claude-seo
claude-seo 是专为 Claude Code 设计的全能 SEO 分析技能插件,涵盖技术 SEO、内容质量(E-E-A-T)、Schema 标记、AI 搜索优化(GEO)及战略规划等核心领域。面对传统 SEO 审计流程繁琐、依赖多工具手动切换的痛点,claude-seo 通过 7 个子代理并行协作,实现一键式全站审计、单页深度分析及竞品对比,大幅缩短诊断时间。
claude-seo 特别适合 SEO 专家、Web 开发者、数字营销人员及内容创作者。无论是需要快速排查网站技术隐患,还是规划针对 AI 搜索的优化策略,claude-seo 都能提供专业支持。其技术亮点在于内置扩展系统与 DataForSEO MCP 集成,支持灵活的功能拓展;独有的程序化 SEO 功能还能基于数据源规模化生成高质量页面。安装过程注重安全,支持主流操作系统,让 SEO 工作流更加智能化与高效化。
使用场景
一位独立开发者正在上线新的 SaaS 产品落地页,急需确保搜索引擎可见性并优化 AI 搜索排名,但缺乏专业 SEO 团队支持。
没有 claude-seo 时
- 需要手动检查几十个技术细节(如 meta 标签、加载速度),容易遗漏关键错误导致收录失败。
- 缺乏专业工具验证 Schema 标记是否正确,导致结构化数据无法被搜索引擎识别为富文本。
- 针对 AI 搜索优化(GEO)毫无头绪,不知道如何调整内容以适配生成式引擎的抓取逻辑。
- 制定 SEO 策略耗时数天,需查阅大量文档并手动对比竞品页面结构。
使用 claude-seo 后
- 运行
/seo audit一键完成全站技术审计,并行子代理快速定位所有潜在问题。 - 通过
/seo schema自动检测并生成正确的 Schema.org 标记,显著提升搜索结果展示质量。 - 利用
/seo geo指令针对性优化内容结构,直接适配 AI Overviews 抓取逻辑以获得曝光。 - 调用
/seo plan根据 SaaS 类型生成定制化战略方案,将调研时间从几天缩短至几分钟。
claude-seo 将复杂的 SEO 流程转化为代码指令,让非专家也能高效掌控网站搜索表现。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始

Claude SEO - Claude Code 的 SEO (搜索引擎优化) 审计技能
适用于 Claude Code 的综合 SEO (搜索引擎优化) 分析技能。涵盖技术 SEO、页面内分析、内容质量(E-E-A-T)、Schema 标记、图片优化、站点地图架构、AI 搜索优化(GEO)以及战略规划。
![]()
![]()

目录
安装
推荐安装方式 (Unix/macOS/Linux)
git clone --depth 1 https://github.com/AgriciDaniel/claude-seo.git
bash claude-seo/install.sh
单行命令 (curl)
curl -fsSL https://raw.githubusercontent.com/AgriciDaniel/claude-seo/main/install.sh | bash
或通过 install.cat:
curl -fsSL install.cat/AgriciDaniel/claude-seo | bash
希望在运行前审查脚本吗?
curl -fsSL https://raw.githubusercontent.com/AgriciDaniel/claude-seo/main/install.sh > install.sh
cat install.sh # review
bash install.sh # run when satisfied
rm install.sh
Windows (PowerShell)
git clone --depth 1 https://github.com/AgriciDaniel/claude-seo.git
powershell -ExecutionPolicy Bypass -File claude-seo\install.ps1
为什么使用 git clone 而不是
irm | iex? Claude Code 自身的安全防护机制会将irm ... | iex标记为供应链风险(下载并执行未经验证的远程代码)。git clone 方法允许您在运行之前在claude-seo\install.ps1检查脚本。
快速开始
# Start Claude Code
claude
# Run a full site audit
/seo audit https://example.com
# Analyze a single page
/seo page https://example.com/about
# Check schema markup
/seo schema https://example.com
# Generate a sitemap
/seo sitemap generate
# Optimize for AI search
/seo geo https://example.com
演示:
/seo audit:带有并行子代理的完整站点审计:
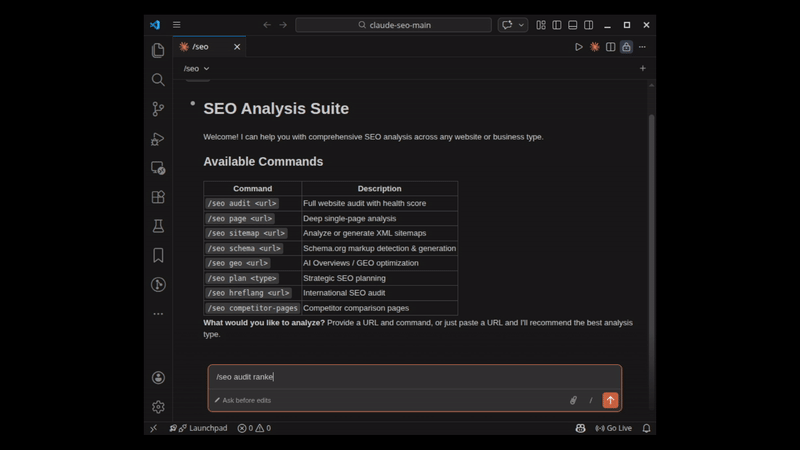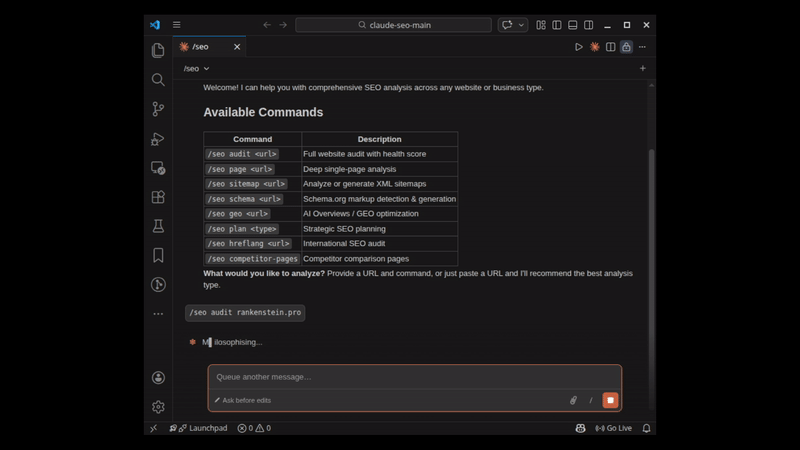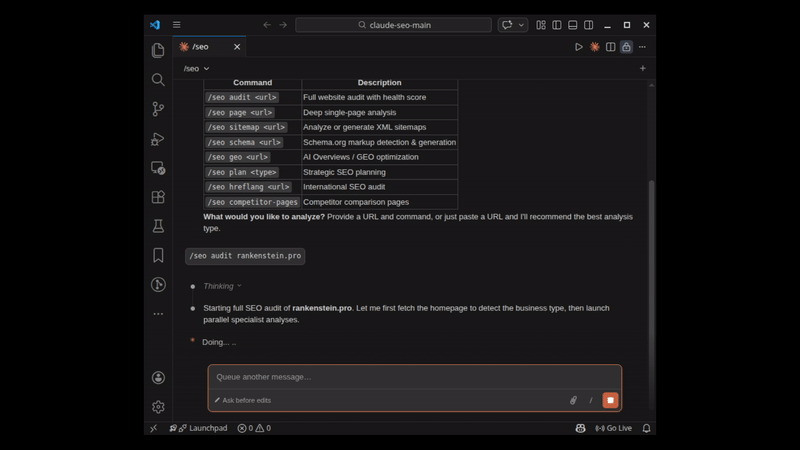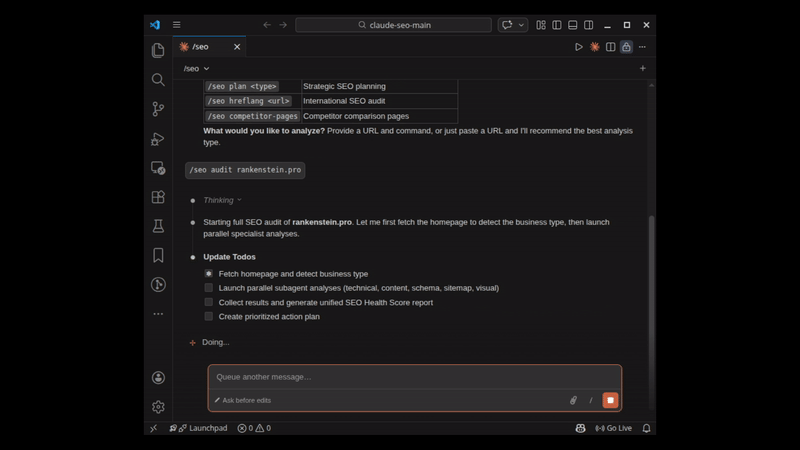
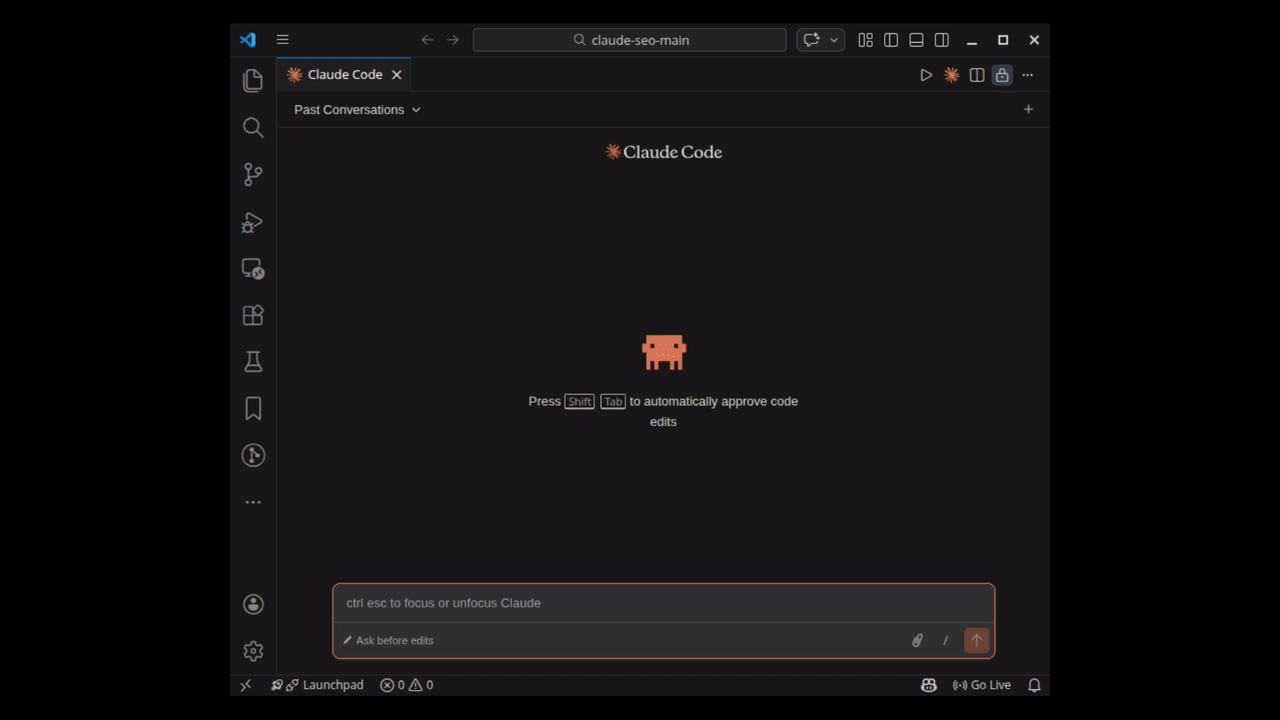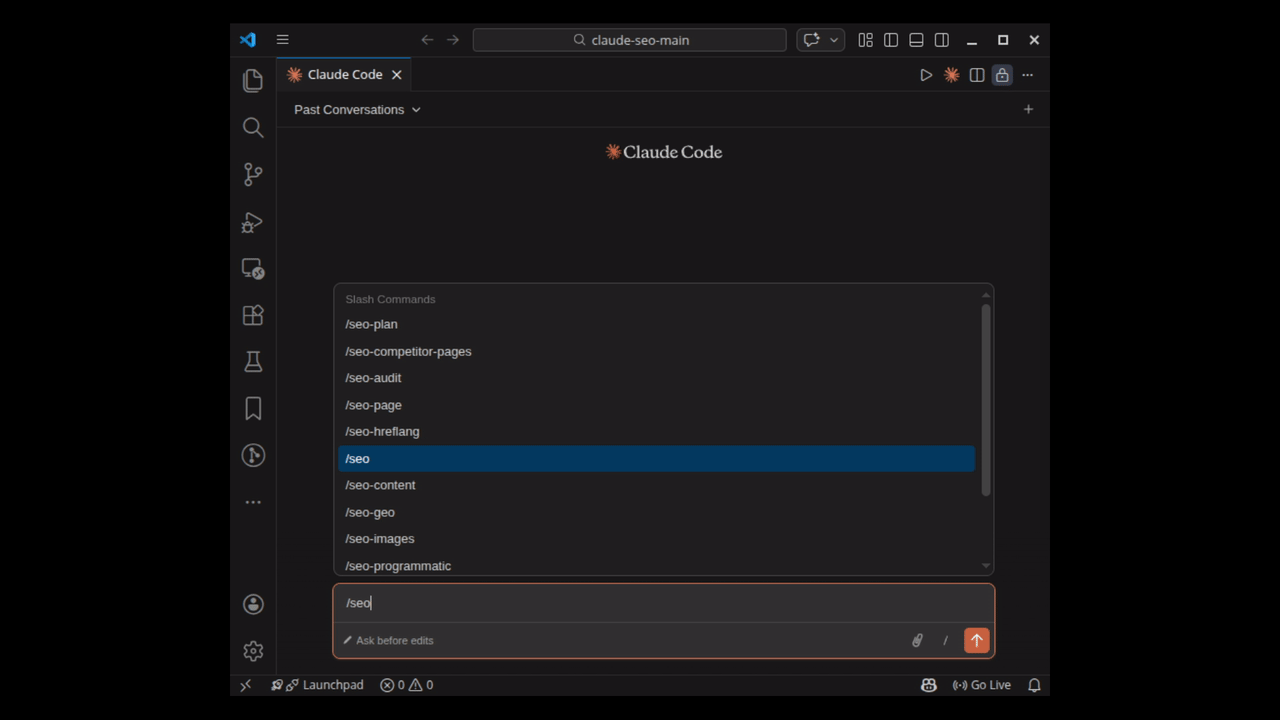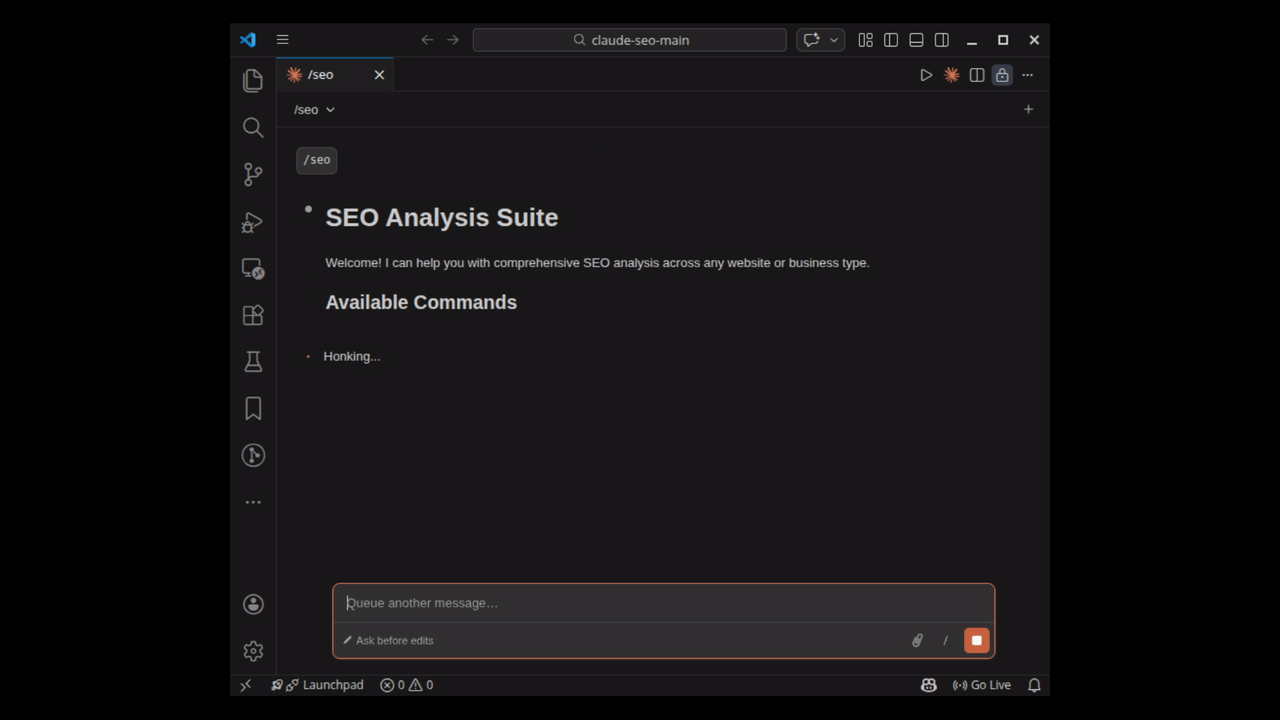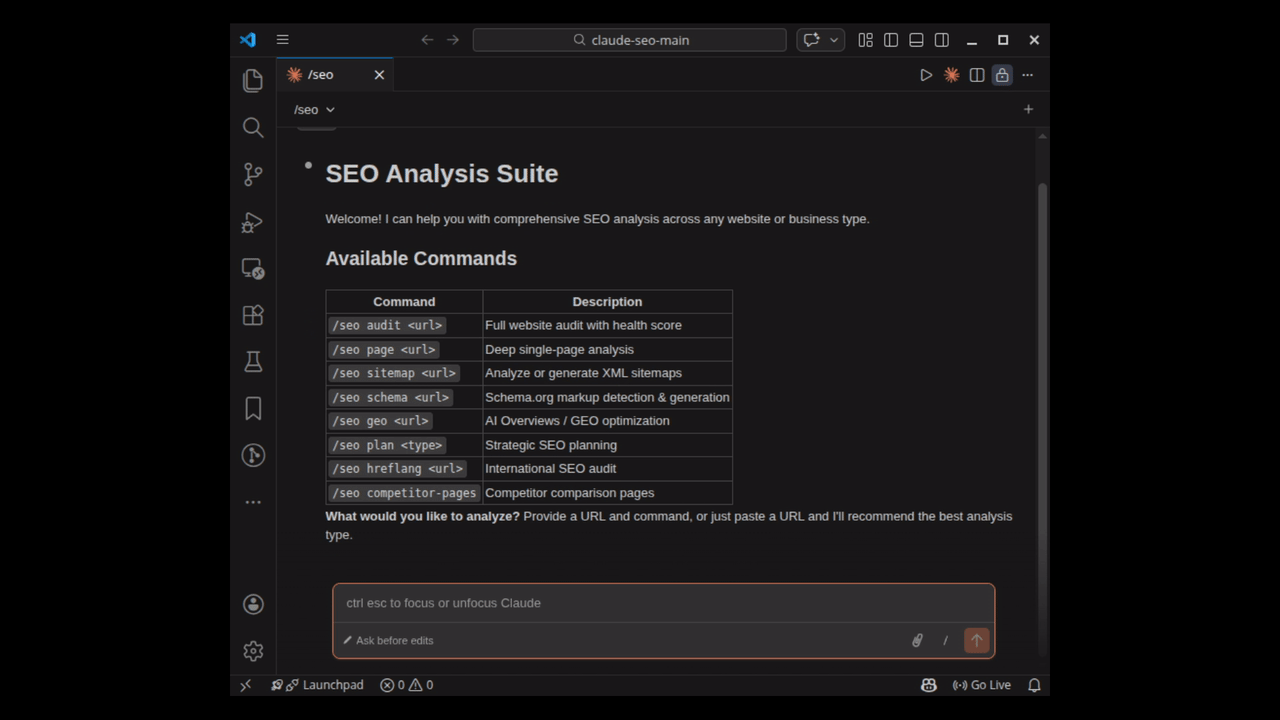
命令
| 命令 | 描述 |
|---|---|
/seo audit <url> |
带有并行子代理委派的完整网站审计 |
/seo page <url> |
深度单页分析 |
/seo sitemap <url> |
分析现有的 XML 站点地图 |
/seo sitemap generate |
使用行业模板生成新的站点地图 |
/seo schema <url> |
检测、验证和生成 Schema.org 标记 |
/seo images <url> |
图片优化分析 |
/seo technical <url> |
技术 SEO 审计(9 个类别) |
/seo content <url> |
E-E-A-T 和内容质量分析 |
/seo geo <url> |
AI 概览 / 生成式引擎优化 (GEO) |
/seo plan <type> |
战略 SEO 规划 (saas, local, ecommerce, publisher, agency) |
/seo programmatic <url> |
程序化 SEO 分析和规划 |
/seo competitor-pages <url> |
竞争对手对比页面生成 |
/seo hreflang <url> |
Hreflang/i18n SEO 审计和生成 |
/seo programmatic [url|plan]
程序化 SEO 分析与规划
从数据源大规模构建 SEO 页面,同时具备质量保障。
能力:
- 分析现有程序化页面的低质内容和关键词冲突
- 规划数据驱动页面的 URL 模式和模板结构
- 生成页面之间的内部链接自动化
- 规范链接策略和防止索引膨胀
- 质量门禁:100+ 页面时警告,500+ 页面未审计时强制停止
/seo competitor-pages [url|generate]
竞争对手对比页面生成器
创建高转化率的"X vs Y"和"X 的替代品”页面。
能力:
- 带有功能矩阵的结构化对比表格
- 带有聚合评分 (AggregateRating) 的产品 Schema 标记
- 带有 CTA 放置的转化优化布局
- 针对对比意图查询的关键词定位
- 准确代表竞争对手的公平性指南
/seo hreflang [url]
Hreflang / 国际化 (i18n) SEO 审计与生成
验证和生成多语言网站的 hreflang 标签。
能力:
- 生成 hreflang 标签(HTML、HTTP 头或 XML 站点地图)
- 验证自引用标签、返回标签、x-default
- 检测常见错误(缺少返回、无效代码、HTTP/HTTPS 不匹配)
- 跨域 hreflang 支持
- 语言/地区代码验证 (ISO 639-1 + ISO 3166-1)
功能特性
核心网页指标 (当前标准)
- LCP (Largest Contentful Paint,最大内容绘制):目标 < 2.5 秒
- INP (Interaction to Next Paint,下一次绘制的交互时间):目标 < 200 毫秒
- CLS (Cumulative Layout Shift,累积布局偏移):目标 < 0.1
注意:INP 于 2024 年 3 月 12 日取代了 FID。FID 已于 2024 年 9 月 9 日从所有 Chrome 工具中完全移除。
E-E-A-T 分析
更新至 2025 年 9 月的质量评估员指南:
- Experience (经验):第一手知识信号
- Expertise (专业度):作者资历和深度
- Authoritativeness (权威性):行业认可
- Trustworthiness (可信度):联系信息、安全性、透明度
Schema 标记
- 检测:JSON-LD(首选)、Microdata、RDFa
- 对照 Google 支持的类型进行验证
- 使用模板生成
- 弃用意识:
- HowTo:已弃用 (2023 年 9 月)
- FAQ:仅限于政府/健康网站 (2023 年 8 月)
- SpecialAnnouncement:已弃用 (2025 年 7 月)
AI 搜索优化 (GEO)
2026 年新特性 - 优化以下平台:
- Google AI 概览
- ChatGPT 网络搜索
- Perplexity
- 其他 AI 驱动的搜索
质量门禁
- 30+ 位置页面时警告
- 50+ 位置页面时强制停止
- 按页面类型检测低质内容
- 防止门页 (Doorway page)
架构
~/.claude/skills/seo/ # Main skill
~/.claude/skills/seo-*/ # Sub-skills (12 total)
~/.claude/agents/seo-*.md # Subagents (7 total)
视频与直播 Schema(结构化数据)(新增)
适用于视频内容、直播和关键片段的附加 Schema 类型:
- VideoObject:带有缩略图、时长、上传日期的视频页面标记
- BroadcastEvent:支持直播内容的 LIVE 徽章
- Clip:视频内的关键片段/章节
- SeekToAction:在视频富结果中启用跳转功能
- SoftwareSourceCode:开源和代码仓库页面
查看 schema/templates.json 获取开箱即用的 JSON-LD(关联数据格式)片段。
最近添加
- 程序化 SEO 技能 (
/seo programmatic) - 竞争对手对比页面技能 (
/seo competitor-pages) - 多语言 hreflang 验证 (
/seo hreflang) - 视频与直播 Schema 类型 (VideoObject, BroadcastEvent, Clip, SeekToAction)
- Google SEO 快速参考指南
要求
- Python 3.10+
- Claude Code CLI(命令行界面)
- 可选:Playwright 用于截图
卸载
git clone --depth 1 https://github.com/AgriciDaniel/claude-seo.git
bash claude-seo/uninstall.sh
单行命令 (curl)
curl -fsSL https://raw.githubusercontent.com/AgriciDaniel/claude-seo/main/uninstall.sh | bash
MCP(模型上下文协议)集成
与 MCP 服务器集成以获取实时 SEO 数据,包括来自 Ahrefs (@ahrefs/mcp) 和 Semrush 的官方服务器,以及用于 Google Search Console、PageSpeed Insights 和 DataForSEO 的社区服务器。查看 MCP 集成指南 了解设置方法。
扩展
通过 MCP 服务器集成外部数据源的可选附加组件。
DataForSEO
实时 SERP(搜索结果页)数据、关键词研究、反向链接、页面分析、内容分析、商业列表、AI 可见性检查和 LLM(大语言模型)提及追踪。涵盖 9 个 API 模块的 22 条命令。
# Install (requires DataForSEO account)
./extensions/dataforseo/install.sh
# Example commands
/seo dataforseo serp best coffee shops
/seo dataforseo keywords seo tools
/seo dataforseo backlinks example.com
/seo dataforseo ai-mentions your brand
/seo dataforseo ai-scrape your brand name
查看 DataForSEO 扩展 获取完整文档。
Banana(AI 图像生成)
使用 Claude Banana 创意总监管道生成 SEO 图像(OG(Open Graph)预览、博客头图、产品照片、信息图表)。
# Install extension
./extensions/banana/install.sh
# Example commands
/seo image-gen og "Professional SaaS dashboard"
/seo image-gen hero "AI-powered content creation"
/seo image-gen batch "Product photography" 3
查看 Banana 扩展 获取完整文档。 已经在使用独立的 Claude Banana?该扩展将重用您现有的 nanobanana-mcp 设置。
生态系统
Claude SEO 是协同工作的 Claude Code 技能家族的一部分:
| Skill | What it does | How it connects |
|---|---|---|
| Claude SEO | SEO 分析、审计、Schema(结构化数据)、GEO(生成式引擎优化) | Core -- 分析网站,生成行动计划 |
| Claude Blog | 博客写作、优化、评分 | Companion -- 编写基于 SEO 发现优化的内容 |
| Claude Banana | 通过 Gemini 进行 AI 图像生成 | Shared -- 为 SEO 资产和博客文章生成图像 |
工作流示例:
/seo audit https://example.com-- 识别内容缺口和图像问题/blog write "target keyword"-- 创建 SEO 优化的博客文章/seo image-gen hero "blog topic"-- 生成头图(banana 扩展)/seo geo https://example.com/blog/post-- 针对 AI 引用进行优化
文档
许可证
MIT 许可证 - 详见 LICENSE。
贡献
欢迎贡献!请在提交 PR(拉取请求)前阅读 CONTRIBUTING.md。
专为 Claude Code 打造,作者 @AgriciDaniel
版本历史
v1.8.02026/04/01v1.7.22026/03/30v1.7.12026/03/30v1.7.02026/03/28v1.6.12026/03/27v1.6.02026/03/23v1.5.02026/03/16v1.4.02026/03/12v1.3.02026/03/06v1.2.02026/02/19常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。
crawl4ai
Crawl4AI 是一款专为大语言模型(LLM)设计的开源网络爬虫与数据提取工具。它的核心使命是将纷繁复杂的网页内容转化为干净、结构化的 Markdown 格式,直接服务于检索增强生成(RAG)、智能体构建及各类数据管道,让 AI 能更轻松地“读懂”互联网。 传统爬虫往往面临反爬机制拦截、动态内容加载困难以及输出格式杂乱等痛点,导致后续数据处理成本高昂。Crawl4AI 通过内置自动化的三级反机器人检测、代理升级策略以及对 Shadow DOM 的深度支持,有效突破了这些障碍。它能智能移除同意弹窗,处理深层链接,并具备长任务崩溃恢复能力,确保数据采集的稳定与高效。 这款工具特别适合开发者、AI 研究人员及数据工程师使用。无论是需要为本地模型构建知识库,还是搭建大规模自动化信息采集流程,Crawl4AI 都提供了极高的可控性与灵活性。作为 GitHub 上备受瞩目的开源项目,它完全免费开放,无需繁琐的注册或昂贵的 API 费用,让用户能够专注于数据价值本身而非采集难题。
meilisearch
Meilisearch 是一个开源的极速搜索服务,专为现代应用和网站打造,开箱即用。它能帮助开发者快速集成高质量的搜索功能,无需复杂的配置或额外的数据预处理。传统搜索方案往往需要大量调优才能实现准确结果,而 Meilisearch 内置了拼写容错、同义词识别、即时响应等实用特性,并支持 AI 驱动的混合搜索(结合关键词与语义理解),显著提升用户查找信息的体验。 Meilisearch 特别适合 Web 开发者、产品团队或初创公司使用,尤其适用于需要快速上线搜索功能的场景,如电商网站、内容平台或 SaaS 应用。它提供简洁的 RESTful API 和多种语言 SDK,部署简单,资源占用低,本地开发或生产环境均可轻松运行。对于希望在不依赖大型云服务的前提下,为用户提供流畅、智能搜索体验的团队来说,Meilisearch 是一个高效且友好的选择。
Made-With-ML
Made-With-ML 是一个面向实战的开源项目,旨在帮助开发者系统掌握从设计、开发到部署和迭代生产级机器学习应用的完整流程。它解决了许多人在学习机器学习时“会训练模型但不会上线”的痛点,强调将软件工程最佳实践与 ML 技术结合,构建可靠、可维护的端到端系统。 该项目特别适合三类人群:一是希望将模型真正落地的开发者(包括软件工程师、数据科学家);二是刚毕业、想补齐工业界所需技能的学生;三是需要理解技术边界以更好推动产品的技术管理者或产品经理。 Made-With-ML 的亮点在于注重第一性原理讲解,避免盲目调包;同时覆盖 MLOps 关键环节(如实验跟踪、模型测试、服务部署、CI/CD 等),并支持在 Python 生态内平滑扩展训练与推理任务,无需切换语言或复杂基础设施。课程内容结构清晰,配有详细代码示例和视频导览,兼顾理论深度与工程实用性。