Ovis
Ovis 是一款创新的多模态大语言模型(MLLM),旨在通过独特的架构设计,实现视觉与文本嵌入的结构化对齐。它有效解决了传统模型在处理复杂图像、图表及视频时,难以精准理解视觉细节或与文本逻辑深度融合的痛点,显著提升了跨模态推理的准确性。
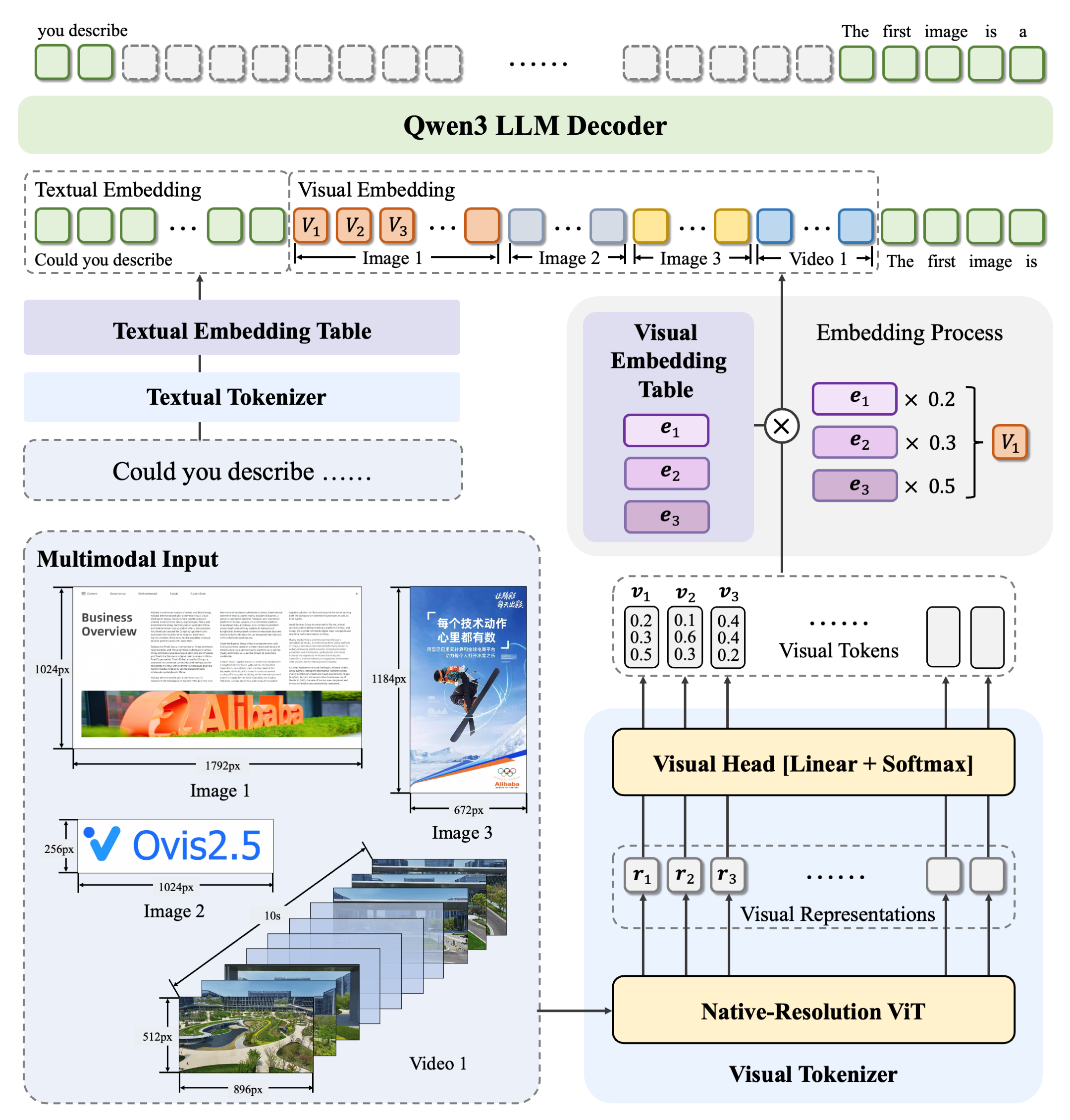
无论是从事多模态研究的研究人员、需要定制模型的开发者,还是希望体验先进 AI 能力的普通用户,都能从 Ovis 中获益。其最新发布的 Ovis2.5 版本支持原生分辨率视觉感知,无需压缩即可处理高清图像,并引入了增强型“反思推理”模式,使其在科学计算(STEM)、图表分析、视觉定位及视频理解等任务上表现卓越。此外,Ovis 提供了从 2B 到 34B 多种参数量级的模型选择,兼顾了高性能与部署灵活性,让不同算力需求的用户都能轻松上手,探索视觉与语言交互的无限可能。
使用场景
某电商数据分析师需要每日从数百张包含复杂图表、多语言标签及低分辨率截图的销售日报中提取关键趋势,并生成结构化洞察报告。
没有 Ovis 时
- 细节丢失严重:传统模型在处理高分辨率报表截图时,往往强制压缩图像,导致图表中的微小数据点或图例模糊不清,无法准确读取数值。
- 多模态对齐偏差:当图表中包含中英文混合标注时,模型常将文字描述与对应的图形区域错误匹配,产生“看图说话”但逻辑不通的幻觉。
- 推理能力薄弱:面对需要结合多个子图进行对比分析的任务(如“对比 Q3 与 Q4 的增长斜率”),旧模型只能罗列表面信息,缺乏深度推导能力。
- 人工复核成本高:由于输出结果不可靠,分析师必须逐条人工核对提取的数据,耗时耗力,严重拖慢决策节奏。
使用 Ovis 后
- 原生高清感知:Ovis 的原生分辨率视觉感知能力直接处理高清原图,精准识别图表中微小的刻度变化和密集数据点,零遗漏提取关键数值。
- 结构级模态对齐:凭借独特的结构嵌入对齐架构,Ovis 能精确将多语言文本标签与视觉区域锁定对应,彻底消除图文错配的幻觉问题。
- 增强反思推理:启用 Ovis 的“思考模式”后,它能主动拆解复杂图表逻辑,自动完成跨图表的趋势对比与归因分析,输出具备深度的商业洞察。
- 自动化流程闭环:高精度的输出让分析师无需二次复核,直接将 Ovis 生成的结构化结论接入 BI 系统,将日报处理时间从小时级缩短至分钟级。
Ovis 通过结构化的视听语义对齐,将繁琐的视觉数据清洗工作转化为可信赖的自动化智能决策流。
运行环境要求
- 未说明
- 需要 NVIDIA GPU(隐含,因依赖 Torch/CUDA),具体显存需求取决于模型版本(2B/9B 等)及输入分辨率
- 支持通过 min_pixels/max_pixels 调整显存占用
未说明
快速开始
Ovis
![]()
简介
Ovis(Open VISion)是一种新颖的多模态大语言模型(MLLM)架构,旨在从结构上对齐视觉和文本嵌入。
🔥 招聘中!
我们正在招募实习生和全职研究人员加入我们的团队,研究方向包括多模态理解、生成、推理、AI代理以及统一的多模态模型。如果您对这些激动人心的研究领域感兴趣,请通过 qingguo.cqg@alibaba-inc.com 联系我们。
发布
- [25/08/15] 🔥 推出 Ovis2.5-2B/9B,具备原生分辨率的视觉感知能力、增强的反思式推理能力(思考模式),并在STEM、图表分析、场景理解及视频理解等任务上表现领先。
- [25/03/25] 🔥 宣布推出Ovis2系列的量化版本,涵盖 Ovis2-2/4/8/16/34B!
- [25/01/26] 🔥 推出 Ovis2-1/2/4/8/16/34B,这是Ovis模型的最新版本,具有突破性的小模型性能、更强的推理能力、先进的视频和多图像处理能力、扩展的多语言OCR支持,以及改进的高分辨率图像处理能力。
- [24/11/26] 🔥 宣布推出 Ovis1.6-Gemma2-27B!
- [24/11/04] 🔥 宣布推出Ovis1.6的量化版本:Ovis1.6-Gemma2-9B-GPTQ-Int4 和 Ovis1.6-Llama3.2-3B-GPTQ-Int4!
- [24/10/22] 🔥 宣布推出Ovis1.6-Llama3.2-3B(模型,演示)!
- [24/09/19] 🔥 宣布推出Ovis1.6-Gemma2-9B(模型,演示)。此次发布进一步提升了高分辨率图像处理能力,采用了更大、更丰富、更高品质的数据集进行训练,并在指令微调之后引入了DPO训练来优化模型。
- [24/07/24] 🔥 推出Ovis1.5,其特点是改进了高分辨率图像处理能力,并优化了训练数据以提升性能。
- [24/06/14] 🔥 推出Ovis1.0,即Ovis模型的首个版本。
目录
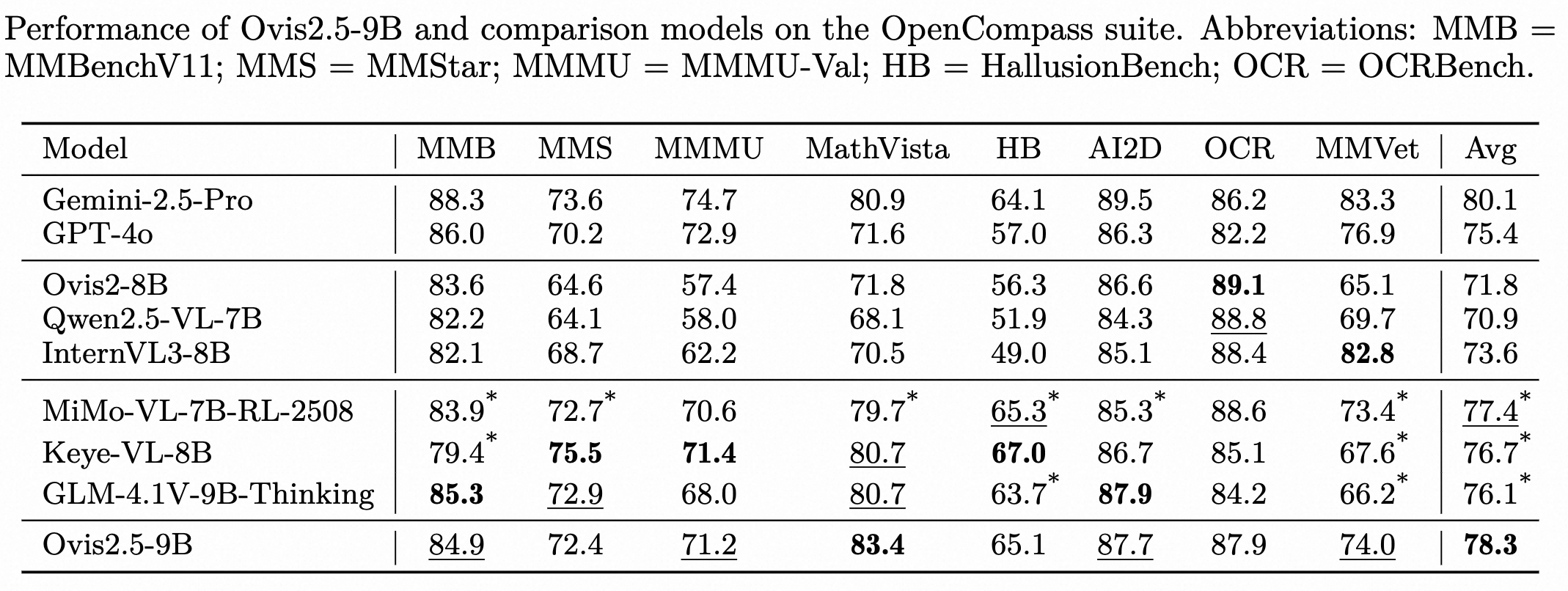
模型
Ovis可以与流行的LLM结合使用。我们提供了以下Ovis MLLM:
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|---|---|---|---|---|
| Ovis2.5-2B | siglip2-so400m-patch16-512 | Qwen3-1.7B | Huggingface | Space |
| Ovis2.5-9B | siglip2-so400m-patch16-512 | Qwen3-8B | Huggingface | Space |
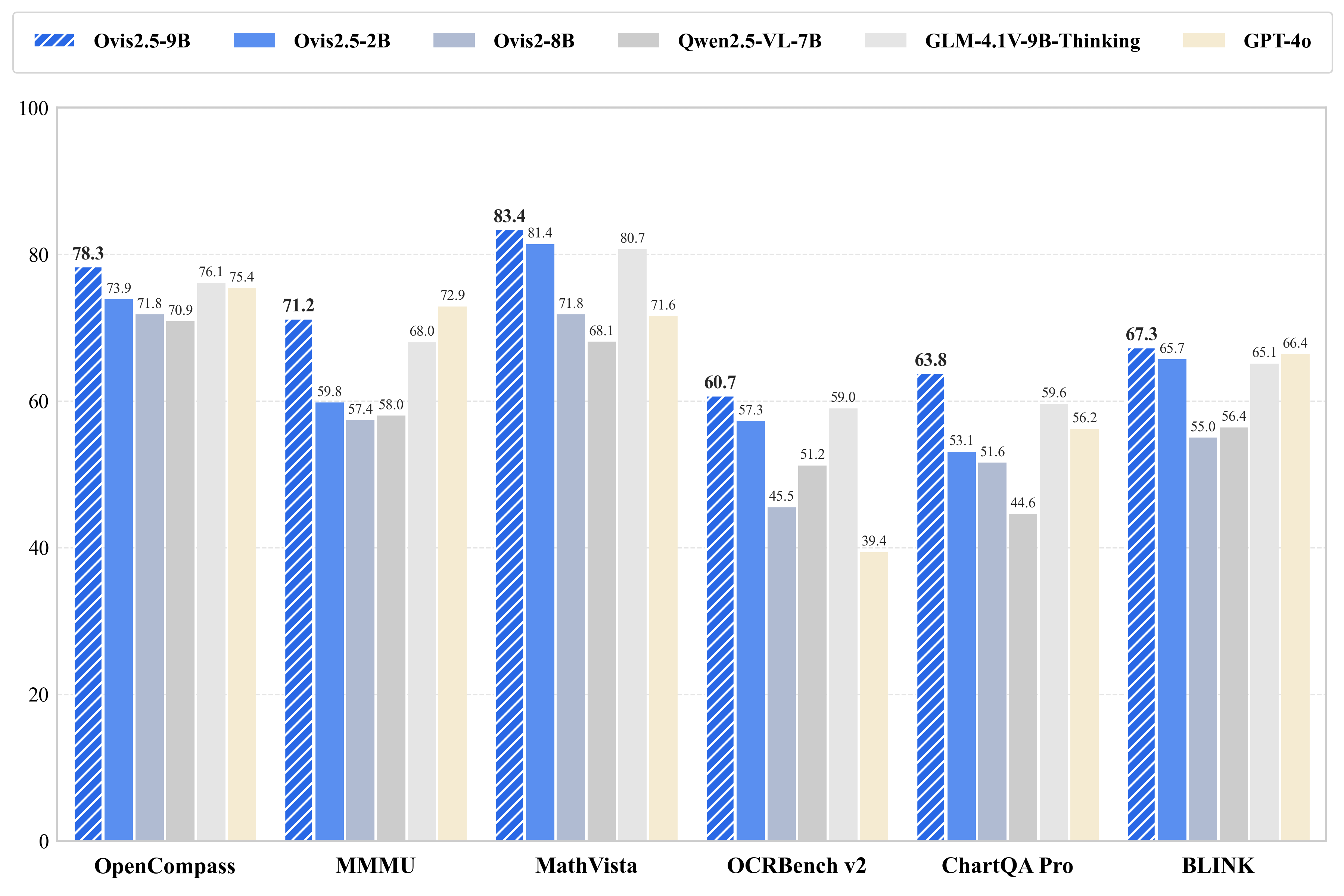
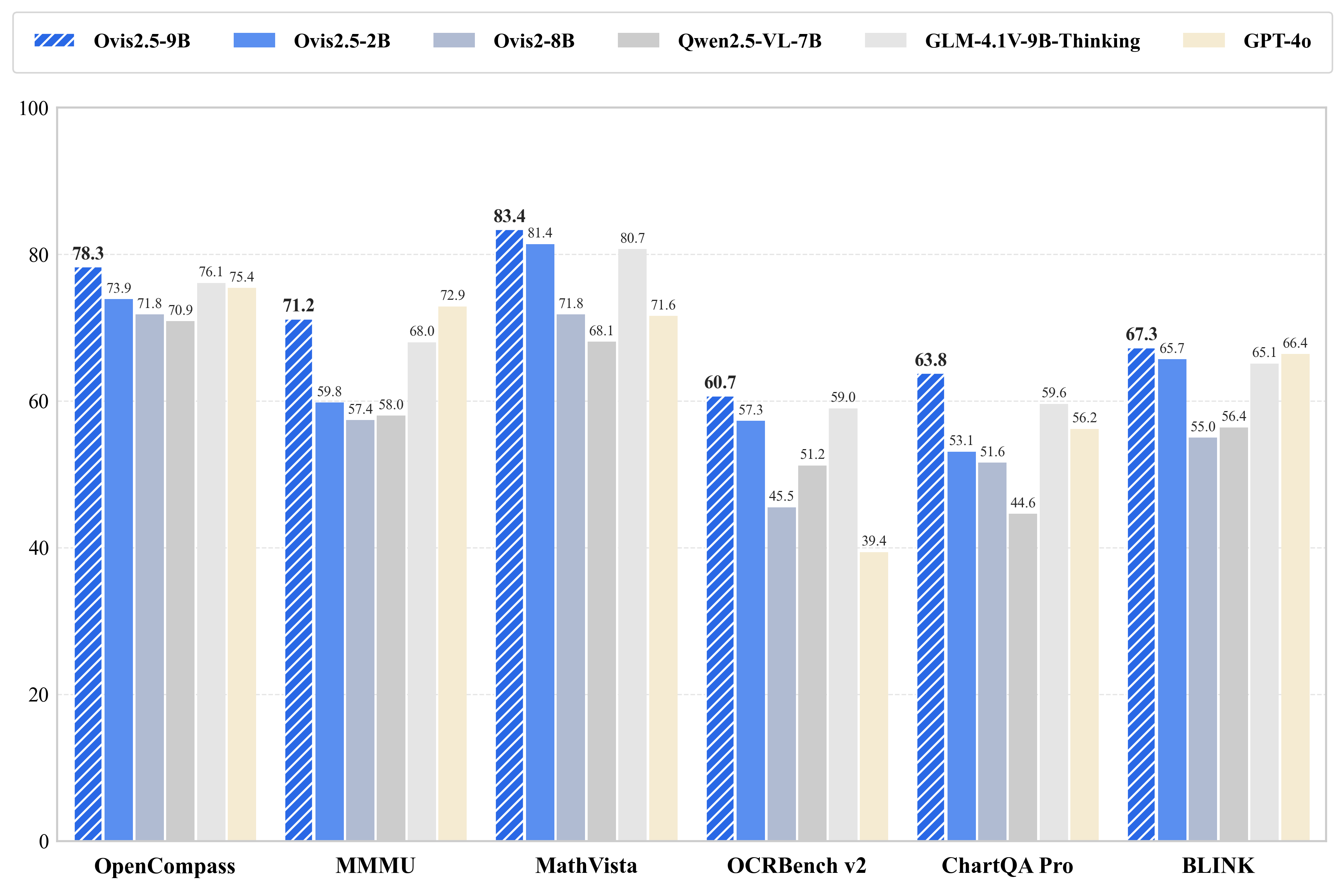
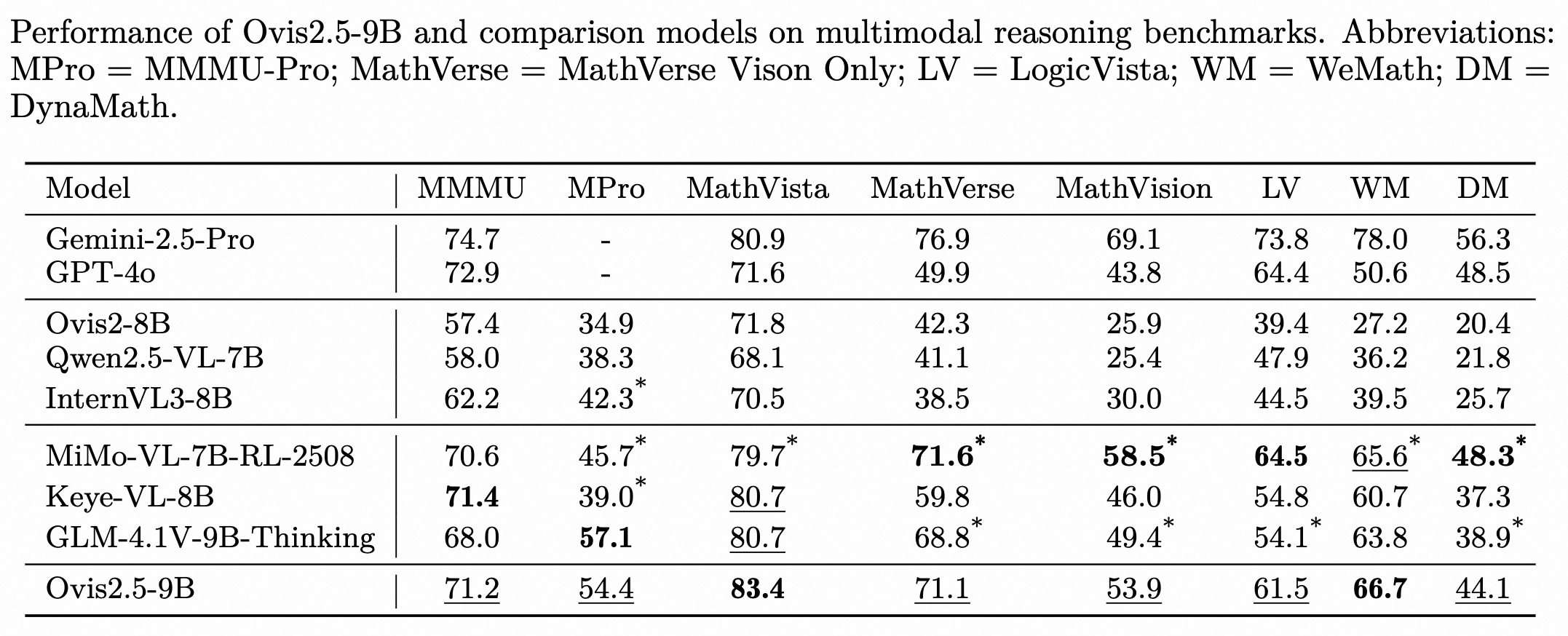
性能
Ovis2.5在通用多模态基准测试、复杂图表分析和推理任务上表现出色,在参数量低于40B的开源模型中位居前列。
安装
Ovis已在Python 3.10、Torch 2.4.0、Transformers 4.51.3和DeepSpeed 0.15.4环境下进行了测试。有关完整的依赖包列表,请参阅 requirements.txt 文件。
git clone git@github.com:AIDC-AI/Ovis.git
conda create -n ovis python=3.10 -y
conda activate ovis
cd Ovis
pip install -r requirements.txt
pip install -e .
对于 vLLM:
pip install vllm==0.10.2 --extra-index-url https://wheels.vllm.ai/0.10.2/
推理
我们提供了使用 transformers 和 vLLM 的推理示例。
transformers
在 ovis/serve 中,我们提供了三个示例文件:
ovis/serve/infer_think_demo.py
展示如何通过enable_thinking启用模型的 反思式推理,并使用thinking_budget控制推理阶段的时长。ovis/serve/infer_basic_demo.py
提供单张图像、多张图像、视频和纯文本输入的推理示例。ovis/serve/web_ui.py提供一个基于 Gradio 的Web UI演示。示例运行:python ovis/serve/web_ui.py --model-path AIDC-AI/Ovis2.5-9B --port 8001
vLLM
启动 vLLM 服务器:
vllm serve AIDC-AI/Ovis2.5-9B \
--trust-remote-code \
--port 8000
使用 OpenAI Python SDK 调用模型:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="AIDC-AI/Ovis2.5-9B",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/kh-1dhZRAduP-P4SkIhXr.png"
},
},
{"type": "text", "text": "识别表格内容"},
],
},
],
extra_body={
"chat_template_kwargs": {
"enable_thinking": True,
},
"mm_processor_kwargs": {
"images_kwargs": {
"min_pixels": 1048576, # 1024 * 1024
"max_pixels": 3211264 # 1792 * 1792
}
}
}
)
print("聊天回复:\n", chat_response.choices[0].message.content)
extra_body 参数说明:
chat_template_kwargs.enable_thinking启用思考模式(反思性推理)。mm_processor_kwargs.images_kwargs.min_pixels / max_pixels控制输入图像的分辨率范围(以总像素数计),在准确性和 GPU 内存占用之间取得平衡。
模型微调
Ovis 可以使用本仓库提供的训练代码,或通过 ms-swift 进行微调。
1. 使用仓库内代码进行微调
数据格式
训练数据集以 JSON 列表 形式存储,其中每个元素对应一个样本。 示例数据集 JSON:
[
{
"id": 1354,
"image": "1354.png",
"conversations": [
{
"from": "human",
"value": "<image>\n图中,四边形 ABCD 的顶点与正方形 EFGH 相交,并将其各边分割为长度比为 1:2 的线段。求 ABCD 与 EFGH 面积之比。"
},
{
"from": "gpt",
"value": "5:9"
}
]
}
]
数据集信息
数据集通过 datainfo JSON 文件 引用,例如 ovis/train/dataset/ovis2_5_sft_datainfo.json:
{
"geometry3k_local": {
"meta_file": "path/to/geometry3k_local.json",
"storage_type": "hybrid",
"data_format": "conversation",
"image_dir": "path/to/images/"
}
}
meta_file:转换后的数据集 JSON 文件路径(样本列表)。storage_type:通常设置为"hybrid"。data_format:通常设置为"conversation"。image_dir:包含引用图像的目录路径。
训练脚本
我们在 scripts/ 目录下提供了示例训练脚本。例如,使用 SFT 微调 Ovis2.5:
bash scripts/run_ovis2_5_sft.sh
该脚本配置了 DeepSpeed 引擎、数据集路径以及模型检查点的初始化。请根据您自己的数据集和环境对其进行修改。
2. 使用 ms-swift 进行微调
此外,Ovis 模型也可以使用 ms-swift,一个灵活的 LLM 训练框架,来进行微调。
引用
如果您觉得 Ovis 有用,请引用以下论文:
@article{lu2025ovis25technicalreport,
title={Ovis2.5 技术报告},
author={Shiyin Lu 和 Yang Li 和 Yu Xia 和 Yuwei Hu 和 Shanshan Zhao 和 Yanqing Ma 和 Zhichao Wei 和 Yinglun Li 和 Lunhao Duan 和 Jianshan Zhao 和 Yuxuan Han 和 Haijun Li 和 Wanying Chen 和 Junke Tang 和 Chengkun Hou 和 Zhixing Du 和 Tianli Zhou 和 Wenjie Zhang 和 Huping Ding 和 Jiahe Li 和 Wen Li 和 Gui Hu 和 Yiliang Gu 和 Siran Yang 和 Jiamang Wang 和 Hailong Sun 和 Yibo Wang 和 Hui Sun 和 Jinlong Huang 和 Yuping He 和 Shengze Shi 和 Weihong Zhang 和 Guodong Zheng 和 Junpeng Jiang 和 Sensen Gao 和 Yi-Feng Wu 和 Sijia Chen 和 Yuhui Chen 和 Qing-Guo Chen 和 Zhao Xu 和 Weihua Luo 和 Kaifu Zhang},
year={2025},
journal={arXiv:2508.11737}
}
@article{lu2024ovis,
title={Ovis:用于多模态大语言模型的结构嵌入对齐},
author={Shiyin Lu 和 Yang Li 和 Qing-Guo Chen 和 Zhao Xu 和 Weihua Luo 和 Kaifu Zhang 和 Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
团队
本工作由阿里巴巴 Ovis 团队共同完成。我们还希望提供团队其他 MLLM 论文的链接:
许可证
本项目采用 Apache License, Version 2.0 许可证(SPDX-License-Identifier: Apache-2.0)。
免责声明
我们在训练过程中使用了合规性检查算法,以尽可能确保训练后模型的合规性。然而,由于数据的复杂性以及语言模型使用场景的多样性,我们无法保证模型完全不存在版权问题或不当内容。如果您认为任何内容侵犯了您的权益或产生了不当内容,请及时联系我们,我们将迅速处理此事。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。