MARS
MARS 是一个专为训练大型模型设计的统一优化框架,旨在释放“方差缩减”技术的潜力,解决传统自适应梯度方法(如 AdamW)在训练中随机梯度方差过高的问题。在大模型训练过程中,高方差往往导致收敛缓慢或不稳定,而现有的方差缩减技术又难以在实际深度学习场景中落地。MARS 巧妙地将“缩放随机递归动量”与“预条件更新”相结合:前者提供低方差的梯度估计以提升整体效率,后者近似二阶牛顿法以优化单步迭代效果,从而加速寻找最优解的过程。
该工具特别适合从事大模型预训练、微调的研究人员以及需要高效优化算法的深度学习开发者。目前,MARS 已衍生出 MARS-AdamW、MARS-Lion 和 MARS-Shampoo 三种具体实现,其中 MARS-AdamW 还提供了高效的 CUDA 版本。其核心技术亮点在于引入了可调节的缩放梯度校正项,并支持多种海森矩阵近似策略,使其在视觉任务和语言模型(如 GPT-2 XL、FineWeb-Edu)上均展现出卓越的性能。对于希望突破现有优化器瓶颈、探索更高效训练方案的专业用户而言,MARS 提供了一个强大且灵活的开源选择。
使用场景
某大型 AI 实验室团队正在基于 FineWeb-Edu 数据集从头预训练一个类似 GPT-2 XL 的亿级参数语言模型,面临训练成本高昂与收敛缓慢的双重挑战。
没有 MARS 时
- 梯度噪声大导致收敛震荡:传统 AdamW 优化器在处理大规模数据时,随机梯度方差过高,导致损失函数曲线剧烈波动,难以稳定下降。
- 训练周期漫长:为了达到理想的验证集准确率(如 Hellaswag 基准),需要消耗海量的 Token 和极长的 GPU 机时,研发迭代效率低下。
- 超参数调优困难:由于优化路径不平滑,学习率等关键超参数极其敏感,稍有不慎就会导致模型发散或陷入局部最优。
- 算力资源浪费:大量的计算资源被消耗在无效的震荡更新上,而非实质性的模型性能提升,增加了项目的资金压力。
使用 MARS 后
- 方差抑制显著平滑轨迹:MARS 通过“缩放随机递归动量”机制有效降低了梯度估计方差,使训练曲线平稳快速下降,大幅减少了震荡。
- 加速收敛节省算力:在相同 Token 数量下,模型能更快达到高精度(例如在 500 亿 Token 内即可让 Hellaswag 准确率突破 56.5%),显著缩短训练周期。
- 二阶近似提升鲁棒性:利用预处理更新模拟牛顿法,MARS 对超参数的变化更具包容性,降低了调参门槛,让模型更容易找到全局最优解。
- 单位算力产出最大化:结合方差缩减与预处理优势,每一轮迭代都更高效地逼近临界点,同等预算下可训练更大规模或更高质量的模型。
MARS 通过将方差缩减技术与自适应梯度方法深度融合,从根本上解决了大模型训练中的噪声与效率瓶颈,让昂贵的算力真正转化为模型智能。
运行环境要求
- 未说明
需要 NVIDIA GPU(提及了 MARS-AdamW CUDA 实现),具体型号和显存大小未说明,需支持 CUDA
未说明
快速开始
MARS:释放方差缩减的力量,用于训练大型模型
本仓库包含论文《MARS:释放方差缩减的力量,用于训练大型模型》的官方代码,论文链接为:https://arxiv.org/abs/2411.10438。
🔔 最新消息
- [2025年04月03日] MARS-AdamW CUDA 实现已上线。
- [2025年01月05日] 我们的论文已被 ICML 2025 接收 🎉🎉。
- [2025年10月02日] 我们在 ArXiv 上更新了论文:https://arxiv.org/pdf/2411.10438v2。
- [2025年12月01日] 更新了复现 GPT-2 XL 和 FineWeb-Edu 结果的脚本。
- [2025年12月01日] 我们在 FineWeb-Edu 上的预训练结果已公开。GPT-2 XL 在 500 亿 token 的训练下,Hellaswag 准确率达到 56.52%。
- [2024年11月26日] 新增视觉任务支持。
- [2024年11月18日] 我们的代码正式开源!
- [2024年11月15日] 我们的论文已在 ArXiv 上发布:https://arxiv.org/abs/2411.10438。
关于 MARS
MARS(Make vAriance Reduction Shine)是一个统一的优化框架,旨在解决训练大型模型时固有的挑战。传统的自适应梯度方法,如 Adam 和 AdamW,通常面临较高的随机梯度方差问题;而方差缩减技术在深度学习中却难以发挥实际作用。MARS 的核心由两个主要部分组成:(1) 缩放的随机递归动量,它提供了一种方差缩减的全梯度估计器,从而改善梯度复杂度;(2) 预条件更新,它近似二阶牛顿法,以降低每轮迭代的计算复杂度。通过将预条件梯度方法与方差缩减相结合,MARS 实现了两者的最佳结合,加速了优化过程中关键点的搜索。
MARS 框架基于以下预条件方差缩减更新公式:
$$ \mathbf{c}_t = \nabla f(\mathbf{x}_t, \mathbf{\xi}_t)+\underbrace{{\color{red}\gamma_t} \frac{\beta_{1}}{1-\beta_{1}} \left(\nabla f(\mathbf{x}_t, \mathbf{\xi}_t)-\nabla f(\mathbf{x}_{t-1}, \mathbf{\xi}_t)\right)}_{\text{缩放梯度修正}} $$
$$ \tilde{\mathbf{c}}_t = \text{Clip}(\mathbf{c}_t,1) = \begin{cases} \frac{\mathbf{c}_t}{\|\mathbf{c}_t\|_2} & \text{若 } \|\mathbf{c}_t\|_2 > 1,\ \mathbf{c}_t & \text{否则}. \end{cases} $$
$$ \mathbf{m}_t = \beta_1 \mathbf{m}_{t-1} + (1-\beta_{1})\tilde{\mathbf{c}}_t $$
$$ \mathbf{x}_{t+1} = \arg\min_{\mathbf{x} \in \mathbb{R}^d} \left\{\eta_t \left\langle \mathbf{m}_t, \mathbf{x} \right\rangle + \frac{1}{2} \|\mathbf{x} - \mathbf{x}_t \|_{\mathbf{H}_t}^2\right\} $$
其中 ${\color{red}\gamma_t}$ 是控制梯度修正强度的缩放参数。
MARS 的具体实现
在 MARS 框架下,我们提供了三种基于不同 Hessian 矩阵近似的实现:MARS-AdamW、MARS-Lion 和 MARS-Shampoo。请注意,该框架中的超参数是基于 MARS-AdamW 调优的。在使用其他实现时,务必对超参数(尤其是学习率)进行调优,以获得最佳性能。
MARS-AdamW
(在 mars.py 中通过设置 mars_type="mars-adamw" 启用)
Hessian 矩阵的近似定义如下:
$$ \mathbf{v}_t =\beta_2 \mathbf{v}_{t-1}+(1-\beta_2) \big(\nabla f(\mathbf{x}_t, \mathbf{\xi}_t)\big)^2 $$
$$ \mathbf{H}_t := \sqrt{\text{diag}\Big(\mathbf{v}_t\Big)}\cdot \frac{1 - \beta_1^t}{\sqrt{1 - \beta_2^t}}. $$
MARS-Lion
(在 mars.py 中通过设置 mars_type="mars-lion" 启用)
Hessian 矩阵的近似定义如下:
$$ \mathbf{H}_t := \sqrt{\text{diag}(\mathbf{m}_t^2)}. $$
MARS-Shampoo
(在 mars.py 中通过设置 mars_type="mars-shampoo" 启用)
预条件算子可以被视为一个 正交映射 操作符:
$$ \mathbf{U}_t, \mathbf{\Sigma}_t, \mathbf{V}_t = \text{SVD}(\mathbf{G}_t),\qquad \mathbf{x}_{t+1} =\mathbf{x}_t-\eta_t\mathbf{U}_t\mathbf{V}_t^\top. $$
在实践中,我们使用 Newton-Schulz 迭代法 来加速并近似求解 SVD 问题。
MARS 相比基线的表现
OpenWebText 数据集上的实验
MARS 的实验结果基于 MARS-AdamW 实现,除非另有说明。在我们的实验中,梯度是在每个样本和每次更新时计算一次的(即 MARS-approx 形式,详见我们的论文 https://arxiv.org/abs/2411.10438)。如果采用精确形式的 MARS,即每次更新进行两次梯度计算,则性能会略有提升,但计算开销也会翻倍。更多细节请参阅我们的论文。
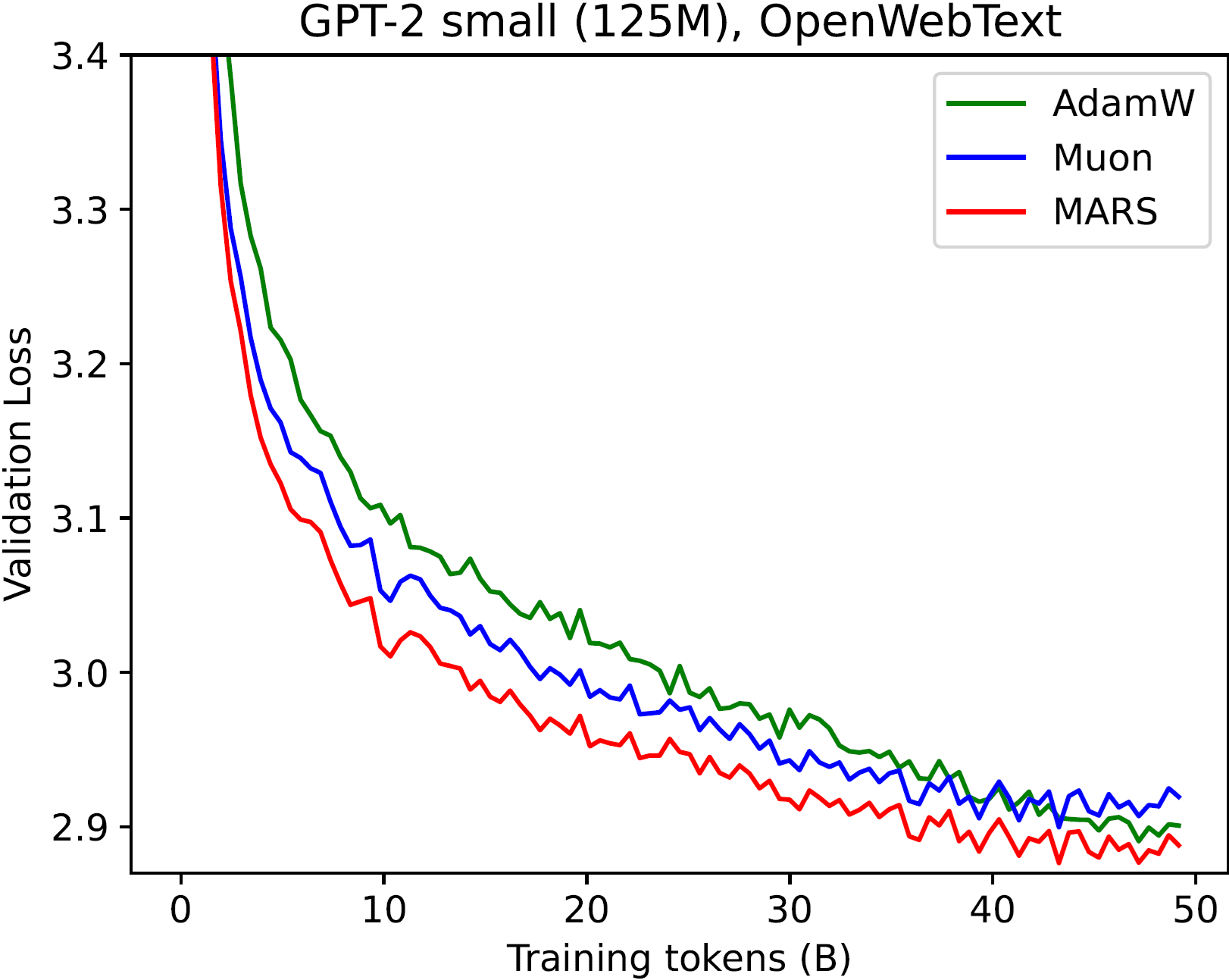
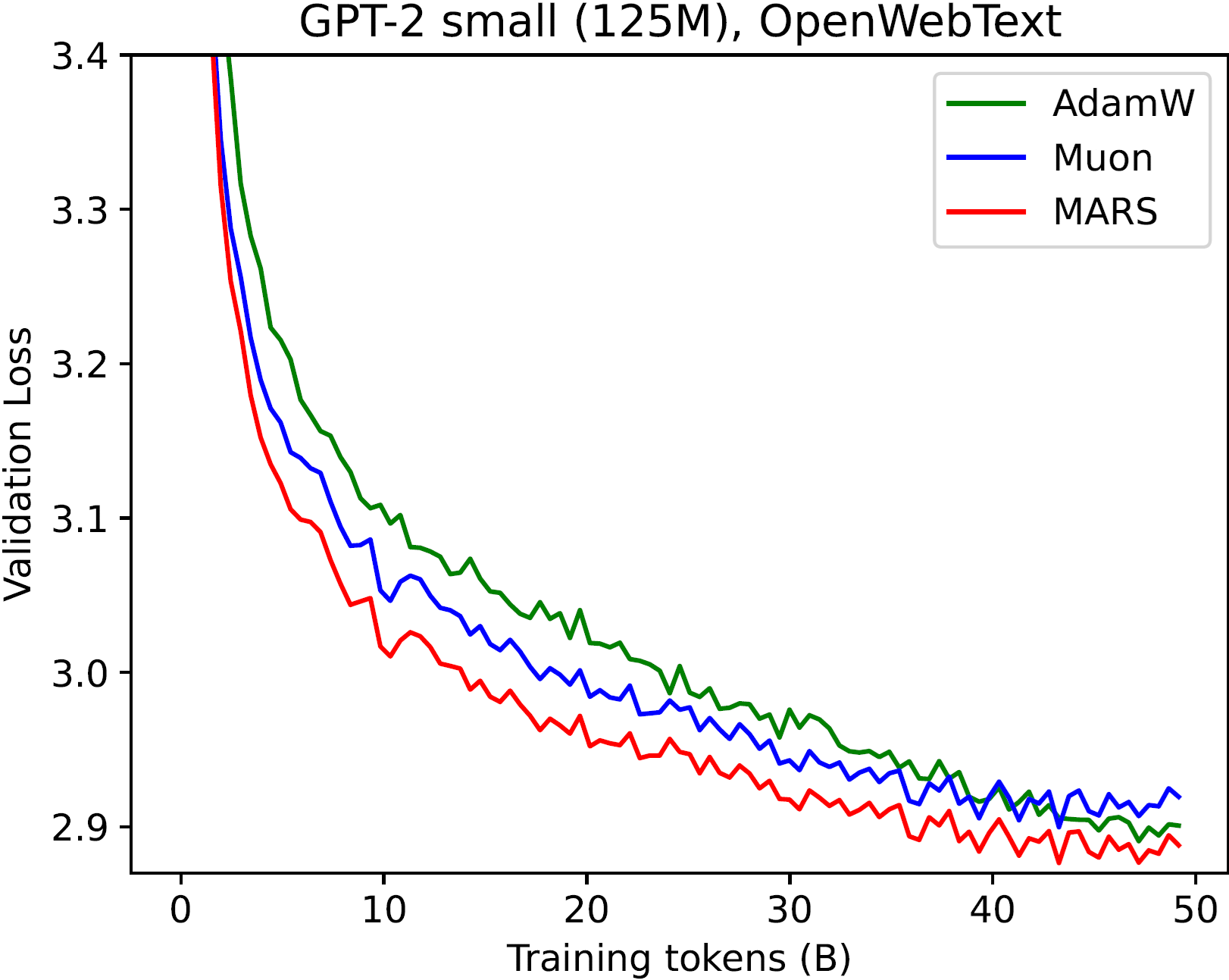
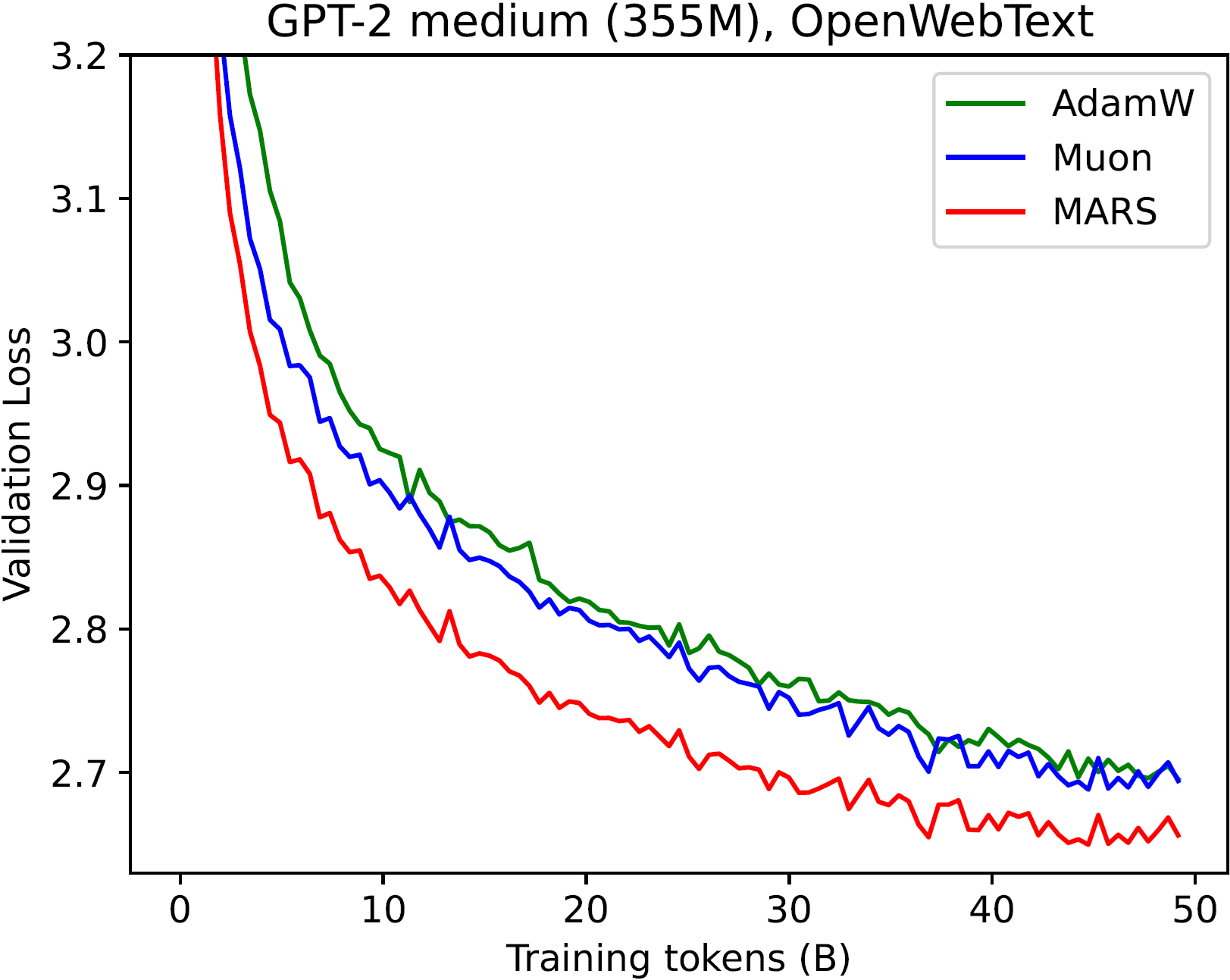
MARS 在 GPT-2 各个模型上均持续优于 AdamW 和 Muon 优化器:
| GPT-2 small | GPT-2 medium | GPT-2 large |
|---|---|---|
 |
 |
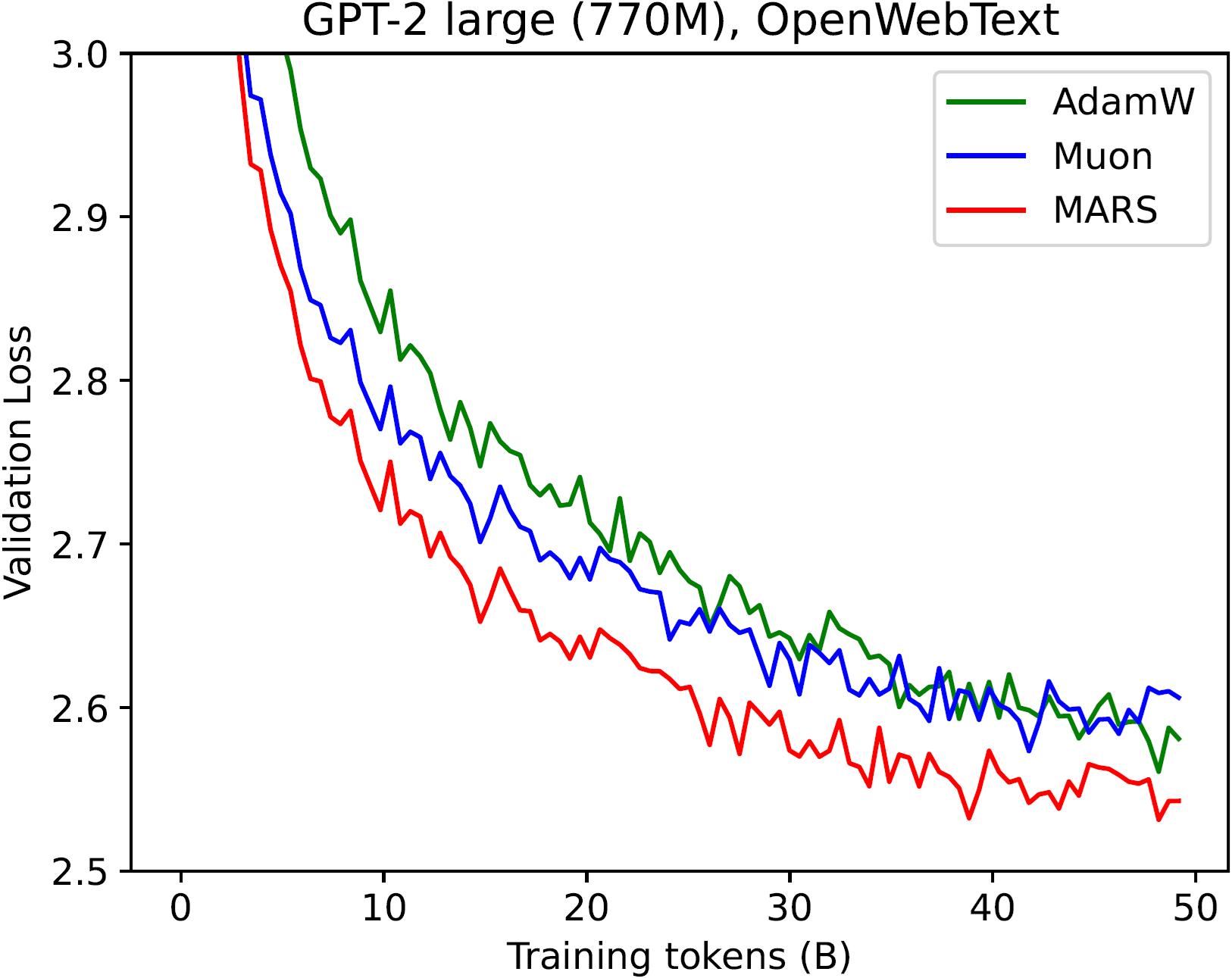 |
| 最佳验证损失 | GPT-2 Small (5B tokens) | GPT-2 Medium (5B tokens) | GPT-2 Large (5B tokens) | GPT-2 Small (20B tokens) | GPT-2 Medium (20B tokens) | GPT-2 Large (20B tokens) | GPT-2 Small (50B tokens) | GPT-2 Medium (50B tokens) | GPT-2 Large (50B tokens) |
|---|---|---|---|---|---|---|---|---|---|
| AdamW | 3.193 | 3.084 | 3.013 | 3.024 | 2.821 | 2.741 | 2.885 | 2.691 | 2.561 |
| Muon | 3.165 | 3.009 | 2.915 | 3.006 | 2.813 | 2.691 | 2.901 | 2.688 | 2.573 |
| MARS-exact | 3.107 | - | - | 2.980 | - | - | 2.847 | - | - |
| MARS-approx | 3.108 | 2.969 | 2.876 | 2.981 | 2.763 | 2.647 | 2.849 | 2.636 | 2.518 |
MARS 的效率
MARS 算法不仅可以在相同的训练步数内取得更好的性能,还可以在相同的训练时间内实现更优的效果:
| GPT-2 small | GPT-2 medium | GPT-2 large |
|---|---|---|
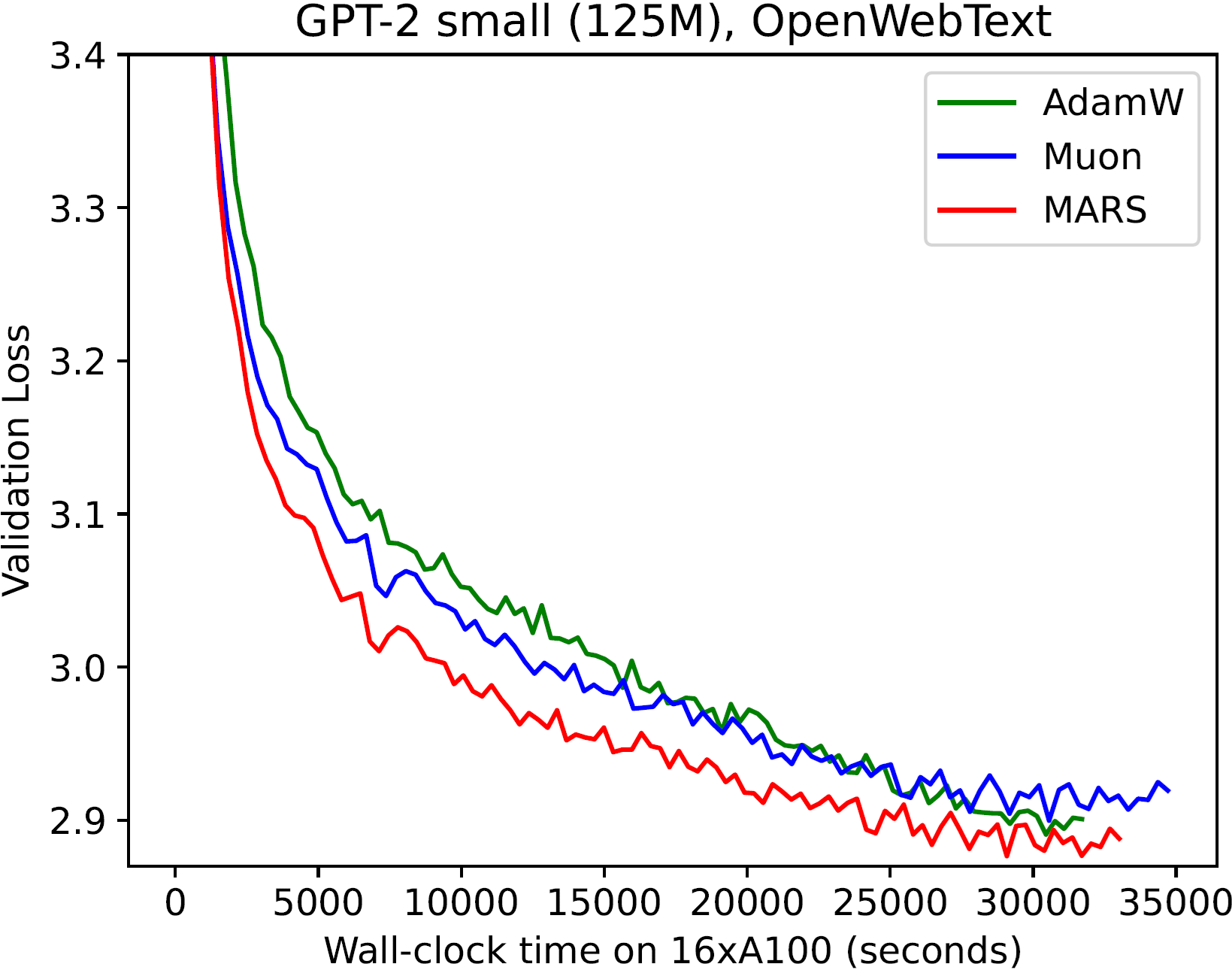 |
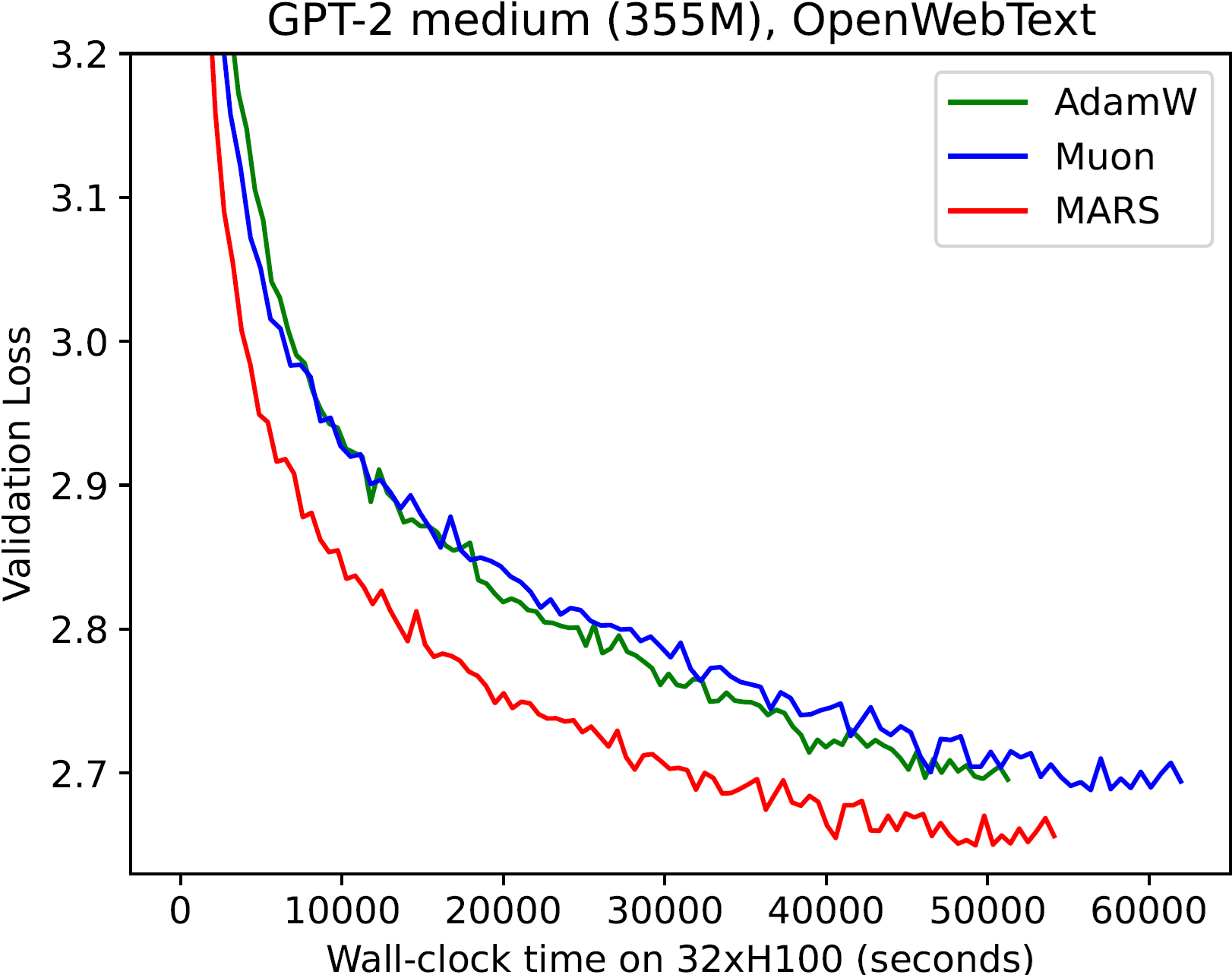 |
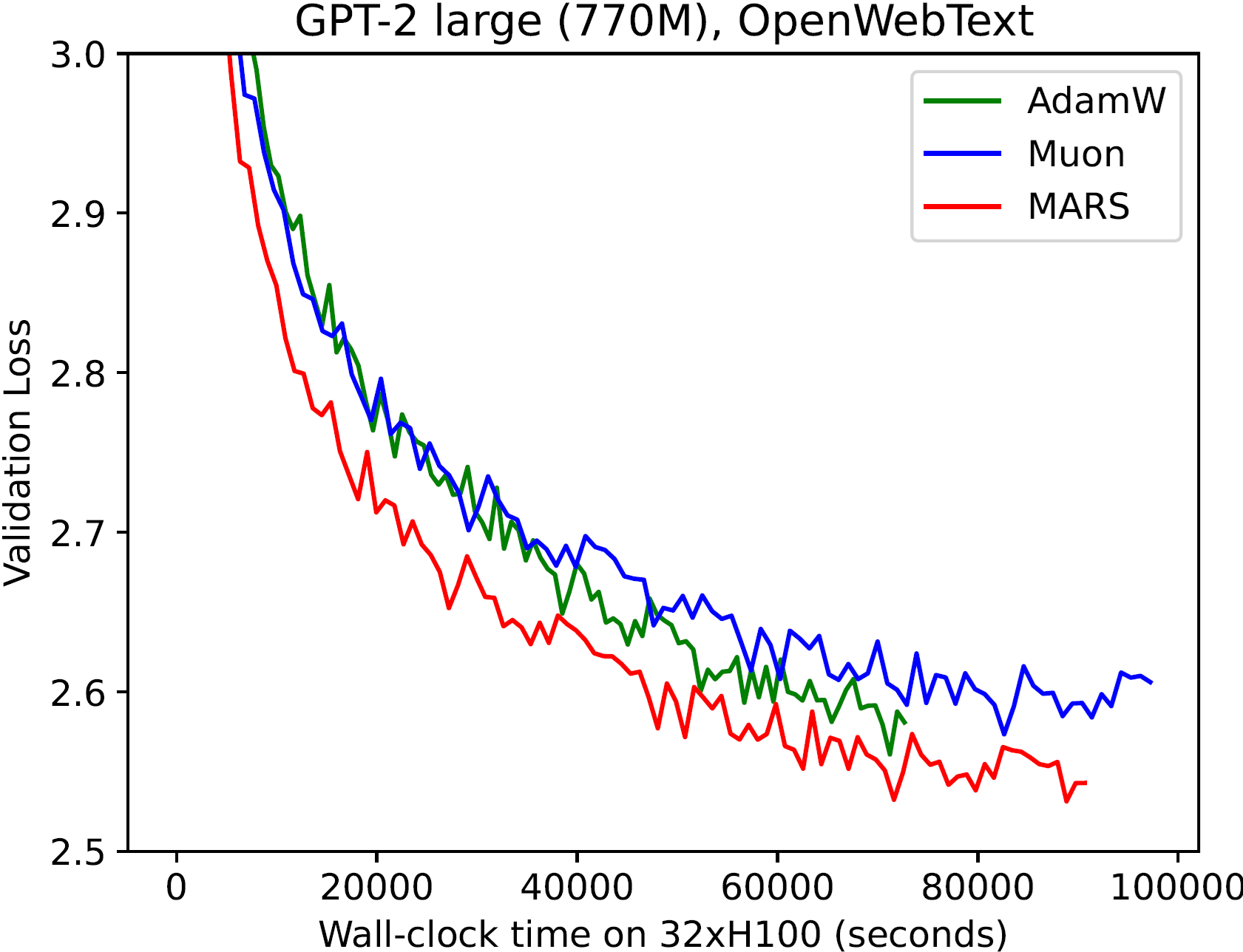 |
FineWeb-Edu 数据集上的实验
以下是使用我们的 MARS 方法与 AdamW 相比时,GPT‑2 Small 和 GPT‑2 XL 的训练和验证损失曲线。可以看出,MARS 往往能带来更快的收敛速度,并且在不同训练步数下始终表现出更低的损失。
| 模型 | GPT-2 small | GPT-2 XL |
|---|---|---|
| 训练损失 | 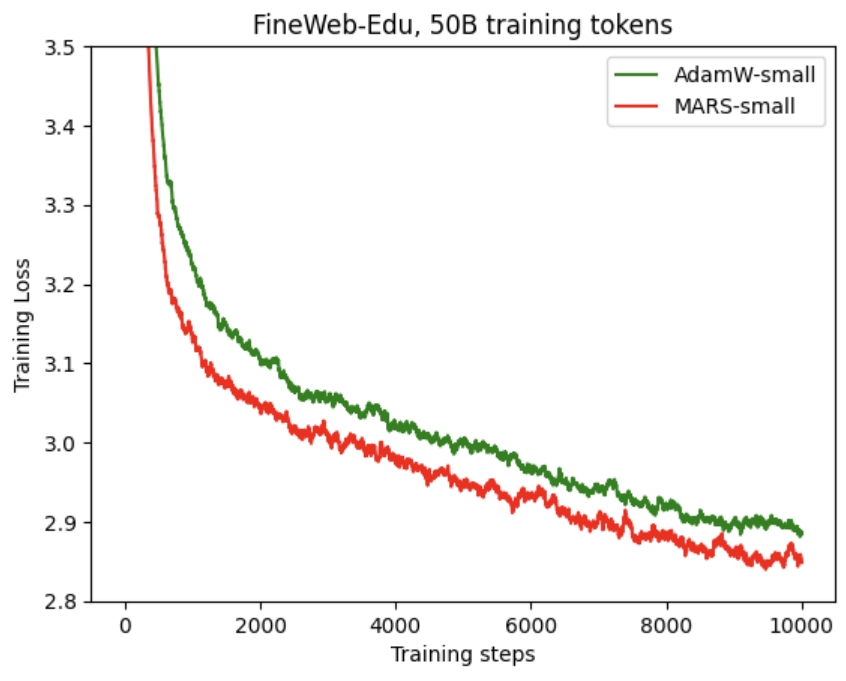 |
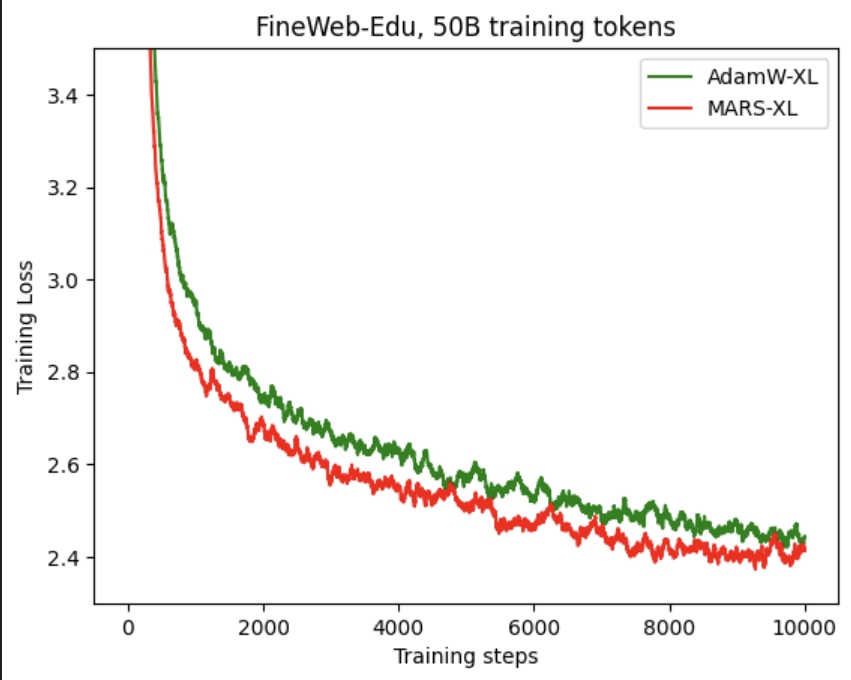 |
| 验证损失 | 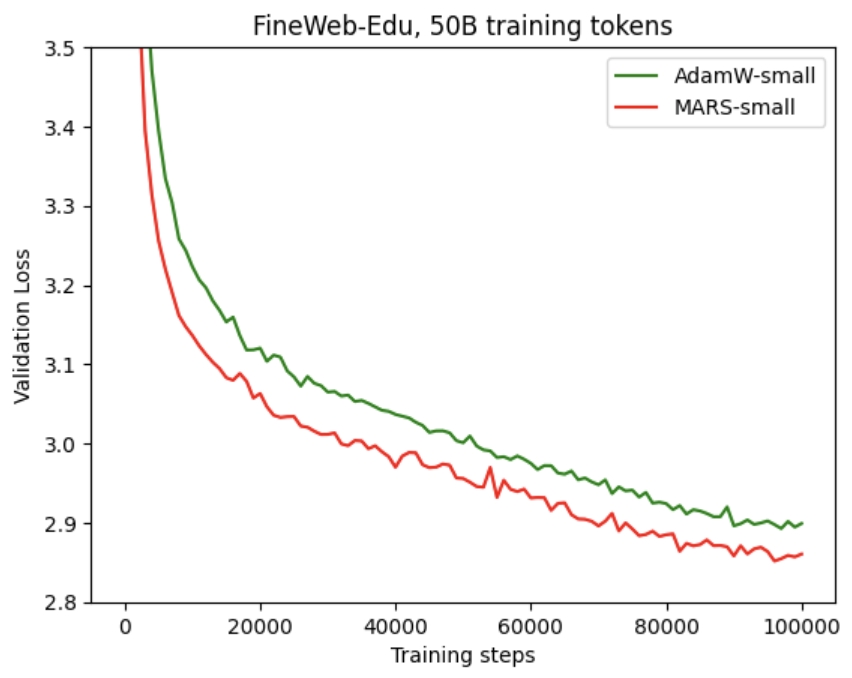 |
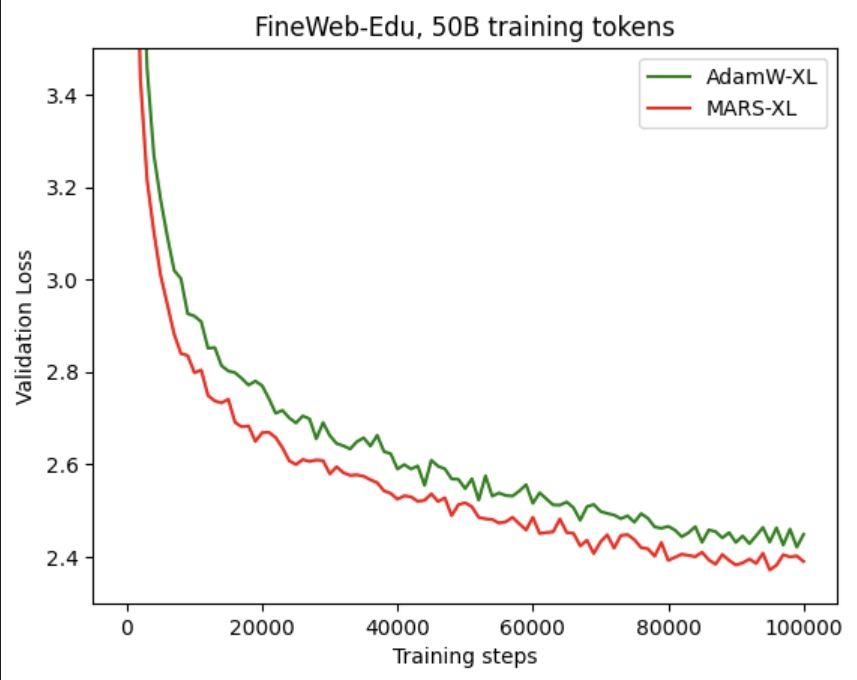 |
评估指标
下面我们展示了 GPT‑2 Small 和 GPT‑2 XL 在 FineWeb-Edu 数据集上的评估指标,对比了 OpenAI GPT2 基线、AdamW 以及我们的 MARS-AdamW 优化器。
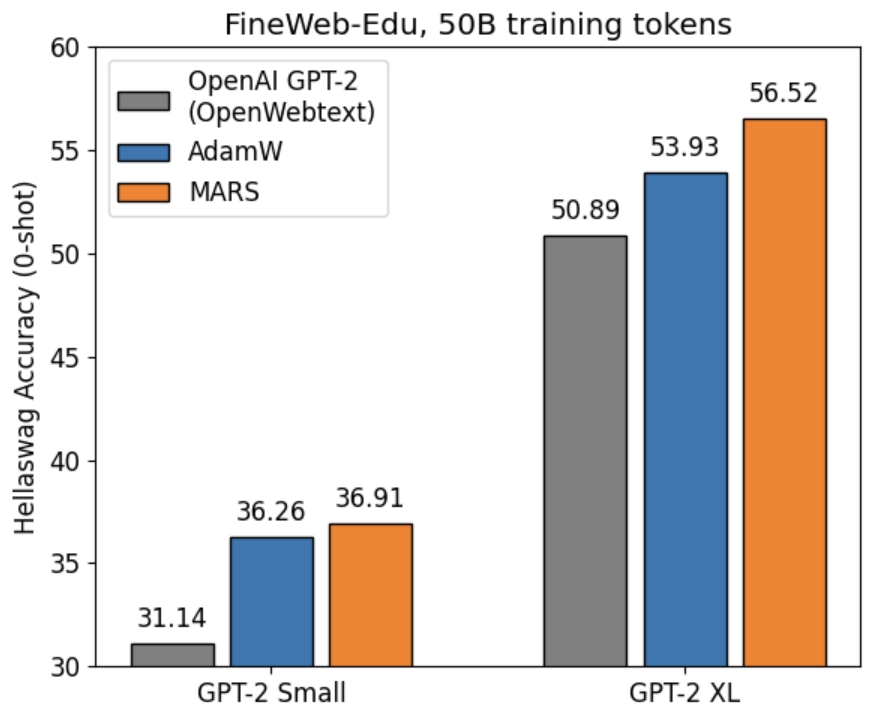
GPT-2 small 的结果
MARS-AdamW 在多个任务上均明显优于 AdamW 和 OpenAI 基线,在 GPT‑2 Small 上以 45.93 的最高平均分领先。
| 方法/任务 | ARC-E | ARC-C | BoolQ | HellaSwag | OBQA | PIQA | WG | MMLU | SciQ | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenAI-Comm. | 39.48 | 22.70 | 48.72 | 31.14 | 27.20 | 62.51 | 51.62 | 22.92 | 64.40 | 41.19 |
| AdamW | 51.43 | 26.54 | 55.78 | 36.26 | 30.60 | 64.53 | 50.36 | 24.49 | 71.50 | 45.72 |
| MARS-AdamW | 52.23 | 27.39 | 55.84 | 36.91 | 32.20 | 64.80 | 49.96 | 22.95 | 71.10 | 45.93 |
GPT-2 XL 的结果
在 GPT‑2 XL 上,MARS-AdamW 继续在大多数任务上超越 AdamW,尤其在 HellaSwag 任务中达到了 56.52% 的准确率。
| 方法/任务 | ARC-E | ARC-C | BoolQ | HellaSwag | OBQA | PIQA | WG | MMLU | SciQ | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenAI-Comm. | 51.05 | 28.50 | 61.77 | 50.89 | 32.00 | 70.51 | 58.33 | 25.24 | 76.00 | 50.48 |
| AdamW | 68.22 | 38.40 | 61.13 | 53.93 | 39.00 | 72.69 | 54.78 | 25.47 | 85.30 | 55.43 |
| MARS-AdamW | 66.54 | 39.85 | 63.82 | 56.52 | 41.20 | 73.34 | 56.59 | 23.86 | 86.00 | 56.41 |
视觉任务上的实验
在 CIFAR-10 和 CIFAR-100 数据集上,使用 ResNet-18 和 MultiStepLR(optimzer, milestones=[100, 150], gamma=0.1) 调度器时,MARS 能够获得比 AdamW 和 Muon 更好的测试损失和准确率。(我们通过网格搜索基础学习率 [1e-5, ..., 1e-1] 来展示每个优化器的最佳结果):
| 数据集 | CIFAR-10 | CIFAR-100 |
|---|---|---|
| 测试损失 | 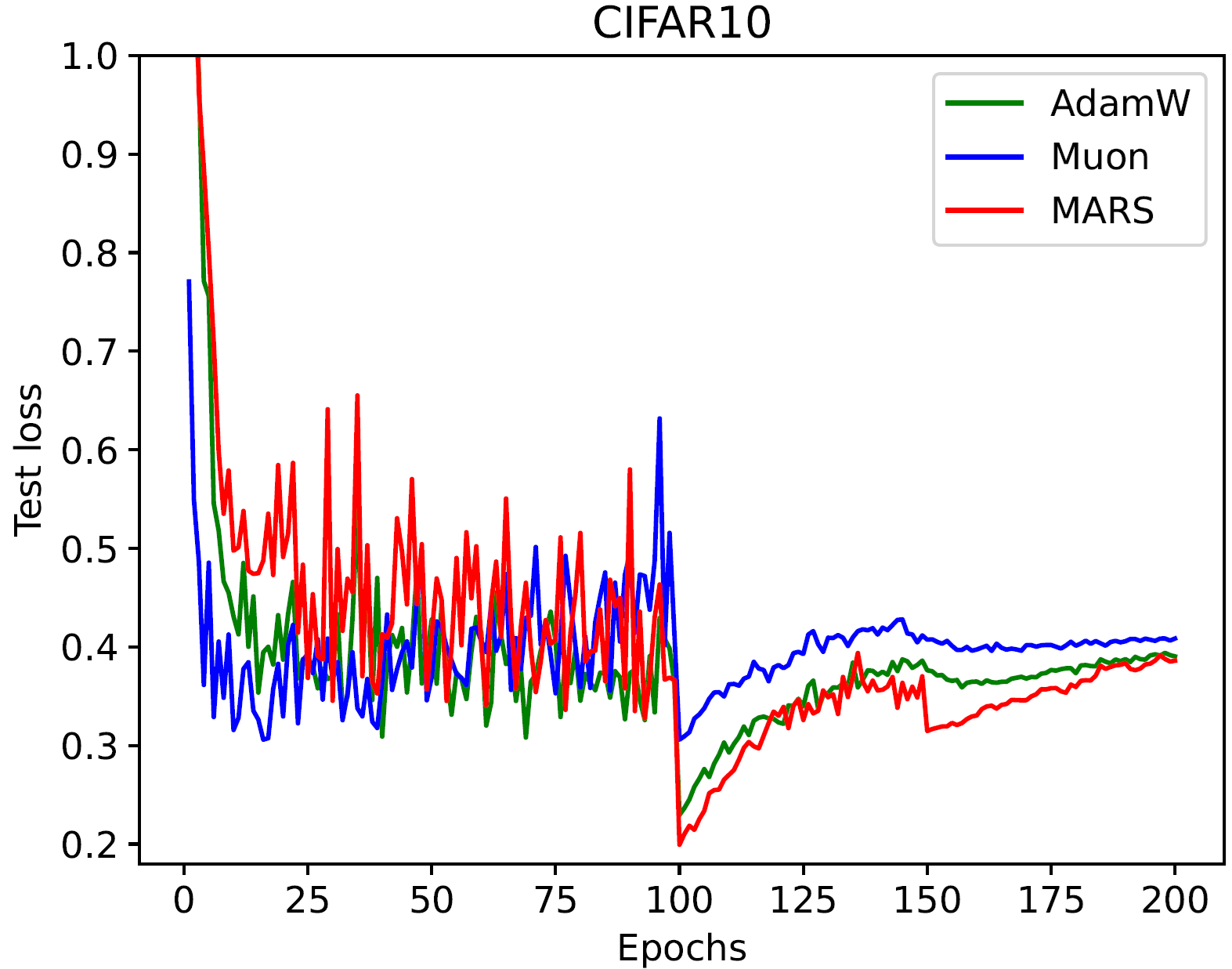 |
 |
| 测试准确率 | 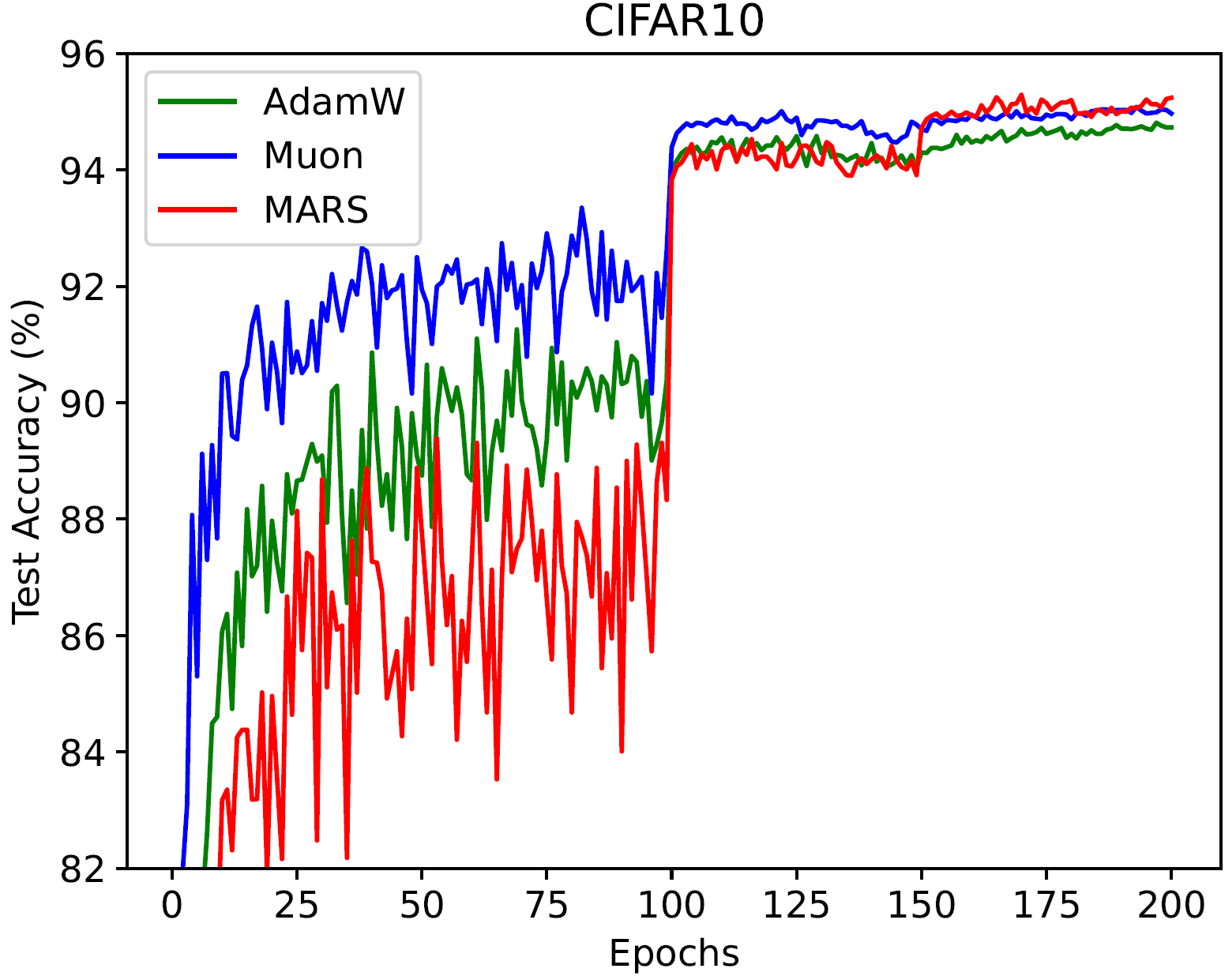 |
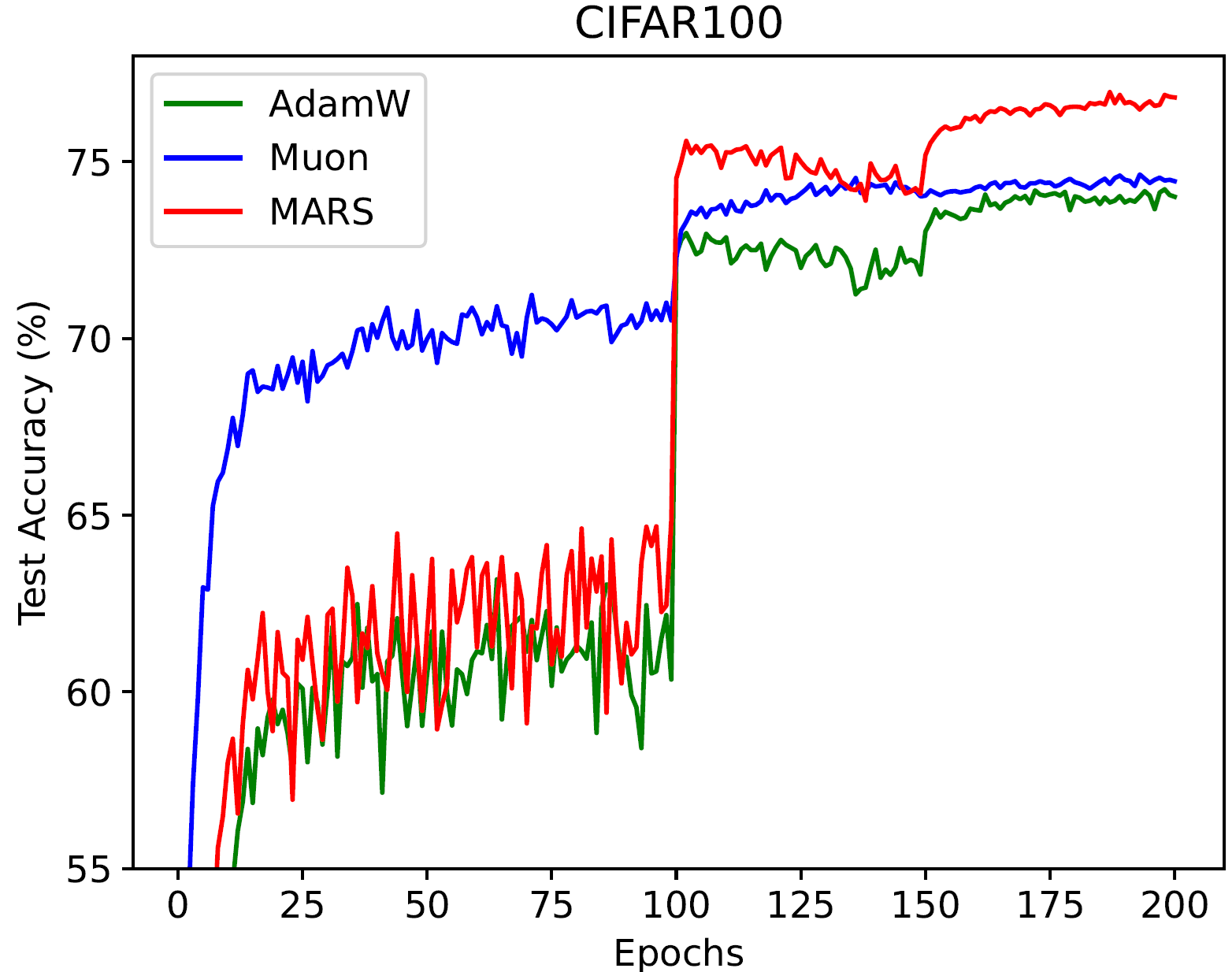 |
| 最佳测试损失 | CIFAR-10 | CIFAR-100 |
|---|---|---|
| AdamW | 0.306 | 2.608 |
| Muon | 0.230 | 1.726 |
| MARS-approx | 0.199 | 0.971 |
| 最佳测试准确率 (%) | CIFAR-10 | CIFAR-100 |
|---|---|---|
| AdamW | 94.81 | 73.7 |
| Muon | 95.08 | 74.64 |
| MARS-approx | 95.29 | 76.97 |
从头开始训练 GPT-2:
安装依赖
$ pip install torch==2.1.2 transformers==4.33.0 datasets tiktoken numpy==1.26.4 wandb
数据准备
按照 nanoGPT 的方式准备 OpenWebText 数据:
$ python data/openwebtext/prepare.py
开始训练
要使用 MARS 优化器训练模型,请运行以下命令:
$ torchrun --standalone --nproc_per_node=8 MARS/train_mars.py config/${your_config_file}
该命令将使用 MARS 优化器在 OpenWebText 数据集上启动 GPT-2 模型的训练。所有相关超参数——包括训练、模型和优化器——均在配置文件(${your_config_file})中指定。这些参数可以直接在配置文件中调整,也可以通过 Bash 脚本进行修改。
超参数详情
模型超参数:
- n_layer:网络层数,GPT2 Small 为 12 层,GPT2 Medium 为 24 层,GPT2 Large 为 36 层。
- n_head:注意力头数,GPT2 small 为 12 个,GPT2 Medium 为 16 个,GPT2 Large 为 20 个。
- n_embd:嵌入维度,GPT2 small 为 768,GPT2 Medium 为 1024,GPT2 Large 为 1280。
优化器超参数:
learning_rate:MARS 优化器的学习率。weight_decay:MARS 优化器的权重衰减。beta1, beta2:指数移动平均的权重。- 默认值:
beta1=0.95, beta2=0.99
- 默认值:
mars_type:使用的优化器类型:- 选项:
mars-adamw、mars-lion、mars-shampoo - 默认值:
mars-adamw
- 选项:
optimize_1d:是否让 MARS 优化一维参数(例如 GPT-2 中的层归一化参数)。- 如果为
False,则使用 AdamW 来优化一维参数。 - 默认值:
False
- 如果为
lr_1d:当optimize_1d设置为False时,AdamW 的学习率。betas_1d:AdamW 优化器中指数移动平均的权重。- 默认值:
(0.9, 0.95)
- 默认值:
is_approx:是否使用近似梯度计算(MARS-approx)。- 默认值:
True
- 默认值:
gamma:控制梯度修正强度的缩放参数。- 默认值:0.025
训练超参数:
batch_size:每个设备上的小批量大小。(例如,在 A100 GPU 上训练 GPT-2 Small 时,通常使用 15 的批量大小。)gradient_accumulation_steps:梯度累积步数,以确保总有效批量大小达到所需规模。(例如,对于总批量大小为 480 的情况:$15 \times 4 \times 8 , \text{GPUs}$。)schedule:学习率调度策略。- 默认值:
cosine
- 默认值:
更多详细的超参数示例,请参阅:
config/train_gpt2_small_mars.pyscripts/run_mars_small.sh
复现我们的结果
复现 GPT-2 Small (125M) 的结果
使用以下命令训练 MARS:
$ bash scripts/run_mars_small.sh
或者
$ torchrun --standalone --nproc_per_node=8 \
MARS/train_mars.py \
config/train_gpt2_small_mars.py \
--batch_size=15 \
--gradient_accumulation_steps=4
复现 GPT2 Medium (355M) 的结果
使用以下命令训练 MARS:
$ bash scripts/run_mars_medium.sh
或者
$ torchrun --standalone --nproc_per_node=8 \
MARS/train_mars.py \
config/train_gpt2_medium_mars.py \
--batch_size=15 \
--gradient_accumulation_steps=4
复现 GPT2 Large (770M) 的结果
使用以下命令训练 MARS:
$ bash scripts/run_mars_large.sh
或者
$ torchrun --standalone --nproc_per_node=8 \
MARS/train_mars.py \
config/train_gpt2_large_mars.py \
--batch_size=5 \
--gradient_accumulation_steps=12
在 FineWeb-Edu 上复现 GPT-2 XL (1.5B) 的结果
$ bash scripts/run_mars_xl_fw.sh
或者
$ torchrun --standalone --nproc_per_node=8 \
MARS/train_mars_fw.py \
config/train_gpt2_xl_mars.py \
--batch_size=5 \
--gradient_accumulation_steps=12
复现基线结果
要复现 AdamW 基线:
bash scripts/run_adamw_{small/medium/large}.sh
要在 FineWeb-Edu 上复现 AdamW 基线:
bash scripts/run_adamw_{small/xl}_fw.sh
要复现 Muon 基线,遵循 modded-nanogpt 的方法:
bash scripts/run_muon_{small/medium/large}.sh
请根据您使用的硬件配置相应调整 nproc_per_node、batch_size 和 gradient_accumulation_steps,确保它们的乘积等于 480。
GPT-2 模型的超参数
| 模型名称 | 模型大小 | AdamW 学习率 | Muon 学习率 | MARS 学习率 | MARS 一维学习率 | AdamW 权重衰减 | Muon 权重衰减 | MARS 权重衰减 |
|---|---|---|---|---|---|---|---|---|
| GPT-2 small | 125M | 6e-4 | 2e-2 | 6e-3 | 3e-3 | 1e-1 | 0.0 | 1e-2 |
| GPT-2 medium | 355M | 3e-4 | 1e-2 | 3e-3 | 1.5e-3 | 1e-1 | 0.0 | 1e-2 |
| GPT-2 large | 770M | 2e-4 | 6.67e-3 | 2e-3 | 1e-3 | 1e-1 | 0.0 | 1e-2 |
| GPT-2 xl | 1.5B | 2e-4 | - | 2e-3 | 1e-3 | 1e-1 | - | 1e-2 |
自定义训练
要构建针对其他架构和数据集的自定义训练流程,可以参考以下模板:
import torch
import torch.nn.functional as F
from mars import MARS
# 初始化模型损失函数和输入数据
model = Model()
data_loader = ...
# 初始化优化器
optimizer = MARS(model.parameters(), lr=1e-3, betas=(0.9, 0.95), gamma=0.025)
total_bs = len(data_loader)
bs = total_bs * block_size
k = 10
iter_num = -1
# 训练循环
for epoch in range(epochs):
for X, Y in data_loader:
# 标准训练代码
logits, loss = model(X, Y)
loss.backward()
optimizer.step(bs=bs)
optimizer.zero_grad(set_to_none=True)
optimizer.update_last_grad()
iter_num += 1
星标历史

引用
如果您觉得本仓库对您的研究有所帮助,请考虑引用以下论文:
@article{yuan2024mars,
title={MARS: Unleashing the Power of Variance Reduction for Training Large Models},
author={Yuan, Huizhuo and Liu, Yifeng and Wu, Shuang and Zhou, Xun and Gu, Quanquan},
journal={arXiv preprint arXiv:2411.10438},
year={2024}
}
致谢
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。