awesome-panoptic-segmentation
awesome-panoptic-segmentation 是一个专注于全景分割(Panoptic Segmentation)领域的开源资源合集。它旨在解决计算机视觉中语义分割(处理背景等“物质”)与实例分割(处理车辆、行人等“物体”)长期分离的问题,通过统一框架让 AI 既能识别场景类别,又能区分独立个体,从而实现对图像更完整、通用的理解。
该资源库系统性地整理了全球范围内的前沿论文、核心代码实现、主流数据集(如 COCO-Panoptic、Cityscapes)、评估指标详解以及权威的基准测试结果。其独特亮点在于提供了详尽的性能对比表格,涵盖 PQ、SQ、RQ 等多种关键指标,帮助使用者快速定位最优算法方案,并附带了标准评估代码链接及相关技术教程。
awesome-panoptic-segmentation 特别适合计算机视觉研究人员、AI 算法工程师及深度学习开发者使用。无论是希望追踪最新学术进展的研究者,还是正在寻找可靠基线模型进行项目开发的工程师,都能从中获得极具价值的参考信息,是进入全景分割领域不可或缺的入门指南与案头工具。
使用场景
某自动驾驶初创公司的算法团队正致力于提升车辆对复杂城市道路环境的感知能力,需要同时精准识别可行驶区域(如路面、天空)和独立物体(如行人、车辆)。
没有 awesome-panoptic-segmentation 时
- 技术选型迷茫:团队需要在语义分割和实例分割之间做取舍,或花费数周时间自行摸索如何将两者统一,缺乏明确的技术路线图。
- 数据准备低效:难以快速找到同时包含“东西”(Thing)和“背景”(Stuff)标注的高质量数据集,导致模型训练数据匮乏或不一致。
- 评估标准混乱:缺乏统一的评估代码和指标(如 PQ、PC),团队成员使用不同的脚本验证模型,导致结果无法横向对比,难以判断算法优劣。
- 复现成本高昂:想要验证前沿论文效果时,往往找不到对应的开源代码或基准测试结果,只能从头复现,严重拖慢研发进度。
使用 awesome-panoptic-segmentation 后
- 路线清晰明确:直接获取全景分割领域的权威综述,快速理解如何在一个框架下统一解决两类分割任务,确立了基于 UPSNet 或 Panoptic FPN 的技术路线。
- 数据资源直达:通过整理的列表迅速锁定 COCO-Panoptic 和 Cityscapes 等关键数据集,立即启动高质量数据的下载与预处理流程。
- 评估规范统一:直接调用集成的官方评估代码和标准指标(PQ),团队内部建立了统一的性能基线,模型迭代效率显著提升。
- 站在巨人肩上:参考详细的 Benchmark 结果和论文链接,直接复用表现最优的骨干网络配置,将新算法的研发周期从数月缩短至数周。
awesome-panoptic-segmentation 通过一站式整合资源,将团队从繁琐的信息搜集与基建工作中解放出来,使其能专注于核心算法的创新与落地。
运行环境要求
未说明
未说明

快速开始
令人惊叹的全景分割 
这个仓库收集了关于全景分割领域的前沿研究,包括论文、代码和基准测试结果等。
大纲
普遍分割

结构概述
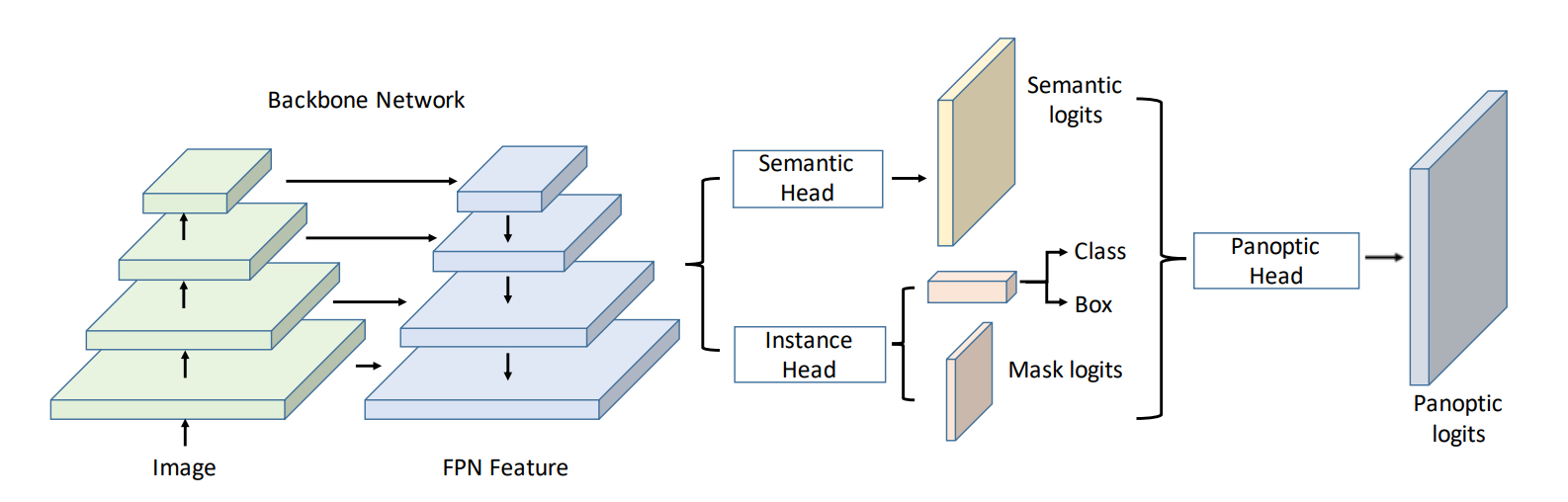
摘自 UPSNet。
数据集
通常,同时包含语义和实例标注的数据集都可以用于解决全景分割任务。
评估
评价指标
PQ是在 Panoptic Segmentation 中描述的标准指标。
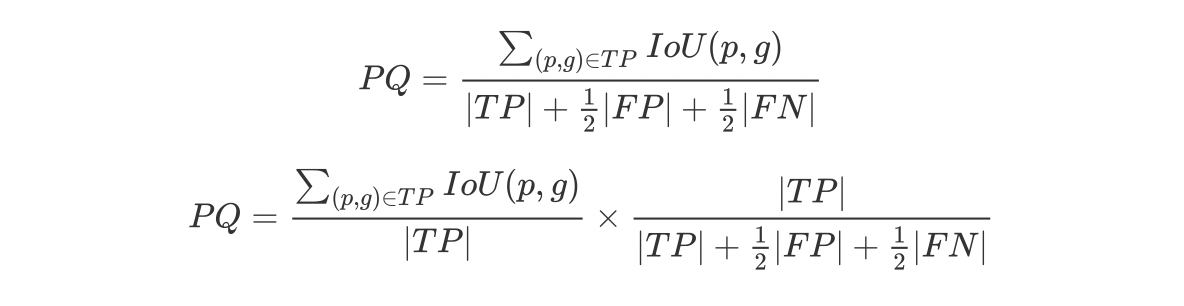
PC是在 DeeperLab 中描述的标准指标。
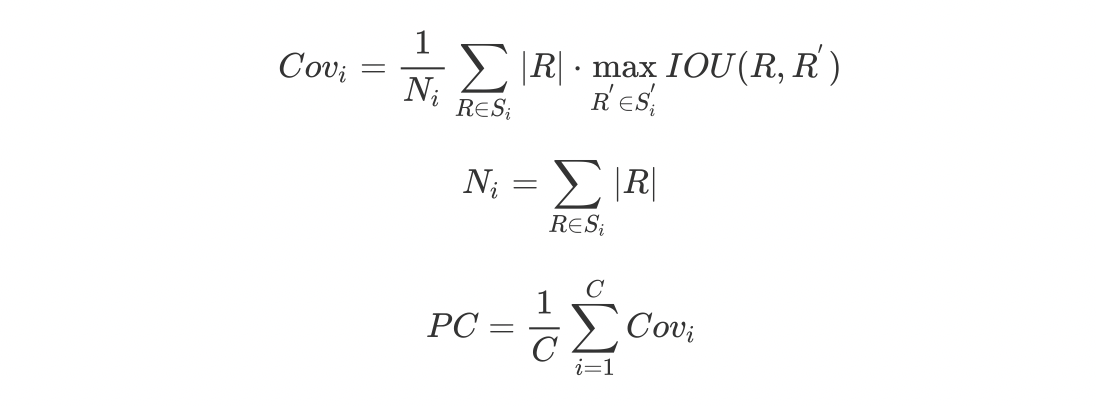
评估代码
竞赛
- AutoNUE 2019 全景分割挑战赛(ICCV 2019 研讨会,已结束)
- COCO 2019 全景分割任务(ICCV 2019 研讨会,已结束)
- Mapillary 2019 全景分割任务(ICCV 2019 研讨会,已结束)
- Cityscapes 全景语义标注任务(开放中)
- COCO 2018 全景分割任务(ECCV 2018 研讨会,已结束)
- Mapillary Vistas 2018 全景分割任务(ECCV 2018 研讨会,已结束)
基准测试结果
COCO val 基准
| 方法 | 主干网络 | PQ | PQ-Thing | PQ-Stuff | SQ | RQ | mIoU | AP-Mask | PC | e2e |
|---|---|---|---|---|---|---|---|---|---|---|
| SOGNet | ResNet-50 | 43.7 | 50.6 | 33.2 | 78.7 | 53.5 | 54.56 | 34.2 | - | :white_check_mark: |
| UPSNet | ResNet-50 | 42.5 | 48.6 | 33.4 | - | - | 54.3 | 34.3 | - | :white_check_mark: |
| OANet | ResNet-101 | 41.3 | 50.4 | 27.7 | - | - | - | - | - | :white_check_mark: |
| OCFusion | ResNet-50 | 41.0 | 49.0 | 29.0 | 77.1 | 50.6 | - | - | - | :white_check_mark: |
| Panoptic FPN | ResNet-101 | 40.9 | 48.3 | 29.7 | - | - | - | - | - | :white_check_mark: |
| AUNet | ResNet-50 | 39.6 | 49.1 | 25.2 | - | - | 45.1 | 34.7 | - | :white_check_mark: |
| AdaptIS | ResNet-101 | 37.0 | 41.8 | 29.9 | - | - | - | - | - | :white_check_mark: |
| DeeperLab | Xception-71 | 34.3 | 37.5 | 29.6 | 77.1 | 43.1 | - | - | 56.8 | :white_check_mark: |
Cityscapes val 基准
| 方法 | 主干网络 | PQ | PQ-Thing | PQ-Stuff | SQ | RQ | mIoU | AP-Mask | PC | e2e |
|---|---|---|---|---|---|---|---|---|---|---|
| Panoptic(Merge) | - | 61.2 | 66.4 | 54.0 | 80.9 | 74.4 | - | - | - | :negative_squared_cross_mark: |
| AdaptIS | ResNet-101 | 60.6 | 58.7 | 64.4 | - | - | 79.2 | 36.3 | - | :white_check_mark: |
| SOGNet | ResNet-50 | 60.0 | 56.7 | 62.5 | - | - | - | - | - | :white_check_mark: |
| Seamless | ResNet-50 | 59.8 | 53.4 | 64.5 | - | - | 75.4 | 31.9 | - | :white_check_mark: |
| UPSNet | ResNet-50 | 59.3 | 54.6 | 62.7 | 79.7 | 73.0 | 75.2 | 33.3 | - | :white_check_mark: |
| TASCNet | ResNet-101 | 59.2 | 56 | 61.5 | - | - | 77.8 | 37.6 | - | :white_check_mark: |
| AUNet | ResNet-101 | 59.0 | 54.8 | 62.1 | - | - | 75.6 | 34.4 | - | :white_check_mark: |
| Panoptic FPN | ResNet-101 | 58.1 | 52.0 | 62.5 | - | - | 75.7 | 33.0 | - | :white_check_mark: |
| DeeperLab | Xception-71 | 56.5 | - | - | - | - | - | - | 75.6 | :white_check_mark: |
Mapillary val 基准
| 方法 | 主干网络 | PQ | PQ-Thing | PQ-Stuff | SQ | RQ | mIoU | AP-Mask | PC | e2e |
|---|---|---|---|---|---|---|---|---|---|---|
| Panoptic(Merge) | - | 38.3 | 41.8 | 35.7 | 73.6 | 47.7 | - | - | - | :negative_squared_cross_mark: |
| Seamless | ResNet-50 | 37.2 | 33.2 | 42.5 | - | - | 50.2 | 16.3 | - | :white_check_mark: |
| AdaptIS | ResNet-101 | 33.4 | 28.3 | 40.3 | - | - | - | - | - | :white_check_mark: |
| TASCNet | ResNet-101 | 32.6 | 31.3 | 34.4 | - | - | 35.0 | 18.5 | - | :white_check_mark: |
| DeeperLab | Xception-71 | 32.0 | - | - | - | - | - | - | 55.3 | :white_check_mark: |
论文
AAAI2020
- SOGNet: 杨一博、李洪洋、李霞、赵启杰、吴建龙、林周晨。
“SOGNet:用于全景分割的场景重叠图网络。” AAAI(2020)。[论文]
ICCV2019
AdaptIS: 康斯坦丁·索菲尤克、奥尔加·巴里诺娃、安东·科努申。
“AdaptIS:自适应实例选择网络。” ICCV(2019)。[论文]程阳福、塔玛拉·L·伯格、亚历山大·C·伯格。
“IMP:实例掩码投影技术,用于高精度的事物语义分割。” ICCV(2019)。[论文]邓博文、麦克斯韦尔·D·柯林斯、朱玉坤、刘婷、托马斯·S·黄、哈特维格·亚当、陈良哲。
“Panoptic-DeepLab:一种简单、强大且快速的自下而上全景分割基线。” ICCVW(2019)。[论文]
CVPR2019
全景分割: Alexander Kirillov、Kaiming He、Ross Girshick、Carsten Rother、Piotr Dollár。
“全景分割”。CVPR(2019)。[论文]全景FPN: Alexander Kirillov、Ross Girshick、Kaiming He、Piotr Dollár。
“全景特征金字塔网络”。CVPR(2019 口头报告)。[论文] [非官方代码][detectron2]AUNet: Yanwei Li、Xinze Chen、Zheng Zhu、Lingxi Xie、Guan Huang、Dalong Du、Xingang Wang。
“用于全景分割的注意力引导统一网络”。CVPR(2019)。[论文]UPSNet: Yuwen Xiong、Renjie Liao、Hengshuang Zhao、Rui Hu、Min Bai、Ersin Yumer、Raquel Urtasun。
“UPSNet:统一的全景分割网络”。CVPR(2019 口头报告)。[论文] [代码]DeeperLab: Tien-Ju Yang、Maxwell D. Collins、Yukun Zhu、Jyh-Jing Hwang、Ting Liu、Xiao Zhang、Vivienne Sze、George Papandreou、Liang-Chieh Chen。
“DeeperLab:单次图像解析器”。CVPR(2019 口头报告)。[论文] [项目] [代码]OANet: Huanyu Liu、Chao Peng、Changqian Yu、Jingbo Wang、Xu Liu、Gang Yu、Wei Jiang。
“用于全景分割的端到端网络”。CVPR(2019)。[论文]Eirikur Agustsson、Jasper R. R. Uijlings、Vittorio Ferrari。
“通过联合考虑所有区域实现交互式全图像分割”。CVPR(2019)。[论文]Seamless: Lorenzo Porzi、Samuel Rota Bulo、Aleksander Colovic、Peter Kontschieder。
“无缝场景分割”。CVPR(2019)(扩展版)。[论文][代码]
ECCV2018
ArXiv
Rohit Mohan、Abhinav Valada。
“EfficientPS:高效的全景分割”。arXiv(2020)。[论文]Rui Hou、Jie Li、Arjun Bhargava、Allan Raventos、Vitor Guizilini、Chao Fang、Jerome Lynch、Adrien Gaidon。
“基于密集检测的实时全景分割”。arXiv(2019)。[论文]Mark Weber、Jonathon Luiten、Bastian Leibe。
“单次全景分割”。arXiv(2019)。[论文]Qiang Chen、Anda Cheng、Xiangyu He、Peisong Wang、Jian Cheng。
“SpatialFlow:为全景分割打通所有任务”。arXiv(2019)。[论文]Sagi Eppel、Alan Aspuru-Guzik。
“生成器—评估器—选择器网络:一种用于全景分割的模块化方法”。arXiv(2019)。[论文]Jasper R. R. Uijlings、Mykhaylo Andriluka、Vittorio Ferrari。
“带有协作助手的全景图像标注”。arXiv(2019)。[论文]OCFusion: Justin Lazarow、Kwonjoon Lee、Zhuowen Tu。
“学习实例遮挡以进行全景分割”。arXiv(2019)。[论文]PEN: Yuan Hu、Yingtian Zou、Jiashi Feng。
“全景边缘检测”。arXiv(2019)。[论文]TASCNet: Jie Li、Allan Raventos、Arjun Bhargava、Takaaki Tagawa、Adrien Gaidon。
“学习融合事物与语义信息”。arXiv(2018)。[论文]Daan de Geus、Panagiotis Meletis、Gijs Dubbelman。
“使用联合语义与实例分割网络进行全景分割”。arXiv(2018)。[论文]Daan de Geus、Panagiotis Meletis、Gijs Dubbelman。
“用于街景理解的单网络全景分割”。arXiv(2019)。[论文]David Owen、Ping-Lin Chang。
“通过结合语义与实例分割检测反射”。arXiv(2019)。[论文]Gaku Narita、Takashi Seno、Tomoya Ishikawa、Yohsuke Kaji。
“PanopticFusion:在事物与语义层面的在线体积语义建图”。arXiv(2019,IROS)。[论文]
教程
博客
- Megvii(Face++)检测团队。[知乎]
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。