data-augmentation-review
data-augmentation-review 是一个开源资源库,系统整理了数据增强领域的实用链接,涵盖计算机视觉、自然语言处理、音频、时间序列、图数据及基因表达等多场景。它解决了AI从业者在寻找高效、创新数据增强技术时的痛点——资源分散且常忽略小众方法,比如偏见缓解的Targeted Data Augmentation(通过插入偏见提升模型公平性)。这个库不仅包含GitHub仓库、开源库和论文,还特别收录了2015-2023年的前沿研究,覆盖从基础变换到神经网络生成的多样化技术。适合AI开发者和机器学习研究人员快速获取高质量资源,无需在海量信息中摸索。无论是优化图像识别模型、处理语音数据,还是提升NLP任务的鲁棒性,都能从中高效找到实用工具。欢迎贡献和维护,共同完善这个社区驱动的资源宝库。
使用场景
某医疗科技公司正在开发一个基于深度学习的医学影像诊断系统,用于辅助医生识别肺部CT图像中的结节。由于实际标注数据有限,团队需要寻找高效的数据增强方法来扩充训练集。
没有 data-augmentation-review 时
- 团队成员只能依赖常见的数据增强方法(如旋转、缩放、翻转等),难以找到针对医学影像的特殊增强技术。
- 缺乏对最新研究论文和开源库的系统性了解,导致无法快速尝试前沿算法。
- 需要手动搜索多个资源平台,浪费大量时间在信息筛选上。
- 对于如何处理小样本下的数据增强策略缺乏指导,影响模型泛化能力。
使用 data-augmentation-review 后
- 获得了一份结构清晰的增强资源列表,包括专门针对医学影像的增强方法和工具,如弹性变形、对比度调整等。
- 快速定位到最新的相关论文(如2023年关于偏见缓解的Targeted Data Augmentation)并参考其方法优化数据分布。
- 直接访问推荐的GitHub项目和代码库,节省了大量查找和验证的时间。
- 借助“AutoAugment”部分提供的自动增强策略,提升了模型在小样本情况下的性能表现。
数据增强的效率和质量显著提升,帮助团队更快构建出更鲁棒的医学影像诊断模型。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
![]()
正在寻找愿意帮助我维护这个仓库的朋友!欢迎通过LinkedIn联系我,或者直接提交一个PR!
数据增强
这里列出了许多有用的数据增强资源。你会找到一些或多或少流行的GitHub仓库 :sparkles:、库、论文 :books: 以及其他相关信息。
喜欢这个项目吗?别忘了给它点个赞 :star:!也欢迎随时提交Pull Request!
精选 ⭐
用于缓解偏见的数据增强?
- 针对偏见缓解的定向数据增强;Agnieszka Mikołajczyk-Bareła, Maria Ferlin, Michał Grochowski;开发公平且合乎伦理的人工智能系统需要仔细考虑偏见缓解问题,而这一领域往往被忽视或忽略。在本研究中,我们提出了一种新颖且高效的方法来解决偏见问题,称为定向数据增强(TDA),该方法利用经典的数据增强技术来应对数据和模型中存在的紧迫偏见问题。与费力地消除偏见不同,我们的方法建议反而引入偏见,从而提升性能。(...)
简介
数据增强可以简单地描述为任何通过创建现有数据集的修改副本,从而使数据集规模扩大的方法。例如,为了生成更多的图像,我们可以放大并保存结果,改变图像的亮度或旋转图像。若要获得更大的音频数据集,我们可以尝试提高或降低音频样本的音高,或者加快/减慢播放速度。 下图展示了典型的数据增强技术示例。
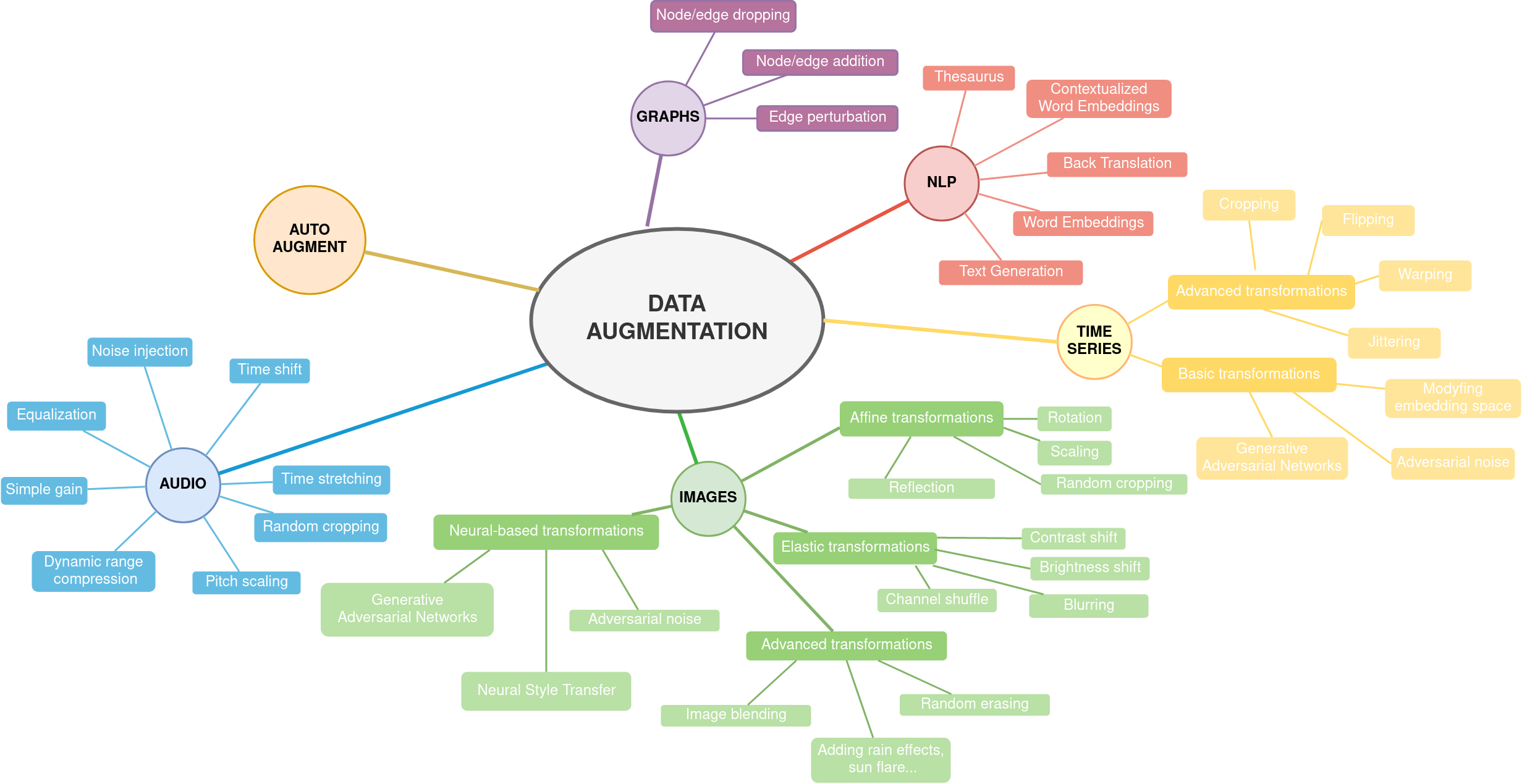
数据增强
图像增强
- 仿射变换
- 旋转
- 缩放
- 随机裁剪
- 反射
- 弹性变换
- 对比度调整
- 亮度调整
- 模糊化
- 通道洗牌
- 高级变换
- 随机擦除
- 添加雨效、光晕等效果
- 图像混合
- 基于神经网络的变换
- 对抗噪声
- 神经风格迁移
- 生成对抗网络
- 仿射变换
音频增强
- 噪声注入
- 时间偏移
- 时间拉伸
- 随机裁剪
- 音高缩放
- 动态范围压缩
- 简单增益
- 均衡器
- 语音转换(语音)
自然语言处理增强
- 同义词词典
- 文本生成
- 反向翻译
- 词嵌入
- 上下文感知词嵌入
- 同义改写
- 文本扰动
时间序列数据增强
- 基础方法
- 变形
- 抖动
- 扰动
- 进阶方法
- 嵌入空间
- GAN/对抗式
- RL/元学习
- 基础方法
图数据增强
- 节点/边删除
- 节点/边添加(图修改)
- 边扰动
基因表达数据增强
- 使用GAN生成数据
- 观测值混合
- 随机变量插入
自动数据增强(AutoAugment)
- 其他
- 关键点/地标增强 - 通常使用图像增强方法(旋转、反射)或图数据增强方法(节点/边删除)进行
- 光谱图/梅尔谱图 - 通常使用时间序列数据增强方法(抖动、扰动、变形)或图像增强方法(随机擦除)进行
如果你想引用我们,可以选择以下任意一篇论文:基于风格迁移的图像合成作为深度学习中的高效正则化技术 或 用于改进图像分类问题中深度学习的数据增强。

仓库
计算机视觉
- albumentations  是一个Python库,提供了一系列实用、丰富且多样化的数据增强方法。它支持超过30种不同的增强类型,易于使用且开箱即用。此外,作者证明该库在大多数变换上都比其他库更快。
是一个Python库,提供了一系列实用、丰富且多样化的数据增强方法。它支持超过30种不同的增强类型,易于使用且开箱即用。此外,作者证明该库在大多数变换上都比其他库更快。
示例Jupyter笔记本:
示例变换:
- imgaug  - 是另一个非常实用且广泛使用的 Python 库。正如作者所描述的:它可以帮助你为机器学习项目增强图像数据,将一组输入图像转换成一个更大、包含许多轻微变化的新图像集。 该库提供了多种数据增强技术,例如仿射变换、透视变换、对比度调整、高斯噪声、区域丢弃、色调/饱和度变化、裁剪/填充以及模糊等。
- 是另一个非常实用且广泛使用的 Python 库。正如作者所描述的:它可以帮助你为机器学习项目增强图像数据,将一组输入图像转换成一个更大、包含许多轻微变化的新图像集。 该库提供了多种数据增强技术,例如仿射变换、透视变换、对比度调整、高斯噪声、区域丢弃、色调/饱和度变化、裁剪/填充以及模糊等。
示例 Jupyter 笔记本:
示例变换:

- Kornia  - 是一个面向 PyTorch 的可微分计算机视觉库。它由一系列用于解决通用计算机视觉问题的函数和可微模块组成。该库的核心使用 PyTorch 作为主要后端,既为了提高效率,也为了利用反向模式自动微分来定义和计算复杂函数的梯度。
- 是一个面向 PyTorch 的可微分计算机视觉库。它由一系列用于解决通用计算机视觉问题的函数和可微模块组成。该库的核心使用 PyTorch 作为主要后端,既为了提高效率,也为了利用反向模式自动微分来定义和计算复杂函数的梯度。
从更细粒度的角度来看,Kornia 包含以下组件:
| 组件 | 描述 |
|---|---|
| kornia | 一个具有强大 GPU 支持的可微分计算机视觉库 |
| kornia.augmentation | 一个在 GPU 上执行数据增强的模块 |
| kornia.color | 一组用于颜色空间转换的函数 |
| kornia.contrib | 用户贡献及实验性算子的集合 |
| kornia.enhance | 一个用于归一化和强度变换的模块 |
| kornia.feature | 一个用于特征检测的模块 |
| kornia.filters | 一个用于图像滤波和边缘检测的模块 |
| kornia.geometry | 一个几何计算机视觉库,可用于图像变换、三维线性代数操作以及不同相机模型之间的转换 |
| kornia.losses | 一系列用于解决不同视觉任务的损失函数 |
| kornia.morphology | 一个用于形态学操作的模块 |
| kornia.utils | 图像转张量工具及视觉问题相关的度量指标 |

- UDA  - 是一种简单的图像文件数据增强工具,专为机器学习数据集设计。该工具会扫描包含图像文件的目录,并对每个找到的文件执行指定的一组增强操作,从而生成新的图像。这一过程可以显著增加用于训练神经网络的样本数量,并有望大幅提高最终模型的性能,尤其是在训练样本较少的情况下。
- 是一种简单的图像文件数据增强工具,专为机器学习数据集设计。该工具会扫描包含图像文件的目录,并对每个找到的文件执行指定的一组增强操作,从而生成新的图像。这一过程可以显著增加用于训练神经网络的样本数量,并有望大幅提高最终模型的性能,尤其是在训练样本较少的情况下。
详细信息请参阅:无监督数据增强用于一致性训练
- 目标检测的数据增强  - 该仓库包含了论文《关于如何将数据增强方法应用于目标检测任务的空间教程系列》中的代码(链接:https://blog.paperspace.com/data-augmentation-for-bounding-boxes/)。他们支持多种数据增强技术,如水平翻转、缩放、平移、旋转、剪切和调整大小。
- 该仓库包含了论文《关于如何将数据增强方法应用于目标检测任务的空间教程系列》中的代码(链接:https://blog.paperspace.com/data-augmentation-for-bounding-boxes/)。他们支持多种数据增强技术,如水平翻转、缩放、平移、旋转、剪切和调整大小。

- FMix - 理解与增强混合样本数据增强  本仓库包含论文《理解与增强混合样本数据增强》的官方实现,该论文发表于 https://arxiv.org/abs/2002.12047。
本仓库包含论文《理解与增强混合样本数据增强》的官方实现,该论文发表于 https://arxiv.org/abs/2002.12047。

- Super-AND  - 本仓库是基于 AND 算法的无监督嵌入学习综合方法的 PyTorch 实现。
- 本仓库是基于 AND 算法的无监督嵌入学习综合方法的 PyTorch 实现。

- vidaug  - 这是一个 Python 库,用于为深度学习模型增强视频数据。它将输入视频转换成一组数量更多、略有变化的新视频。
- 这是一个 Python 库,用于为深度学习模型增强视频数据。它将输入视频转换成一组数量更多、略有变化的新视频。

- Image augmentor  - 这是一个简单的 Python 数据增强工具,专为图像文件设计,适用于机器学习数据集。该工具会扫描包含图像文件的目录,并对每个文件执行指定的增强操作以生成新图像。这一过程可以显著增加神经网络训练时可用的样本数量,从而提升模型性能,尤其是在训练样本较少的情况下。
- 这是一个简单的 Python 数据增强工具,专为图像文件设计,适用于机器学习数据集。该工具会扫描包含图像文件的目录,并对每个文件执行指定的增强操作以生成新图像。这一过程可以显著增加神经网络训练时可用的样本数量,从而提升模型性能,尤其是在训练样本较少的情况下。
- torchsample  - 这个 Python 包提供针对 PyTorch 的高级训练、数据增强及实用工具。该工具箱包括数据增强方法、正则化器及其他辅助函数。这些变换直接作用于 PyTorch 张量:
- 这个 Python 包提供针对 PyTorch 的高级训练、数据增强及实用工具。该工具箱包括数据增强方法、正则化器及其他辅助函数。这些变换直接作用于 PyTorch 张量:
- Compose()
- AddChannel()
- SwapDims()
- RangeNormalize()
- StdNormalize()
- Slice2D()
- RandomCrop()
- SpecialCrop()
- Pad()
- RandomFlip()
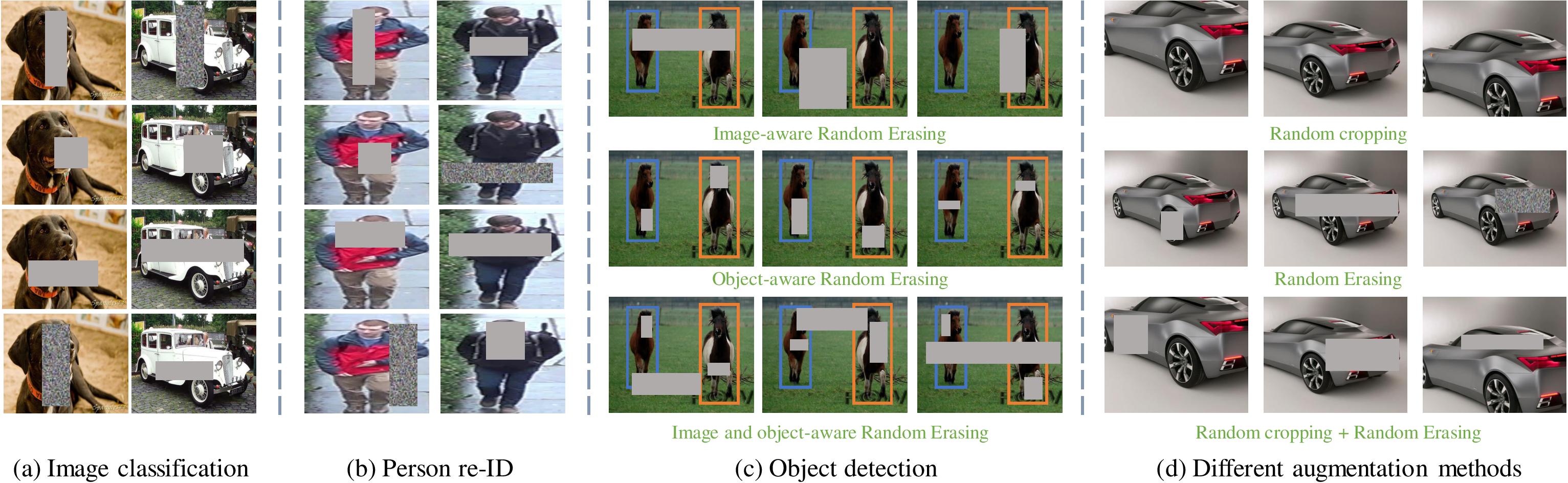
- Random erasing  - 代码基于论文:https://arxiv.org/abs/1708.04896。摘要如下:
- 代码基于论文:https://arxiv.org/abs/1708.04896。摘要如下:
本文提出了一种名为“随机擦除”的新型数据增强方法,用于训练卷积神经网络(CNN)。在训练过程中,随机擦除会随机选择图像中的一个矩形区域,并用随机值将其像素擦除。通过这种方式,可以生成具有不同遮挡程度的训练图像,从而降低过拟合风险并提高模型对遮挡的鲁棒性。随机擦除无需参数学习,易于实现,且可与大多数基于 CNN 的识别模型集成。尽管简单,但随机擦除能够与常用的随机裁剪和翻转等数据增强技术互补,在图像分类、目标检测和行人重识别任务中均能带来稳定的性能提升。代码可在以下网址获取:this https URL。
- C++ 中的数据增强 -  一个简单的图像增强程序,通过对输入图像进行旋转、平移、模糊和噪声处理,生成用于图像识别的训练数据。
一个简单的图像增强程序,通过对输入图像进行旋转、平移、模糊和噪声处理,生成用于图像识别的训练数据。
- 使用 GAN 进行数据增强  - 本仓库包含生成对抗网络的相关文件,可用于成功扩充数据集。这是对 https://arxiv.org/abs/1711.04340 中描述的 DAGAN 模型的实现。该实现提供了用于 Omniglot 和 VGG-Face 数据集的数据加载器、模型构建器、模型训练器以及合成数据生成器。
- 本仓库包含生成对抗网络的相关文件,可用于成功扩充数据集。这是对 https://arxiv.org/abs/1711.04340 中描述的 DAGAN 模型的实现。该实现提供了用于 Omniglot 和 VGG-Face 数据集的数据加载器、模型构建器、模型训练器以及合成数据生成器。
- 联合判别与生成学习  - 本仓库用于行人重识别领域的联合判别与生成学习(CVPR2019 口头报告)。作者提出了一种端到端训练网络,该网络能够同时生成更多的训练样本并进行表征学习。给定 N 个真实样本,该网络可以生成 O(N×N) 个高保真度的样本。
- 本仓库用于行人重识别领域的联合判别与生成学习(CVPR2019 口头报告)。作者提出了一种端到端训练网络,该网络能够同时生成更多的训练样本并进行表征学习。给定 N 个真实样本,该网络可以生成 O(N×N) 个高保真度的样本。
 [项目] [论文] [YouTube] [Bilibili] [海报]
[补充材料]
[项目] [论文] [YouTube] [Bilibili] [海报]
[补充材料]
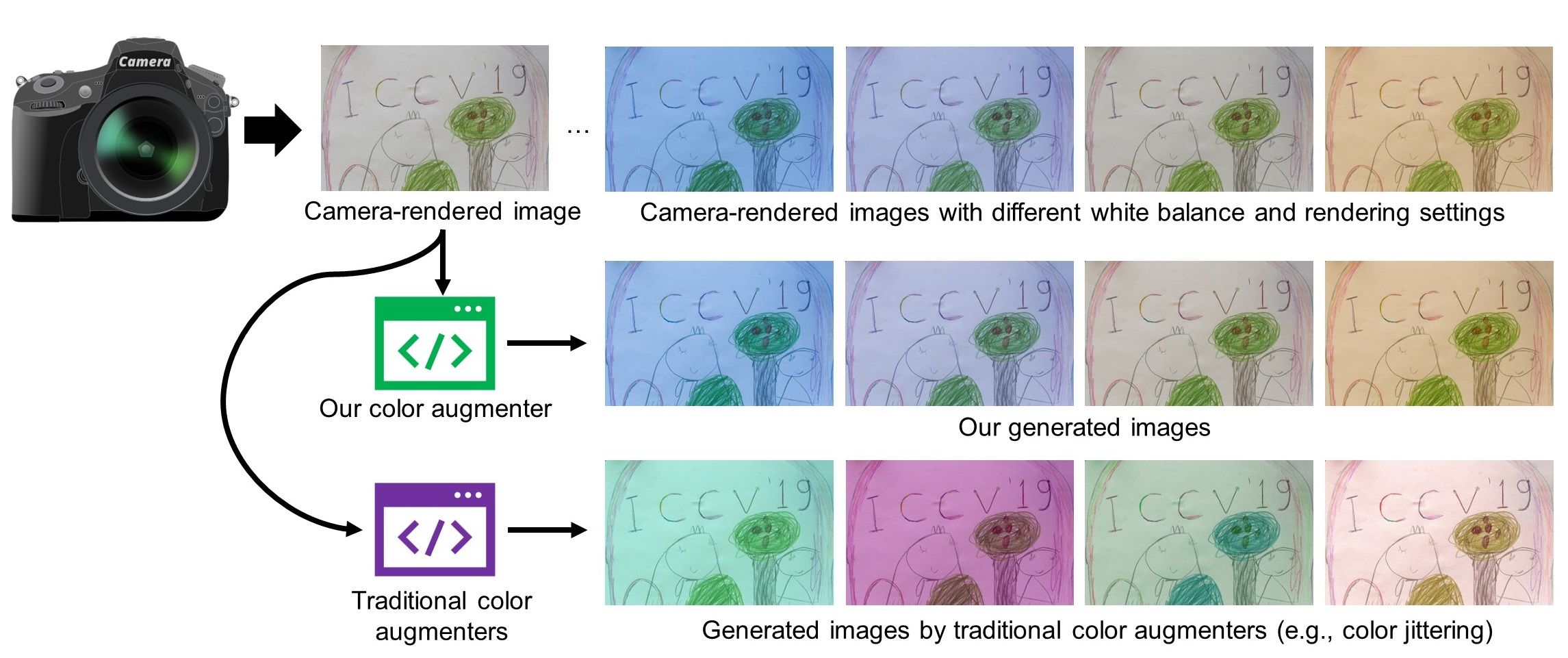
- 白平衡模拟器用于颜色增强  - 我们的增强方法能够准确模拟真实的色彩恒常性退化。现有的颜色增强方法往往会产生现实中很少出现的不自然色彩(例如绿色皮肤或紫色草地)。更重要的是,现有颜色增强技术的视觉效果并不能很好地反映相机上错误白平衡设置所导致的色偏,如下所示。[python] [matlab]
- 我们的增强方法能够准确模拟真实的色彩恒常性退化。现有的颜色增强方法往往会产生现实中很少出现的不自然色彩(例如绿色皮肤或紫色草地)。更重要的是,现有颜色增强技术的视觉效果并不能很好地反映相机上错误白平衡设置所导致的色偏,如下所示。[python] [matlab]
- DocCreator (OCR)  - 是一款开源跨平台软件,可用于生成合成文档图像及其对应的标注真值。用户可以对原始文档图像应用多种退化模型,从而创建几乎无限数量的不同图像。
- 是一款开源跨平台软件,可用于生成合成文档图像及其对应的标注真值。用户可以对原始文档图像应用多种退化模型,从而创建几乎无限数量的不同图像。
一款多平台、开源的软件,能够生成带有标注真值的合成文档图像。
- OnlineAugment  - 基于PyTorch的实现
- 基于PyTorch的实现
- 比AutoAugment及相关方法更自动化
- 朝着完全自动化的方向发展(使用STN和VAE,无需指定图像基元)。
- 适用领域广泛(自然图像、医学图像等)。
- 任务多样(分类、分割等)。
- 易于使用
- 一步式训练(用户友好)。
- 代码简洁(单GPU训练,无需并行优化)。
- 与AutoAugment及其相关方法正交
- 在线与离线(联合优化,无需昂贵的离线策略搜索)。
- 与AutoAugment结合时可达到最先进性能。

- Augraphy (OCR)  - 是一个Python库,通过增强管道随机扭曲原始文档的多个副本,从而将干净版本降级为脏乱且逼真的副本,这些副本模拟了合成纸张打印、传真、扫描和复印机处理过程。
- 是一个Python库,通过增强管道随机扭曲原始文档的多个副本,从而将干净版本降级为脏乱且逼真的副本,这些副本模拟了合成纸张打印、传真、扫描和复印机处理过程。

- 针对GAN优化的数据增强(DAG)  - 基于PyTorch和TensorFlow的实现
- 基于PyTorch和TensorFlow的实现
DAG-GAN提供了在PyTorch和TensorFlow中DAG模块的简单实现,可以轻松集成到任何GAN模型中以提升性能,尤其是在数据有限的情况下。我们仅展示了论文中讨论的一些增强技术(旋转、裁剪、翻转等),但我们的DAG并不局限于这些增强方法。使用的增强越多,DAG对GAN模型的改进效果越好。此外,在模块内设计自己的增强方法也非常容易。然而,在DAG中使用的增强数量与计算成本之间可能存在权衡。
- 无监督数据增强(google-research/uda) - 基于TensorFlow的实现。
无监督数据增强或UDA是一种半监督学习方法,在多种语言和视觉任务上均取得了最先进的结果。仅使用20个标注样本,UDA在IMDb上的表现就超过了之前使用25,000个标注样本训练的最先进方法。
他们发布了以下内容:
- 基于BERT的文本分类代码。
- CIFAR-10和SVHN上的图像分类代码。
- 我们的反向翻译增强系统的代码和检查点。
- AugLy  - AugLy是一个数据增强库,目前支持四种模态(音频、图像、文本和视频)以及超过100种增强方法。
- AugLy是一个数据增强库,目前支持四种模态(音频、图像、文本和视频)以及超过100种增强方法。
每种模态的增强都包含在其各自的子库中。这些子库包括基于函数和基于类的变换、组合操作符,并且可以选择提供关于所应用变换的元数据,包括其强度。
AugLy是非常适合用于模型训练中数据增强,或者评估模型鲁棒性差距的优秀库!我们设计AugLy是为了包含许多用户在Facebook等互联网平台上实际执行的特定数据增强方法——例如将图片制作成表情包、在图片或视频上叠加文字/表情符号、转发社交媒体截图等。尽管AugLy也包含更通用的数据增强方法,但如果你正在处理诸如抄袭检测、仇恨言论检测或版权侵权等问题,而这些问题中经常出现这类“互联网用户”式的数据增强时,AugLy将特别有用。
- 使用DiffAugment的高效数据GAN  - 包含在PyTorch和TensorFlow中可微分增强(DiffAugment)的实现。
- 包含在PyTorch和TensorFlow中可微分增强(DiffAugment)的实现。
它可以显著提高GAN训练的数据效率。我们提供了DiffAugment-stylegan2(TensorFlow)、DiffAugment-stylegan2-pytorch以及DiffAugment-biggan-cifar(PyTorch)用于GPU训练,还有DiffAugment-biggan-imagenet(TensorFlow)用于TPU训练。

自然语言处理
- nlpaug  - 这个Python库可以帮助你为机器学习项目进行自然语言处理数据增强。请参阅这篇介绍,了解自然语言处理中的数据增强。
- 这个Python库可以帮助你为机器学习项目进行自然语言处理数据增强。请参阅这篇介绍,了解自然语言处理中的数据增强。Augmenter是增强的基本元素,而Flow则是将多个增强器协同工作的管道。
特点:
- 无需手动操作即可生成合成数据来提升模型性能
- 简单易用、轻量级的库。只需三行代码即可完成数据增强
- 可无缝接入任何神经网络框架(如PyTorch、TensorFlow)
- 支持文本和音频输入
- AugLy - AugLy是一个数据增强库,目前支持四种模态(音频、图像、文本和视频)以及超过100种增强方法。
每种模态的增强都包含在其各自的子库中。这些子库包括基于函数和基于类的变换、组合操作符,并且可以选择提供关于所应用变换的元数据,包括其强度。
AugLy 是一个非常棒的库,可用于在模型训练中增强数据,或评估模型的鲁棒性差距!我们设计 AugLy 时,纳入了许多用户在 Facebook 等互联网平台上实际执行的特定数据增强方法——例如将图片制作成表情包、在图片或视频上叠加文字/表情符号、转发社交媒体截图等。尽管 AugLy 也包含一些更通用的数据增强技术,但如果你正在处理诸如文本抄袭检测、仇恨言论识别或版权侵权等问题,而这些问题中这类“互联网用户”式的数据增强较为常见,那么 AugLy 将对你特别有用。
- TextAttack 🐙  - TextAttack 是一个用于自然语言处理领域对抗攻击、数据增强和模型训练的 Python 框架。
- TextAttack 是一个用于自然语言处理领域对抗攻击、数据增强和模型训练的 Python 框架。
TextAttack 的许多组件都可用于数据增强。textattack.Augmenter 类使用一种转换方法和一组约束条件来增强数据。我们还提供了五种内置的数据增强配方 来源:QData/TextAttack:
textattack.WordNetAugmenter通过用 WordNet 同义词替换单词来增强文本;textattack.EmbeddingAugmenter通过用反向词频嵌入空间中的邻近词替换单词来增强文本,并附加约束以确保它们的余弦相似度至少为 0.8;textattack.CharSwapAugmenter通过替换、删除、插入以及交换相邻字符来增强文本;textattack.EasyDataAugmenter结合单词插入、替换和删除来增强文本;textattack.CheckListAugmenter通过缩写/扩展以及替换人名、地点、数字来增强文本;textattack.CLAREAugmenter利用预训练的掩码语言模型进行替换、插入和合并操作来增强文本。
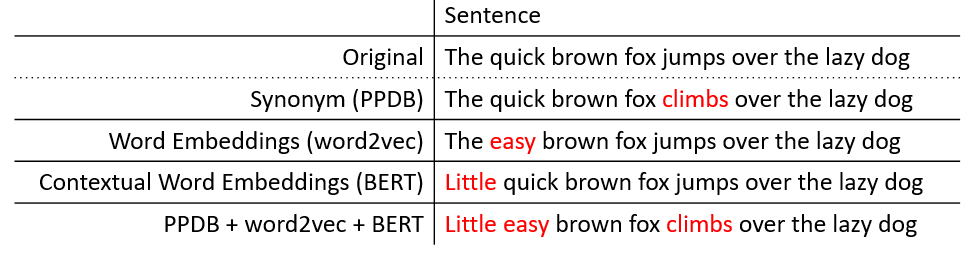
- EDA NLP  - EDA 是一种用于提升文本分类任务性能的 easy data augmentation 技术。这是一组易于实现且经过验证的通用数据增强技术,在五项 NLP 分类任务中均表现出色,尤其在数据量小于 500 的小型数据集上效果显著。与其他需要先在外部数据集上训练语言模型才能获得小幅提升的方法不同,我们发现仅使用 EDA 的简单文本编辑操作就能带来可观的性能提升。给定训练集中的一个句子,我们会执行以下操作:
- EDA 是一种用于提升文本分类任务性能的 easy data augmentation 技术。这是一组易于实现且经过验证的通用数据增强技术,在五项 NLP 分类任务中均表现出色,尤其在数据量小于 500 的小型数据集上效果显著。与其他需要先在外部数据集上训练语言模型才能获得小幅提升的方法不同,我们发现仅使用 EDA 的简单文本编辑操作就能带来可观的性能提升。给定训练集中的一个句子,我们会执行以下操作:
- 同义词替换(SR): 随机选择句子中 n 个非停用词,并将每个词随机替换为其同义词之一。
- 随机插入(RI): 找到句子中某个非停用词的一个随机同义词,将其插入到句子中的随机位置。重复此操作 n 次。
- 随机交换(RS): 随机选择句子中的两个单词并互换其位置。重复此操作 n 次。
- 随机删除(RD): 对句子中的每个单词,以概率 p 随机将其删除。
- NL-Augmenter 🦎 → 🐍  - NL-Augmenter 是一项协作项目,旨在为自然语言处理相关的数据集添加各种变换方法。这些变换可以从多种方式增强文本数据集,包括随机化姓名和数字、改变风格/语法、改写、基于知识库的改写……以及你贡献的任何创意性增强手段。我们诚邀大家通过 GitHub 拉取请求提交变换方法,截止日期为 2021 年 8 月 31 日。所有被采纳的变换方法(及过滤器)的提交者都将作为共同作者出现在宣布该框架的论文中。
- NL-Augmenter 是一项协作项目,旨在为自然语言处理相关的数据集添加各种变换方法。这些变换可以从多种方式增强文本数据集,包括随机化姓名和数字、改变风格/语法、改写、基于知识库的改写……以及你贡献的任何创意性增强手段。我们诚邀大家通过 GitHub 拉取请求提交变换方法,截止日期为 2021 年 8 月 31 日。所有被采纳的变换方法(及过滤器)的提交者都将作为共同作者出现在宣布该框架的论文中。
- 上下文数据增强  - 上下文数据增强是一种与领域无关的文本分类数据增强方法。在监督数据集中,文本中的单词会被标签条件下的双向语言模型预测出的其他单词所替换。
- 上下文数据增强是一种与领域无关的文本分类数据增强方法。在监督数据集中,文本中的单词会被标签条件下的双向语言模型预测出的其他单词所替换。
该仓库包含一系列用于 上下文数据增强 实验的脚本。

- 维基编辑  - 一套用于从文本编辑历史中自动提取已编辑句子的脚本,例如维基百科的修订记录。它曾被用来创建 WikEd 错误语料库——一个纠正性质的维基百科编辑语料库。该语料库已准备了波兰语和英语两种版本,可用作基于词典的增强方法,以插入用户引入的错误。
- 一套用于从文本编辑历史中自动提取已编辑句子的脚本,例如维基百科的修订记录。它曾被用来创建 WikEd 错误语料库——一个纠正性质的维基百科编辑语料库。该语料库已准备了波兰语和英语两种版本,可用作基于词典的增强方法,以插入用户引入的错误。
- 文本自动增强(TAA)  - 文本自动增强是一个可学习且可组合的 NLP 数据增强框架。其提出的算法能够自动搜索最优的组合策略,从而提升增强样本的多样性和质量。
- 文本自动增强是一个可学习且可组合的 NLP 数据增强框架。其提出的算法能够自动搜索最优的组合策略,从而提升增强样本的多样性和质量。
- 无监督数据增强(google-research/uda) - 基于 TensorFlow 的实现。
无监督数据增强,简称 UDA,是一种半监督学习方法,在多种语言和视觉任务中均取得了最先进的成果。仅需 20 个标注样本,UDA 就能超越之前在 IMDb 数据集上、使用 25,000 个标注样本训练的最先进方法。
他们发布了以下内容:
- 基于 BERT 的文本分类代码;
- 基于 CIFAR-10 和 SVHN 的图像分类代码;
- 用于反向翻译增强系统的代码和检查点。
音频
- SpecAugment with Pytorch  - (https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html) 是一种用于语音识别的先进数据增强方法。它支持时间扭曲、时间掩码、频率掩码以及上述所有组合的增强。
- (https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html) 是一种用于语音识别的先进数据增强方法。它支持时间扭曲、时间掩码、频率掩码以及上述所有组合的增强。

- Audiomentations  - 一个用于音频数据增强的 Python 库。灵感来源于 albumentations。对机器学习很有用。它允许使用诸如:Compose、AddGaussianNoise、TimeStretch、PitchShift 和 Shift 等效果。
- 一个用于音频数据增强的 Python 库。灵感来源于 albumentations。对机器学习很有用。它允许使用诸如:Compose、AddGaussianNoise、TimeStretch、PitchShift 和 Shift 等效果。
- MUDA  - 一个用于音乐数据增强的库。Muda 包实现了注释感知的音乐数据增强,正如 muda 论文中所述。
- 一个用于音乐数据增强的库。Muda 包实现了注释感知的音乐数据增强,正如 muda 论文中所述。
该包的目标是让从业者能够方便地对带注释的音乐数据持续应用扰动,以适应统计模型的训练需求。
- tsaug  -
-
是一个用于时间序列增强的 Python 包。它提供了一系列时间序列增强方法,并有一个简单的 API 可以将多个增强器连接成一个管道。也可用于音频增强。
- wav-augment  - 对音频数据进行数据增强。
- 对音频数据进行数据增强。
音频数据以 pytorch 张量的形式表示。 它尤其适用于语音数据。 其中,它实现了我们在自监督学习中发现最有用的一些增强方法 (在时域中进行语音表征的对比学习的数据增强,E. Kharitonov, M. Rivière, G. Synnaeve, L. Wolf, P.-E. Mazaré, M. Douze, E. Dupoux. [arxiv]):
- 音高随机化,
- 混响,
- 加性噪声,
- 时间丢弃(时间掩码),
- 带阻滤波,
- 截幅
- AugLy - AugLy 是一个数据增强库,目前支持四种模态(音频、图像、文本和视频)以及超过 100 种增强方法。
每种模态的增强都包含在其各自的子库中。这些子库包括基于函数和基于类的变换、组合操作符,并且可以选择提供关于所应用变换的元数据,包括其强度。
AugLy 是一个很棒的库,可用于在模型训练中增强你的数据,或评估你的模型的鲁棒性差距!我们设计 AugLy 的目的是为了包含许多用户在 Facebook 等互联网平台上实际执行的特定数据增强方法——例如将图片制作成表情包,在图片或视频上叠加文字/表情符号,从社交媒体上重新发布截图等。虽然 AugLy 也包含更通用的数据增强方法,但如果你正在处理复制检测、仇恨言论检测或版权侵权等问题,而这些问题中经常出现这些“互联网用户”类型的数据增强时,AugLy 将对你特别有用。
时间序列
- tsaug 
是一个用于时间序列增强的 Python 包。它提供了一系列时间序列增强方法,以及一个简单的 API 来将多个增强器连接成一个管道。
示例增强器:
- 并行进行 5 次随机时间扭曲,
- 随机裁剪长度为 300 的子序列,
- 随机量化到 10、20 或 30 个等级集,
- 以 80% 的概率随机使信号漂移 10% 至 50%,
- 以 50% 的概率反转序列。
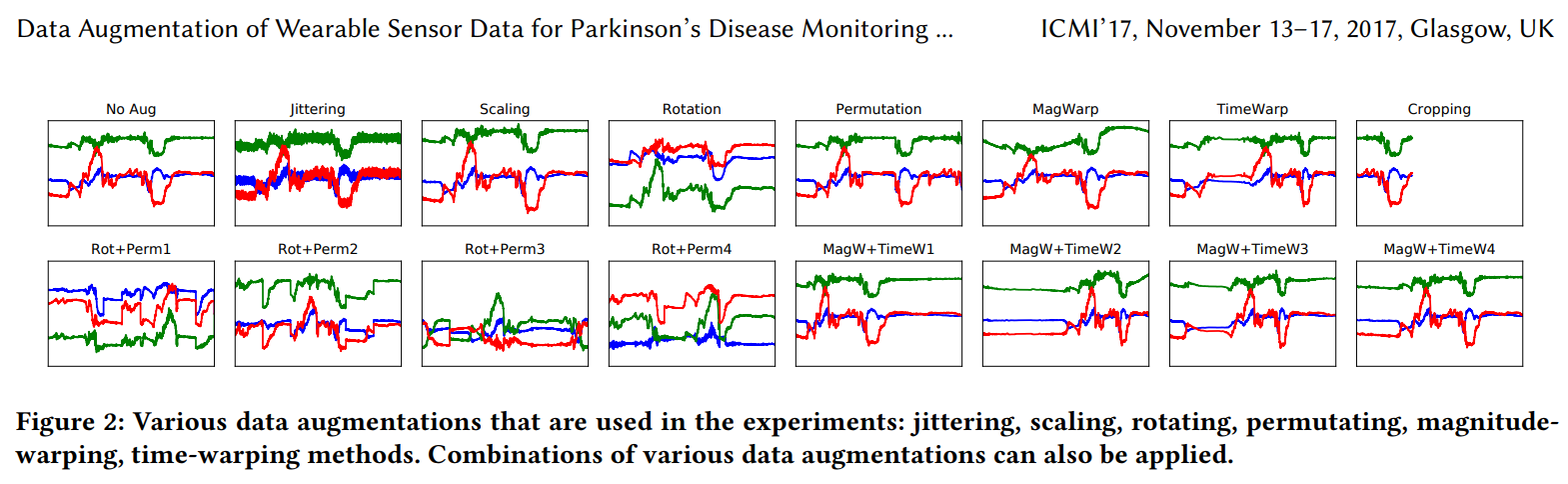
- 可穿戴传感器数据增强  - 一个基于以下论文的可穿戴传感器数据(时间序列数据)增强方法示例代码:
- 一个基于以下论文的可穿戴传感器数据(时间序列数据)增强方法示例代码:
T. T. Um 等人,“利用卷积神经网络对帕金森病监测中的可穿戴传感器数据进行增强”,载于第 19 届 ACM 国际多模态交互会议论文集,ICMI 2017 系列。纽约,美国:ACM,2017 年,第 216–220 页。
AutoAugment
自动数据增强是一系列算法,用于搜索针对特定任务的数据集增强策略。
GitHub 仓库:
- Text AutoAugment (TAA)
- PyTorch 中官方 Fast AutoAugment 实现

- AutoCLINT - 自动轻量级网络迁移(专门设计了一个轻量版的 Fast AutoAugment,以适应资源有限的各种任务)

- 基于种群的增强(PBA)

- AutoAugment:从数据中学习增强策略(Keras 和 Tensorflow)

- AutoAugment:从数据中学习增强策略(PyTorch)

- AutoAugment:从数据中学习增强策略(PyTorch,另一种实现)

其他
挑战
- AutoDL 2019(NeurIPS AutoDL 挑战赛——包含 AutoAugment) - 近年来,机器学习尤其是深度学习取得了显著成就,越来越多的学科开始依赖它。然而,这些成功在很大程度上仍需人工干预,涉及数据预处理、特征工程、模型选择、超参数优化等多个环节。由于这些任务的复杂性往往超出非专业人士的能力范围,机器学习应用的迅速普及催生了对开箱即用或可复用方法的需求,以便无需专业知识也能轻松使用。AutoML(自动化机器学习)挑战赛的目标是开发“通用学习机器”(无论是基于深度学习还是其他方法),能够在无人工干预的情况下自主学习并进行预测(盲测)。
研讨会
- ICCV 2021 视觉领域交互式标注与数据增强研讨会 - 视觉领域交互式标注与数据增强研讨会(ILDAV)旨在探索解决计算机视觉问题的新方法,尤其是在大量标注图像数据难以获取的情况下。关键在于能够快速且低成本地收集并标注足够规模的数据集。具体而言,我们关注以下解决方案:(i) 少点击和交互式数据标注,利用机器学习来提升人工标注效率;(ii) 合成数据生成,通过人工生成的数据扩充真实数据集;(iii) 弱监督学习,即使用辅助或弱信号代替(或补充)人工标注。
更广泛地说,我们的目标是在学术界和工业界之间促进合作,充分利用机器学习研究与人机协作的交互式标注技术,快速构建数据集,从而让强大的深度模型能够应用于各类计算机视觉任务中。
研讨会的主题包括但不限于:
- 交互式与少点击标注
- 数据增强
- 用于模型训练的合成数据
- 弱监督学习
- 人机协作学习
版本历史
v1.02021/09/01常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。