KoAlpaca
KoAlpaca 是一款专为韩语优化的开源大语言模型,旨在让 AI 精准理解并执行韩语指令。它基于斯坦福 Alpaca 的训练方法构建,核心解决了通用大模型在韩语语境下表现不佳、难以处理本土化任务的问题,填补了高质量韩语指令微调模型的空白。
该项目非常适合自然语言处理研究人员、AI 开发者以及希望探索韩语大模型应用的普通用户。对于开发者而言,KoAlpaca 提供了极高的灵活性与实用性:它不仅发布了基于 Polyglot-ko 和 LLaMA 等多个基座模型的版本,还详细公开了使用 QLoRA 技术在消费级显卡(如 RTX 3090/4090)甚至免费 Colab 环境中进行高效微调的代码与教程。这种低资源门槛的训练方案,使得个人研究者也能轻松参与韩语大模型的定制与开发。此外,项目曾提供网页聊天演示及机器人接口,方便用户直观体验其对话能力。作为韩语 AI 生态的重要基础设施,KoAlpaca 以开放共享的精神,推动了韩语自然语言处理技术的普及与创新。
使用场景
一家韩国初创公司的开发团队正致力于构建一个面向本土用户的智能客服系统,需要模型能够精准理解并生成自然的韩语回复。
没有 KoAlpaca 时
- 语言理解偏差大:直接调用通用的英文大模型或未经韩语微调的模型,导致对用户口语化、敬语体系复杂的韩语指令理解错误,回答生硬且充满“翻译腔”。
- 本地部署门槛高:想要获得更好的效果需训练超大参数模型,但团队缺乏多张高端 GPU(如 A100)集群资源,无法承担全量微调的巨大算力和时间成本。
- 定制开发周期长:缺乏现成的韩语指令遵循数据集和适配代码,从零收集数据、清洗并构建训练流水线耗时数周,严重拖慢产品上线进度。
- 推理成本高昂:在资源受限的服务器上运行未量化的高精度模型,显存占用过高,导致并发处理能力极低,难以支撑实际业务流量。
使用 KoAlpaca 后
- 韩语交互自然流畅:KoAlpaca 基于 Polyglot-ko 和 LLAMA 针对韩语深度微调,能准确识别韩国特有的敬语等级和文化语境,生成的回复地道且符合人类习惯。
- 低资源高效训练:利用 KoAlpaca 提供的 QLoRA 和 Tensor Parallel 示例代码,团队仅需单张消费级显卡(如 RTX 3090)或在免费 Colab T4 上即可完成 12.8B 大模型的适配训练。
- 开箱即用的生态支持:直接复用官方开放的 v1.1 数据集及预训练权重,结合 Hugging Face ChatUI 快速搭建演示环境,将原本数周的开发周期缩短至几天。
- 灵活部署降低成本:通过加载 4bit 或 8bit 量化版本的 KoAlpaca 模型,显著降低显存需求,使得在低成本服务器上实现高并发推理成为可能。
KoAlpaca 通过提供专为韩语优化的开源模型与低资源训练方案,让中小团队也能以极低成本构建出具备母语级交互能力的 AI 应用。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 具体需求视模型大小而定: - 轻量级/QLoRA (4bit): Colab T4 (16GB) 可运行推理或小样本训练
- - 中等模型 (5.8B/12.8B Full Finetune): 推荐 RTX 3090/4090/A5000 (24GB),多卡需使用 Tensor Parallel
- - 大型模型 (30B/65B LoRA): 需 A100 (80GB) 或同等大显存 GPU,65B 模型默认容量超 100GB
未说明 (建议根据模型大小配置,65B 模型需系统内存 >100GB)
快速开始

更新日志
2024.05
- 因GPU服务器支持终止,Web应用演示将停止服务。
2023.07.28
- 增加了基于TensorParallel的训练示例代码,使用4台RTX3090(或4090/A5000)GPU进行训练:链接
2023.06.12
- 删除了Kakao/Telegram机器人相关说明
2023.06.08
- 增加了Colab:加载QLoRA训练的adapter权重进行推理教程
- 可在Colab Free(T4 GPU)上运行。
- 示例中使用了🤗beomi/qlora-koalpaca-polyglot-12.8b-50step仓库中的模型(经过50步训练的示例)。

- 增加了Colab:加载QLoRA训练的adapter权重进行推理教程
2023.06.02
- 基于28B tokens检查点的🐧KoRWKV-6B🤗,训练并发布了v1.1a版本的🐧KoAlpaca-KoRWKV-6B🤗
🐧KoAlpaca-KoRWKV-6B Hugging Face仓库🤗中包含了一些生成结果示例。
- 增加了使用RTX 3090/4090/A5000对Polyglot-ko 5.8B进行全量微调的指南:链接
- 基于28B tokens检查点的🐧KoRWKV-6B🤗,训练并发布了v1.1a版本的🐧KoAlpaca-KoRWKV-6B🤗
2023.05.30
- 增加了可在免费Colab(T4 GPU)上运行的训练示例:链接。使用QLoRA对Polyglot-ko 12.8B模型进行KoAlpaca v1.1a版本的训练,并采用4bit量化。
- 在Colab免费版(T4 GPU)上,处理50个样本大约需要4分钟,完成一个epoch大约需要15小时(达到最大使用时长限制)。
- 在Colab Pro版(A100 GPU)上,处理50个样本大约需要44秒,完成一个epoch大约需要2–3小时。
- 增加了可在免费Colab(T4 GPU)上运行的训练示例:链接。使用QLoRA对Polyglot-ko 12.8B模型进行KoAlpaca v1.1a版本的训练,并采用4bit量化。
2023.05.03
2023.04.28
- Logo更新🎉
2023.04.26
- WebUI中应用了Hugging Face ChatUI。
- 该ChatKoAlpaca GPU服务器在“大家研究所K-数字平台”的支持下提供服务。(已于2024年5月结束服务)
- WebUI中应用了Hugging Face ChatUI。
2023.04.20
2023.03.26:公开了基于🤗LLAMA 30B的KoAlpaca模型。(通过LoRA进行训练)
- LLAMA 30B的训练得到了GISTSundong Kim教授提供的A100 GPU支持,非常感谢 😄
2023.03.24:公开了基于🤗LLAMA 13B的KoAlpaca模型。(通过LoRA进行训练)
2023.03.23:公开了基于🤗LLAMA 65B的KoAlpaca模型。(通过LoRA进行训练)
2023.03.22:新增了移植到KakaoTalk的KoAlpaca机器人。
KoAlpaca:基于斯坦福Alpaca的韩语Alpaca模型(结合LLAMA和Polyglot-ko)
这是一款能够理解韩语的Alpaca模型,其训练方式与斯坦福Alpaca模型完全相同。
立即体验:通过聊天型网页(v1.1b-chat)、KakaoTalk机器人或Telegram机器人与它互动吧!
ChatKoAlpaca:聊天型KoAlpaca(Polyglot-ko-12.8b-v1.1b)
- 该演示由모두연 KoAlpaca Lab在“大家研究所K-数字平台”的支持下完成。非常感谢 😍
- 截至2024年5月,由于服务器支持终止,服务已停止。
- 无需安装,直接通过网页即可使用。
- 它会记住之前的对话上下文来生成回复。
- 最多可生成512个token的响应,同时会记住最多1024个token的上下文(包括新生成的回复)。
- 演示中使用了两台配备A5000 24G GPU的机器,通过Tensor Parallel进行服务,并以fp16模型提供支持。
完成的模型:韩语基础模型(Polyglot-ko) & 英韩模型(LLAMA)
KoAlpaca 以韩语模型 Polyglot-ko(5.8B)和英韩混合模型 LLAMA 作为骨干模型。
- 基于 Polyglot-ko 12.8B 的 [全量微调 v1.1] -> 🤗 beomi/KoAlpaca-Polyglot-12.8B
- 该模型曾用于 ChatKoAlpaca。
- 同时也提供了 🤗 8位量化版本。
- 基于 Polyglot-ko 5.8B 的 [全量微调] -> 🤗 beomi/KoAlpaca-Polyglot
- 基于 Meta LLAMA 7B 的 [全量微调] -> 🤗 beomi/KoAlpaca
- 基于 Meta LLAMA 13B 的 [LoRA 微调] -> 🤗 KoAlpaca-13B-LoRA
- 基于 Meta LLAMA 30B 的 [LoRA 微调] -> 🤗 KoAlpaca-30B-LoRA
- 基于 Meta LLAMA 65B 的 [LoRA 微调] -> 🤗 KoAlpaca-65B-LoRA
注:对于 LLAMA 13B,@deep-diver 训练的 🤗chansung/koalpaca-lora-13b 也已公开。)
Meta 的 LLAMA 模型并未充分学习韩语数据集,因此在实际推理时,其韩语性能较低。
为了获得更好的韩语质量,我们还使用了 Polyglot-ko 5.8B 和 12.8B 模型作为骨干,进行了进一步训练。
随后,结合 v1.1 数据集,我们发布了能够理解先前对话上下文及用户额外输入上下文的 KoAlpaca v1.1 模型。
KoAlpaca 模型运行示例代码
使用 Hugging Face Pipeline 运行
- 安装最新版 PyTorch 和 Hugging Face 库
pip install -U torch transformers tokenizers accelerate safetensors
可以使用以下示例代码进行运行:
import torch
from transformers import pipeline, AutoModelForCausalLM
MODEL = 'beomi/KoAlpaca-Polyglot-5.8B'
model = AutoModelForCausalLM.from_pretrained(
MODEL,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(device=f"cuda", non_blocking=True)
model.eval()
pipe = pipeline(
'text-generation',
model=model,
tokenizer=MODEL,
device=0
)
def ask(x, context='', is_input_full=False):
ans = pipe(
f"### 问题: {x}\n\n### 上下文: {context}\n\n### 回答:" if context else f"### 问题: {x}\n\n### 回答:",
do_sample=True,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
return_full_text=False,
eos_token_id=2,
)
print(ans[0]['generated_text'])
ask("深度学习是什么?")
# 深度学习是机器学习的一个分支,它通过人工神经网络来学习输入与输出之间的复杂关系。这项技术使计算机能够以类似于人类学习的方式识别模式,并且无需人工干预即可处理数据。近年来,利用深度学习的人工智能应用得到了广泛发展。例如,在医疗诊断领域,深度学习技术被用来分析患者的特征,从而实现快速而准确的诊断。此外,在金融领域,深度学习也被用于训练股票价格预测模型。
Gradio 示例 - 全量微调 & 8位量化 🌟 推荐 🌟
请参考本仓库的 webui 文件夹。
Gradio 示例 - LoRA
请参考 @deep-diver 的 deep-diver/Alpaca-LoRA-Serve 仓库并运行。
# 按照上述仓库的指南安装后..
BASE_URL=decapoda-research/llama-13b-hf # 30B模型为 llama-30b-hf,65B模型为 llama-65b-hf 注意:65B模型默认占用内存超过100GB。
FINETUNED_CKPT_URL=beomi/KoAlpaca-13B-LoRA # 30B模型为 KoAlpaca-30B-LoRA,65B模型为 KoAlpaca-65B-LoRA 注意:65B模型仅能在配备 A100 80G 等超大显存的 GPU 上运行。
python app.py --base_url $BASE_URL --ft_ckpt_url $FINETUNED_CKPT_URL --port 6006
数据集 v1.1 制作方法
v1.1 数据集旨在改善原有 Alpaca 模型回答简短、无法理解上下文的问题而制作。
- 数据集选择与收集
v1.1 数据集通过爬取 Naver 知识人内容生成。
我们收集了 Naver 知识人精华区 的所有问题。
- 数据加工
实际生成的数据基于问题及其正文,以及被采纳的答案正文重新构建。
数据通过 ChatGPT 生成,并采用批量解码方式完成。
注:原有的知识人问题和答案被用作 ChatGPT 的参考种子。
数据集 v1.0 制作方法
数据集基本上以 斯坦福 Alpaca 提供的 5.2 万条数据集 为基础。
- 数据集翻译
Alpaca 数据集由 Instruct 部分、Input 部分以及 Output 部分组成,如下所示:
...
{
"instruction": "描述一次你必须做出艰难决定的经历。",
"input": "",
"output": "我在一家建筑公司担任项目经理时,曾面临过一次艰难的抉择。当时我负责的一个项目必须在特定日期前完工,才能满足客户期望。然而由于意外延误,我们无法按时完成任务,因此不得不做出一个艰难的决定。最终我决定延长工期,但这意味着要进一步调动团队资源并增加预算。尽管这一决定风险很大,但我还是决定执行,以确保项目能够如期完成,并满足客户的期望。最后,项目顺利竣工,这也证明了我的领导能力和决策水平。"
},
{
"instruction": "找出不同的一项。",
"input": "推特、Instagram、Telegram",
"output": "Telegram"
},
...
其中 Output 部分是由 OpenAI 的 text-davinci-003 模型生成的,因此这部分没有进行翻译。
所以,我们只翻译了 Instruct 和 Input 两列,并剔除了 Input 部分存在错误的一些条目。
为了进行翻译,我们使用了 DeepL API 服务,翻译后的数据格式如下:
...
{
"instruction": "找出不同的一项。",
"input": "推特、Instagram、Telegram"
}
...
- Output 数据生成
随后,我们将这些 Instruct 和 Input 通过批量解码技术,利用 OpenAI ChatGPT API(gpt-3.5-turbo)生成数据。
与 Alpaca 研究相同,我们对每一对 Instruct/Input 组合仅生成一个回复,从而构建数据集。
在原有研究中,每次会同时生成 20 条数据,但我们在用韩语生成时发现,每次同时生成 10 条数据时效果更稳定,因此我们改为每次生成 10 条。
以下是用于生成回答的提示词:
PROMPT = """\
请为各种任务生成回答。这些任务指令将提供给 ChatGPT 模型,ChatGPT 模型将根据指令完成任务并进行评估。
要求如下:
1. 为最大化多样性,请确保每个指令中的动词不重复。
2. 指令所使用的语言也应多样化,例如可以结合提问和命令式指示。
3. 指令类型应多样化,包括开放式生成、分类、编辑等多种类型的任务。
4. GPT 语言模型应能够完成这些指令。例如,不要要求助手生成视觉或音频输出;也不要请求助手设置下午 5 点的闹钟或提醒,因为助手无法执行此类操作。
5. 回答必须用韩语撰写。
6. 回答长度控制在 1–2 句话以内,可以是陈述句或疑问句。
7. 必须为指令生成合适的输入内容。输入字段应包含针对指令的具体示例,需使用真实数据,不得仅使用占位符。输入内容应具有一定的复杂性,使指令更具挑战性,但理想情况下不超过 100 字。
8. 部分指令不需要额外输入,而另一些指令则需要提供输入内容。例如,“世界上最高的山峰是什么?”这类一般性问题无需提供具体背景信息,因此输入字段可以留空。
9. 输出必须是对指令及输入的恰当回应。
请根据以下 10 条指令及其可选输入,生成相应的回答。回答应按照编号从 0 到 9 的顺序排列,每个编号对应一条指令和其对应的输入内容。请用 ### 分隔每条回答。
回答0:第一条回答内容###
回答1:第二条回答内容###
...
回答9:最后一条回答内容"""
此外,我们还添加了如下 ChatGPT API 的系统提示词:
"content": "以下是一些任务指令。如果没有输入,请忽略输入部分,直接根据指令给出适当的回答。如果有额外输入,则需结合指令和输入内容给出恰当的回答。"
最终生成的韩语数据集保存在 ko_alpaca_data.json 文件中。
微调方式的模型训练方法
QLoRA 4bit 训练方法 Google Colab 示例
- 使用 QLoRA 对 Polyglot-ko 12.8B 模型进行 KoAlpaca v1.1a 微调,采用 4bit 精度
- 仅用 1000 个样本训练的模型生成结果示例
### 问题:看跌期权和看涨期权有什么区别?普通散户投资者应该选择哪种仓位?
### 回答:看跌期权是指买入股票的行为,而看涨期权则是指卖出股票的行为。举例来说,如果某公司的股价为 10 万元,且该公司正在开展新业务,预计未来收入会增加,企业价值也将随之提升,那么买入该公司的股票就是看跌期权。不过,在买入股票时,如果公司股价下跌,你的投资也会面临损失的风险。相反,看涨期权是指卖出股票。当公司股价上涨、前景看好时,你可以获得更高的收益,这是一种相对稳健的投资方式。对于普通散户投资者而言,在买卖股票时会面临多种风险,因此建议在专业人士的指导下,结合自身的投资经验制定合适的投资策略。有关投资的更多详细信息,您可以通过下方链接免费获取。"
### 问题:什么是保证金催缴?如何避免发生保证金催缴?
### 回答:保证金催缴是指在期货/期权交易中,由于保证金不足,交易所要求追加缴纳保证金的情况。追加保证金是在初始约定保证金的基础上,因市场波动而需要额外支付的保证金。通常情况下,买入合约时需缴纳合约金额的 10% 作为保证金,而卖出合约则需缴纳 3%。因此,买入合约总共需要 20% 的保证金,卖出合约则需要 9% 的保证金。在期货交易过程中,每日根据市场价格变化,可能需要随时追加保证金,一旦保证金不足,就会触发保证金催缴。所以在进行期货交易之前,务必确保有足够的保证金。可以通过“期货/期权 → 保证金 → 追加缴纳/平仓”等方式查询保证金情况,也可以通过网络或电话查询。此外,还可以通过“订单/保证金 → 追加保证金”来补充保证金。补充保证金
ChatKoAlpaca(KoAlpaca Polyglot-ko-12.8B-v1.1b)模型训练
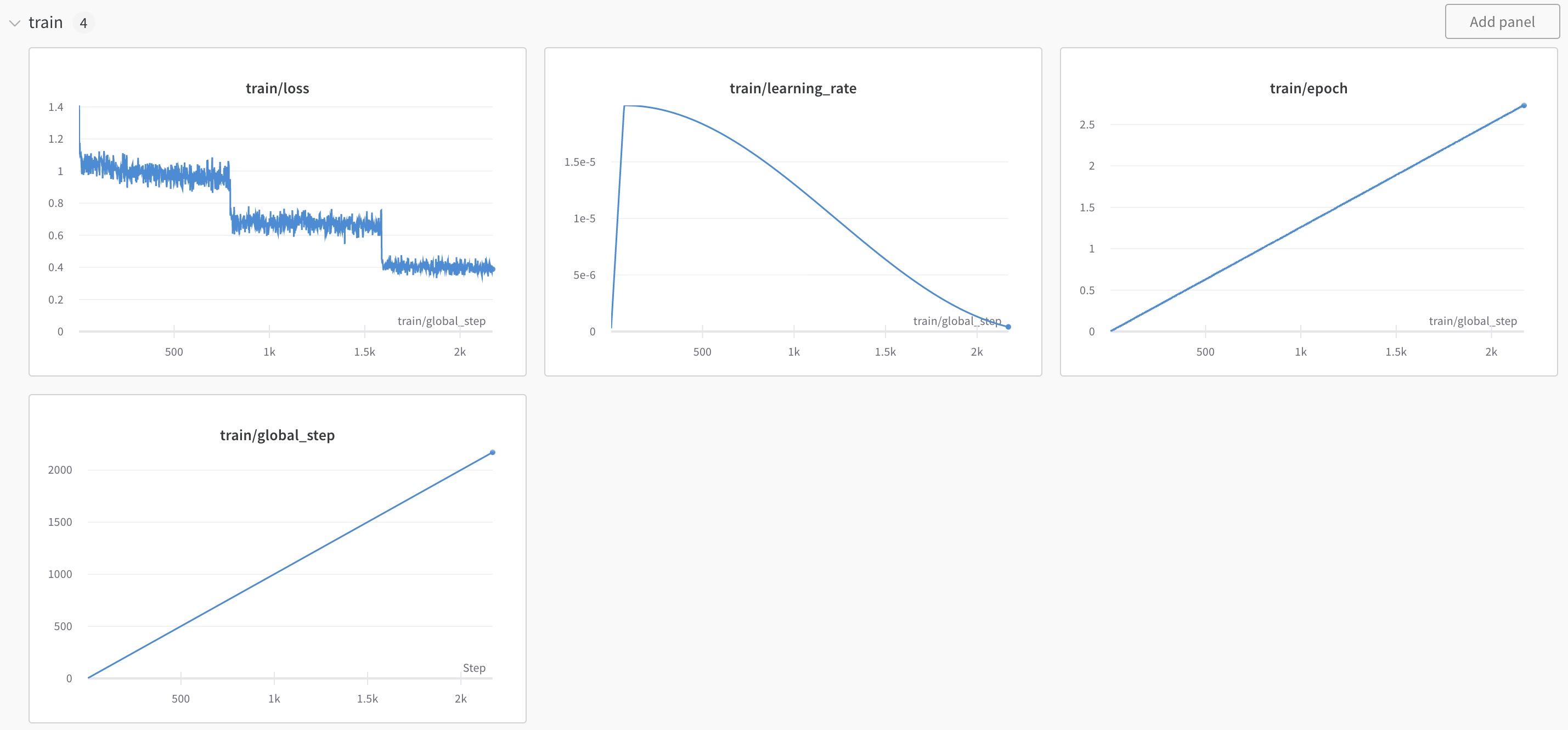
ChatKoAlpaca(KoAlpaca Polyglot-ko-12.8B-v1.1b)模型是在 4 台 A100 80GB 显卡上进行训练的,并通过 DeepSpeed ZeRO-3 实现全分片训练。
相关代码请参考当前仓库的 train_1.1b 文件夹。
Polyglot-ko 5.8B 模型训练
该模型是在一台 A100 80GB 显卡上进行训练的。
LLAMA 7B 模型训练
基于 LLAMA 的模型训练是在 4 台 A100 80GB 显卡上进行的,并采用了 FSDP 进行训练。
用于训练的代码保存在 train.py 文件中,用于运行训练的脚本保存在 train.sh 文件中。
使用 FSDP 训练模型时的注意事项
LLAMA 模型已包含在 Huggingface Transformers 4.28.0 或更高版本中。如果使用低于该版本的库,则会出现找不到 llama 的错误。在使用 FSDP 时,需要包裹的层是 LlamaDecoderLayer。
# train.sh
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
LoRA 方式模型训练方法
LLAMA 13B 模型训练
🤗 Huggingface 仓库:https://huggingface.co/beomi/KoAlpaca-13B-LoRA
该模型是在 4 张 RTX 3090 24GB 显卡上训练的。训练代码基于 https://github.com/tloen/alpaca-lora 开发。
训练数据集由该仓库的 alpaca_data_cleaned.json(英文版)和当前仓库的 ko_alpaca_data.json 合并而成。
LLAMA 30B 模型训练
🤗 Huggingface 仓库:https://huggingface.co/beomi/KoAlpaca-30B-LoRA
该模型是在 2 台 A100 40GB 显卡上训练的。训练代码同样基于 https://github.com/tloen/alpaca-lora 开发。
- LLAMA 30B 的训练得到了 Sundong Kim 教授的 A100 设备支持。
训练数据集由该仓库的 alpaca_data_cleaned.json(英文版)和当前仓库的 ko_alpaca_data.json 合并而成。
LLAMA 65B 模型训练
🤗 Huggingface 仓库:https://huggingface.co/beomi/KoAlpaca-65B-LoRA
该模型是在 8 台 A100 80GB 显卡上训练的。训练代码同样基于 https://github.com/tloen/alpaca-lora 开发。
训练数据集由该仓库的 alpaca_data_cleaned.json(英文版)和当前仓库的 ko_alpaca_data.json 合并而成。
基准测试
NSMC 基准测试
基准测试方法
- 对
polyglot-ko 5.8b和KoAlpaca-polyglot进行基准性能对比 - 采用少样本学习方式,分为两种提示类型进行测试
1. 少样本学习配置
少样本配置
- 设置
k=10 - 仅包含文本标记长度不超过25的句子
- 只选取数据标记长度约75百分位的数据
- 设置
NSMC 数据标记长度分布
少样本案例标记平均长度:20.229
少样本案例标记最大长度:280
少样本案例标记长度标准差:16.488
少样本案例标记长度80百分位数:27.0
2. 提示词构成
- 提示词类型1:非常简单的提示词构成,未明确说明分析任务内容
def build_prompt_text(sent):
return "句子: " + sent + '\n情感:'
- 提示词类型2:相比提示词类型1,包含了任务意图内容,并以疑问句形式表达分析任务
def build_prompt_text(sent):
return '以下句子是正面还是负面?\n' + sent + '\n答案:'
3. 基准测试结果
| 准确率 | 提示词类型1 | 提示词类型2 |
|---|---|---|
| polyglot-ko | 0.5752 | 0.7223 |
| koalpaca-polyglot | 0.6939 | 0.7683 |
斯坦福 Alpaca:一个遵循指令的 LLaMA 模型
![]()
![]()
![]()
这是斯坦福 Alpaca 项目的仓库,旨在构建并分享一个遵循指令的 LLaMA 模型。该仓库包含:
概述
当前的 Alpaca 模型是在 7B LLaMA 模型 [1] 的基础上,使用来自 Self-Instruct [2] 论文技术生成的 52K 条遵循指令的数据进行微调的,其中我们对这些技术做了一些修改,具体将在下一节中讨论。
在初步的人工评估中,我们发现 Alpaca 7B 模型在 Self-Instruct 遵循指令的评估套件 [2] 上的表现与 text-davinci-003 模型相似。
Alpaca 仍处于开发阶段,存在许多需要解决的局限性。 重要的是,我们尚未对 Alpaca 模型进行安全无害的微调。 因此,我们鼓励用户在与 Alpaca 互动时保持谨慎,并报告任何令人担忧的行为,以帮助提高模型的安全性和伦理考量。
我们最初的发布内容包括数据生成流程、数据集和训练配方。如果获得 LLaMA 创作者的许可,我们计划发布模型权重。目前,我们选择托管一个在线演示,以帮助读者更好地理解 Alpaca 的能力和局限性,同时也为我们提供了一个在更广泛受众中评估 Alpaca 性能的方式。
请阅读我们的发布 博客文章 ,了解更多关于模型的信息、我们对 Alpaca 模型潜在危害和限制的讨论,以及我们发布可复现模型的思考过程。
[1]: LLaMA:开放且高效的底层语言模型。Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azhar、Aurelien Rodriguez、Armand Joulin、Edouard Grave、Guillaume Lample。https://arxiv.org/abs/2302.13971v1
[2]: Self-Instruct:通过自我生成的指令对齐语言模型。Yizhong Wang、Yeganeh Kordi、Swaroop Mishra、Alisa Liu、Noah A. Smith、Daniel Khashabi、Hannaneh Hajishirzi。https://arxiv.org/abs/2212.10560
数据发布
alpaca_data.json 包含我们用于微调 Alpaca 模型的 52K 条遵循指令的数据。
此 JSON 文件是一个字典列表,每个字典包含以下字段:
instruction:str,描述模型应执行的任务。这 52K 条指令均不重复。input:str,任务的可选上下文或输入。例如,当指令为“总结以下文章”时,输入就是这篇文章。大约 40% 的例子都有输入。output:str,由text-davinci-003生成的指令回答。
我们使用以下提示语来微调 Alpaca 模型:
- 对于
input字段非空的例子:
下面是一条描述任务的指令,配有一个提供更多上下文的输入。请撰写一条恰当完成请求的回复。
### 指令:
{instruction}
### 输入:
{input}
### 回复:
- 对于
input字段为空的例子:
下面是一条描述任务的指令。请撰写一条恰当完成请求的回复。
### 指令:
{instruction}
### 回复:
在推理过程中(例如在网页演示中),我们使用用户提供的指令,且 input 字段为空(第二种选项)。
数据生成流程
运行代码
- 将环境变量
OPENAI_API_KEY设置为您的 OpenAI API 密钥。 - 使用
pip install -r requirements.txt安装依赖项。 - 运行
python -m generate_instruction generate_instruction_following_data以生成数据。
我们基于 self-instruct 的数据生成流程进行了改进,具体如下:
- 我们使用
text-davinci-003生成指令数据,而不是davinci。 - 我们编写了一个新的提示语文件 (
prompt.txt),明确要求text-davinci-003生成指令。请注意:我们使用的提示语中存在一个小错误,未来用户应参考 https://github.com/tatsu-lab/stanford_alpaca/pull/24 中的修正。 - 我们采用了更为激进的批量解码方式,即一次生成 20 条指令,从而大大降低了数据生成成本。
- 我们简化了数据生成流程,不再区分分类和非分类指令。
- 我们只针对每条指令生成一个实例,而不是像 [1] 中那样生成 2 到 3 个实例。
这样,我们就以更低的成本(不到 500 美元)得到了包含 52K 个样例的遵循指令数据集。初步研究还表明,我们生成的 52K 条数据比 self-instruct 发布的数据更加多样化。 我们绘制了下图(风格类似于 self-instruct 论文 中的图 2),以展示我们数据的多样性。图表中的内圈代表指令的动词根,外圈则代表直接宾语。
[//]: # ()

微调
我们使用标准的 Hugging Face 训练代码,并采用以下超参数对模型进行微调:
| 超参数 | 值 |
|---|---|
| 批量大小 | 128 |
| 学习率 | 2e-5 |
| Epoch 数 | 3 |
| 最大长度 | 512 |
| 权重衰减 | 0 |
由于 Hugging Face 尚未正式支持 LLaMA 模型,我们通过从特定分支安装 Hugging Face 的 transformers 库来对 LLaMA 进行微调(即等待此 PR 合并)。
我们安装的具体提交的哈希值为 68d640f7c368bcaaaecfc678f11908ebbd3d6176。
要复现我们的 LLaMA 微调实验,首先安装依赖:
pip install -r requirements.txt
然后安装 Hugging Face 的特定分支 transformers 库。
以下命令将在配备 4 张 A100 80G 显卡的机器上,以 FSDP full_shard 模式对 LLaMA-7B 进行微调。我们使用 Python 3.10 和以下命令成功复现了与我们在演示中使用的模型质量相近的模型。请将 <your_random_port> 替换为你选择的端口,将 <your_path_to_hf_converted_llama_ckpt_and_tokenizer> 替换为你转换后的检查点和分词器的路径(按照 PR 中的说明操作),并将 <your_output_dir> 替换为你希望存储输出的目录。
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
--model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
--data_path ./alpaca_data.json \
--bf16 True \
--output_dir <your_output_dir> \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LLaMADecoderLayer' \
--tf32 True
注意事项
fsdp_transformer_layer_cls_to_wrap 必须设置为具体的解码器层名称。目前 Hugging Face 的 LLaMA PR 尚不稳定。早期的提交使用 LLaMADecoderLayer 作为解码器层名称(这也是我们代码所基于的提交)。而较新的提交则使用 LlamaDecoderLayer(注意大小写差异)。如果未将 fsdp_transformer_layer_cls_to_wrap 设置为正确的名称,训练速度将会大幅下降。
补充说明
同样的脚本也适用于 OPT 模型的微调。以下是微调 OPT-6.7B 的示例:
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
--model_name_or_path "facebook/opt-6.7b" \
--data_path ./alpaca_data.json \
--bf16 True \
--output_dir <your_output_dir> \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'OPTDecoderLayer' \
--tf32 True
请注意,提供的训练脚本旨在简单易用,并未经过特别优化。若要在更多 GPU 上运行,建议适当降低 gradient_accumulation_steps 以保持全局批量大小为 128。全局批量大小尚未经过最优性测试。
作者
以下所有研究生贡献均等,顺序由随机抽取决定:
以上人员均由 Tatsunori B. Hashimoto 指导。其中,Yann 还受到 Percy Liang 的指导,Xuechen 则受到 Carlos Guestrin 的指导。
引用
如果你使用了本仓库中的数据或代码,请引用该仓库:
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {斯坦福 Alpaca:一个遵循指令的 LLaMA 模型},
year = {2023},
publisher = {GitHub},
journal = {GitHub 仓库},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
此外,你也应同时引用原始的 LLaMA 论文 [1] 和 Self-Instruct 论文 [2]。
致谢
我们感谢 Yizhong Wang 在解释 Self-Instruct 数据生成流程以及提供解析分析图代码方面所提供的帮助。我们也感谢 Yifan Mai 的支持,以及斯坦福 NLP 小组和基础模型研究中心 (CRFM) 成员们提出的宝贵意见。
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。