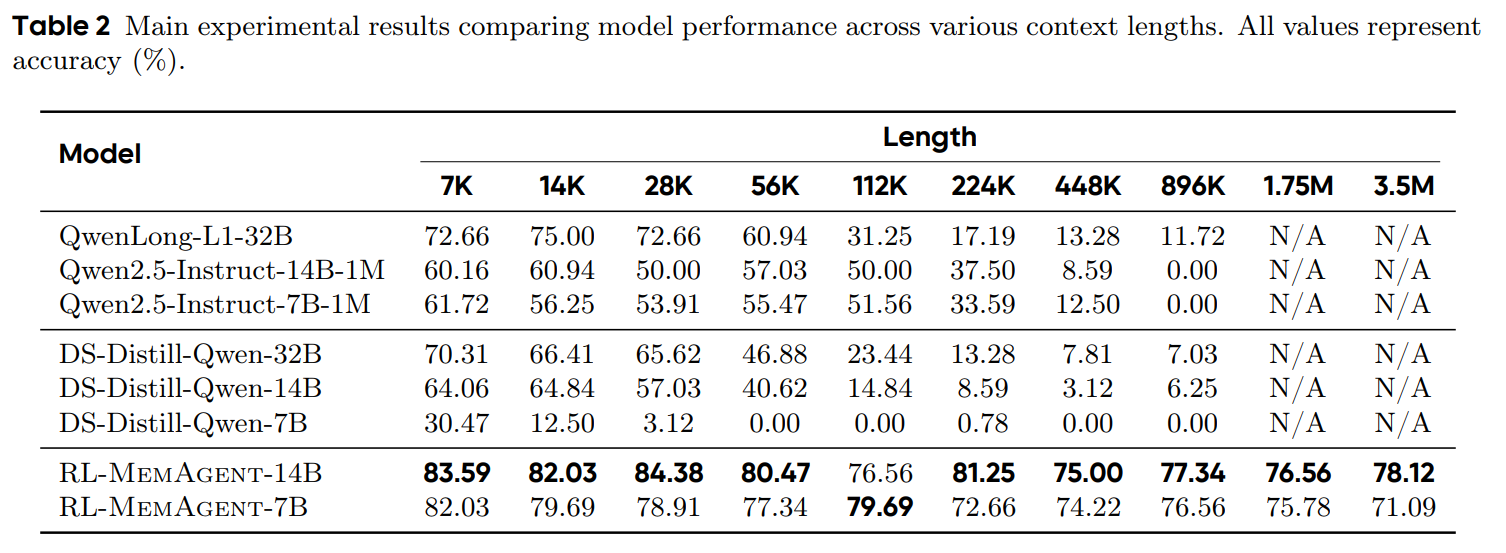
结果
RL-MemAgent在超长上下文处理中表现出色:
- 14B模型: 在350万 token 的任务中性能下降不到5.5%,实现了真正的无损外推。
- 7B模型: 在最长上下文中仅出现11%的性能下降,显著优于现有的长上下文模型。
快速入门
quickstart.py 提供了一种简单的方式来开始使用MemAgent,既支持本地部署,也支持与在线模型服务的集成。
vLLM 本地部署
启动
vllm服务器:vllm serve BytedTsinghua-SIA/RL-MemoryAgent-14B --tensor_parallel_size 2运行
quickstart.py:python quickstart.py --model BytedTsinghua-SIA/RL-MemoryAgent-14B
在线 LLM 服务
对于在线 LLM 服务,您需要将模型端点和 API 密钥配置为环境变量。
例如,gpt-4o-2024-11-20:
- 普通在线服务:只需使用
https://{endpoint}。 - Azure OpenAI:使用格式
https://{endpoint}/openai/deployments/gpt-4o-2024-11-20。
export URL=
export API_KEY=
python quickstart.py --model gpt-4o-2024-11-20
可重复性
性能
在复现过程中,您可能会发现训练过程中的验证分数与最终分数并不相同(约50% vs 80%)。这种现象是正常的,因为在训练时我们实际上使用了一个更为严格的验证器来防止奖励作弊,而在测试时则使用了一个较为宽松的验证器。具体来说:
在【训练验证器】(https://github.com/BytedTsinghua-SIA/MemAgent/blob/main/verl/utils/reward_score/hotpotqa.py)中,模型的答案必须放在
\boxed{}内,且大小写完全匹配,不得包含任何额外字符。
更为严格的训练验证器源自早期的数学相关强化学习工作,而较为宽松的测试验证器则符合Ruler和Qwen-Long等长上下文项目中的实践。
测试结果
pip install httpx==0.23.1 aiohttp -U ray[serve,default] vllm
- 准备 QA 数据
cd taskutils/memory_data
bash download_qa_dataset.sh
- 下载数据集
cd ../..
bash hfd.sh BytedTsinghua-SIA/hotpotqa --dataset --tool aria2c -x 10
export DATAROOT=$(pwd)/hotpotqa
- 准备模型
测试中使用的模型将从HuggingFace下载。然而,Qwen2.5-Instruct系列模型需要手动下载,并正确配置其config.json以激活YaRN。请按照【Qwen2.5-Instruct仓库】中的说明操作(https://huggingface.co/Qwen/Qwen2.5-7B-Instruct)
bash hfd.sh Qwen/Qwen2.5-7B-Instruct --tool aria2c -x 10
bash hfd.sh Qwen/Qwen2.5-14B-Instruct --tool aria2c -x 10
bash hfd.sh Qwen/Qwen2.5-32B-Instruct --tool aria2c -x 10
# 然后手动修改 config.json
export MODELROOT=/your/path/to/models # 切换到你的模型根目录,这个环境变量在 run.py 脚本中会被使用
mv Qwen2.5-7B-Instruct $MODELROOT/Qwen2.5-7B-Instruct-128K
mv Qwen2.5-14B-Instruct $MODELROOT/Qwen2.5-14B-Instruct-128K
mv Qwen2.5-32B-Instruct $MODELROOT/Qwen2.5-32B-Instruct-128K
- 运行
注意: 完成所有测试可能需要几天时间,你可以选择指定要运行的测试或模型。
cd taskutils/memory_eval
python run.py
注意: 该脚本会使用所有可用的 GPU 来服务模型。如果你有多个 GPU 节点,可以创建一个 Ray 集群,并在其中一个节点上运行该脚本。使用 SERVE_PORT 和 DASH_PORT 来指定 Ray 集群的端口。
cd taskutils/memory_eval
SERVE_PORT=8000 DASH_PORT=8265 python run.py # 这里的端口号是默认值,你可能需要根据你的 Ray 集群中的服务/仪表板端口进行调整
训练
首先,在 run_memory_7B.sh 和 run_memory_14B.sh 中指定 PROJ_ROOT(用于保存检查点)和 DATASET_ROOT(用于训练数据,应与测试时使用的数据相同)。
然后直接运行此脚本以启动单节点训练,或者正确配置 Ray 集群,并在集群中的某个节点上运行该脚本。
数据
请在 taskutils/memory_data 目录下执行本节中的以下命令。
cd taskutils/memory_data
pip install nltk pyyaml beautifulsoup4 html2text wonderwords tenacity fire
- 训练集与验证集划分:hotpotqa_train.parquet 和 hotpotqa_dev.parquet
- 下载 QA 数据集和合成数据,如果你已经在上一步下载过,则可跳过此步骤:
bash download_qa_dataset.sh
python processing.py # 数据处理,生成长上下文多跳 QA 合成数据
在本地部署 Qwen-7B(端口 8000)和 Qwen-7B-Instruct(端口 8001)
数据过滤
python filter.py -i hotpotqa_dev_process.parquet -o hotpotqa_dev_result --noresume
python filter.py -i hotpotqa_train_process.parquet -o hotpotqa_train_result --noresume
python3 filter2.py # 过滤掉那些无需任何上下文即可被 LLM 正确回答的样本:
2. 主任务:eval_{50|100|200|...}.json
export DATAROOT="your_dir_to_hotpotqa_dev.parquet"
python convert_to_eval.py # 将 `hotpotqa_dev` 转换为 `eval_200.json`
python different_docs_eval.py.py # 创建包含不同数量文档的评估数据集
3. OOD 任务:eval_{rulersubset}_{8192|16384|...}.json
export DATAROOT="your_dir_to_hotpotqa_dev.parquet"
python download_paulgraham_essay.py
bash download_qa_dataset.sh
bash ruler_data_prepare.sh
工程实现
同步模式:从工具调用到通用工作流
受 Search-R1 的启发,我们实现了一个支持独立上下文的通用多轮对话工作流框架。因此,上下文不再像原始的工具调用那样被限制为所有先前对话的拼接字符串。该框架使得我们可以以端到端的方式优化多步智能体。记忆智能体便是这一框架的一个示例,展示了如何利用强化学习来优化智能体在多步工作流中的表现。
具体实现细节请参见 recurrent/impls/memory.py,接口设计则可在 recurrent/interface.py 和 recurrent/generation_manager.py 中找到。
异步模式:将智能体作为函数
基于 服务器模式下的生成,我们进一步实现了一个全新的框架,允许用户以类似于 OpenAI API 的方式调用 LLM 来实现智能体功能,而无需担心分批张量操作,如分词、填充、状态追踪等,这些通常需要大量的样板代码,甚至状态机。
在这种视角下,每个智能体都是一条返回一个或多个 {"role":"", "content":""} 字典列表的函数:
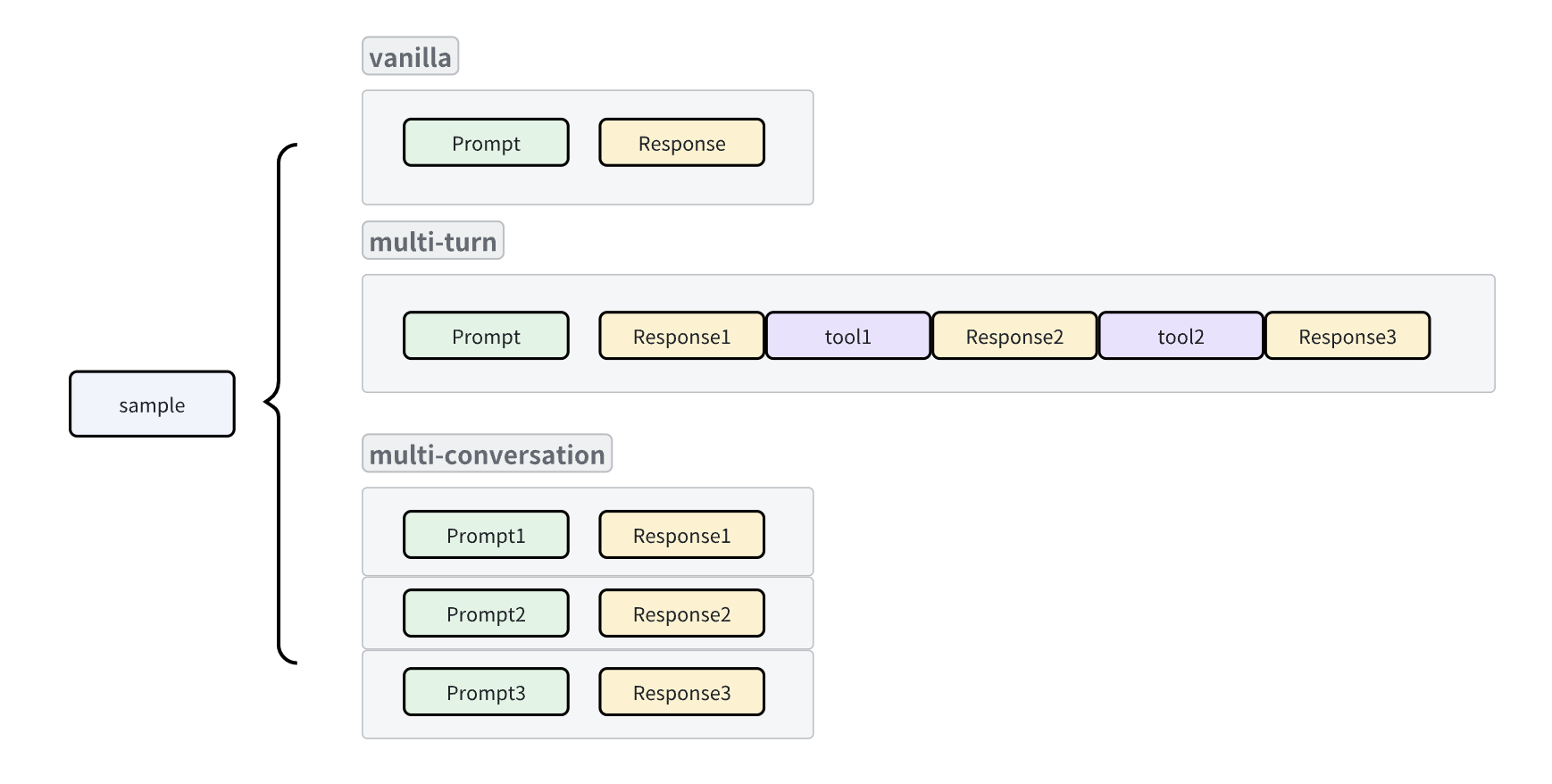
- 原生模式:
[{"role":"user","content":pmt},{"role":"assistant""content":rsp}] - 多轮工具调用模式:
[{"role":"user","content":pmt},{"role":"assistant","content":rsp1},{"role":"tool","content":obs},{"role":"assistant","content":rsp2}] - 上下文独立多轮对话模式:
[{"role":"user","content":pmt1},{"role":"assistant","content":rsp1}], [{"role":"user","content":pmt2},{"role":"assistant","content":rsp2}]
我们修改了 chat_template 以支持工具响应屏蔽,且无需任何张量操作。
更多详细信息请参见 recurrent/impls/async_*.py 中定义的智能体类的 rollout 方法实现,以及 recurrent/interface.py 和 recurrent/async_generation_manager.py 中的框架设计。
RayActor 进程池
计算密集型的奖励计算或工具调用可能会阻塞主节点向 LLM 发送生成请求。为了提高 CPU 密集型任务的效率,我们在每个节点上创建了一个 RayActor,运行一个进程池并接受来自主节点的任务。
因此,CPU 任务可以通过提交给 RayActor 来异步执行,GPU 任务(即 LLM 生成)也是如此。
更多详情请参见 verl/workers/reward_manager/thread.py。
致谢
我们感谢 verl 团队提供的灵活而强大的基础设施。
我们还感谢 服务器模式生成 的作者们所做的出色工作,他们的成果为我们构建异步智能体框架奠定了坚实的基础。
引用
如果你觉得这项工作对你有所帮助,请考虑引用我们的论文:
@article{yu2025memagent,
title={MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent},
author={Yu, Hongli and Chen, Tinghong and Feng, Jiangtao and Chen, Jiangjie and Dai, Weinan and Yu, Qiying and Zhang, Ya-Qin and Ma, Wei-Ying and Liu, Jingjing and Wang, Mingxuan and others},
journal={arXiv preprint arXiv:2507.02259},
year={2025}
}
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。