BettaFish
BettaFish(中文名“微舆”)是一款从零构建、不依赖任何重型框架的多智能体舆情分析助手。它旨在帮助用户打破“信息茧房”,通过自动化手段还原舆情的真实全貌,预测未来走向,从而为决策提供有力支持。
在信息爆炸的今天,个人和企业往往难以从海量且碎片化的社交媒体数据中提炼出有效洞察,容易陷入片面信息的误导。BettaFish 解决了这一痛点,用户只需像日常聊天一样提出分析需求,系统即可自动对国内外30多个主流社交平台(如微博、小红书、抖音等)的数百万条内容进行深度挖掘与分析。
这款工具非常适合需要敏锐洞察市场动态的企业决策者、品牌公关人员、市场研究人员,以及对社会热点感兴趣并希望获得客观深度报告的普通用户。同时,由于其轻量级和模块化的 Python 架构,开发者也能轻松将其集成到自有业务中,或定制为金融分析等其他领域的数据引擎。
BettaFish 的技术亮点在于其独特的“多智能体论坛”协作机制。它并非单纯依赖大语言模型,而是融合了微调模型、统计模型以及具备不同思维模式的各类 Agent。通过引入辩论主持人角色,让不同 Agent 进行思维碰撞与辩论,有效避免了单一模型的局限性。此外,它还具备强大的多模态处理能力,能深入解析短视频内容,并支持公私域数据无缝融合,确保分析结果兼具广度、深度与真实性。
使用场景
某新消费品牌市场总监正面临新品上市后的口碑危机,急需在24小时内厘清社交媒体上的负面评价根源,并制定应对策略,以避免品牌形象受损。
没有 BettaFish 时
- 数据盲区严重:人工只能覆盖微博、小红书等头部平台,难以兼顾抖音、快手等短视频评论区及垂直论坛,导致大量真实用户反馈被遗漏,形成严重的“信息茧房”。
- 分析效率低下:面对数百万条杂乱评论,团队需花费数天时间进行手动清洗和分类,无法实时响应突发舆情,决策往往滞后于事态发展。
- 观点主观片面:依赖个别分析师的经验判断,容易带入个人偏见,缺乏多维度的交叉验证,难以区分是产品质量问题还是恶意竞争抹黑。
- 非结构化数据难处理:对于短视频中的语音、画面情绪以及天气、股票等外部关联因素,传统工具无法有效提取和关联分析,导致归因逻辑断裂。
使用 BettaFish 后
- 全域实时监控:BettaFish 的 AI 爬虫集群自动覆盖国内外 30+ 主流社媒,不仅捕获图文,更深度解析短视频内容,确保无死角还原舆情原貌。
- 智能即时洞察:通过多 Agent 协作机制,系统在几分钟内完成海量数据的清洗、情感分析与热点聚类,自动生成深度报告,将响应时间从“天”级缩短至“分钟”级。
- 客观多维辩论:引入“论坛”辩论机制,不同角色的 Agent 对数据进行交叉验证与思维碰撞,有效破除单一模型局限,精准识别负面舆情的真实成因(如物流延误而非产品缺陷)。
- 内外数据融合:支持将内部客服数据与外部舆情无缝集成,结合结构化信息卡片,提供“外部趋势+内部洞察”的综合决策依据,辅助制定精准的公关策略。
BettaFish 通过自动化、多维度的群体智能分析,帮助企业在复杂舆论场中快速去伪存真,将被动应对转化为主动决策,显著提升品牌风险管理能力。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始








[!IMPORTANT]
查看我们最新发布的预测引擎:MiroFish-简洁通用的群体智能引擎,预测万物
“数据分析三板斧”全线贯通:我们激动的宣布 MiroFish 正式发布!随着最后一块版图补齐,我们构建了从 BettaFish(数据收集与分析)到 MiroFish(全景预测)的完整链路。至此,从原始数据到智能决策的闭环已成,让预见未来成为可能!
⚡ 项目概述
“微舆” 是一个从0实现的创新型 多智能体 舆情分析系统,帮助大家破除信息茧房,还原舆情原貌,预测未来走向,辅助决策。用户只需像聊天一样提出分析需求,智能体开始全自动分析 国内外30+主流社媒 与 数百万条大众评论。
“微舆”谐音“微鱼”,BettaFish是一种体型很小但非常好斗、漂亮的鱼,它象征着“小而强大,不畏挑战”
查看系统以“武汉大学舆情”为例,生成的研究报告:武汉大学品牌声誉深度分析报告
查看系统以“武汉大学舆情”为例,一次完整运行的视频:视频-武汉大学品牌声誉深度分析报告
不仅仅体现在报告质量上,相比同类产品,我们拥有🚀六大优势:
AI驱动的全域监控:AI爬虫集群7x24小时不间断作业,全面覆盖微博、小红书、抖音、快手等10+国内外关键社媒。不仅实时捕获热点内容,更能下钻至海量用户评论,让您听到最真实、最广泛的大众声音。
超越LLM的复合分析引擎:我们不仅依赖设计的5类专业Agent,更融合了微调模型、统计模型等中间件。通过多模型协同工作,确保了分析结果的深度、准度与多维视角。
强大的多模态能力:突破图文限制,能深度解析抖音、快手等短视频内容,并精准提取现代搜索引擎中的天气、日历、股票等结构化多模态信息卡片,让您全面掌握舆情动态。
Agent“论坛”协作机制:为不同Agent赋予独特的工具集与思维模式,引入辩论主持人模型,通过“论坛”机制进行链式思维碰撞与辩论。这不仅避免了单一模型的思维局限与交流导致的同质化,更催生出更高质量的集体智能与决策支持。
公私域数据无缝融合:平台不仅分析公开舆情,还提供高安全性的接口,支持您将内部业务数据库与舆情数据无缝集成。打通数据壁垒,为垂直业务提供“外部趋势+内部洞察”的强大分析能力。
轻量化与高扩展性框架:基于纯Python模块化设计,实现轻量化、一键式部署。代码结构清晰,开发者可轻松集成自定义模型与业务逻辑,实现平台的快速扩展与深度定制。
始于舆情,而不止于舆情。“微舆”的目标,是成为驱动一切业务场景的简洁通用的数据分析引擎。
举个例子. 你只需简单修改Agent工具集的api参数与prompt,就可以把他变成一个金融领域的市场分析系统
附一个比较活跃的L站项目讨论帖:https://linux.do/t/topic/1009280
查看L站佬友做的测评 开源项目(微舆)与manus|minimax|ChatGPT|Perplexity对比
告别传统的数据看板,在“微舆”,一切由一个简单的问题开始,您只需像对话一样,提出您的分析需求
🪄 赞助商
LLM模型API赞助:![]()
AI联网搜索、文件解析及网页内容抓取等智能体核心能力提供商:
安思派开放平台(Anspire Open)是面向智能体时代的领先的基础设施提供商。我们为开发者提供构建强大智能体所需的核心能力栈,现已上线AI联网搜索【多版本,极具竞争力的价格】、文件解析【限免】及网页内容抓取【限免】、云端浏览器自动化(Anspire Browser Agent)【内测】、多轮改写等服务,持续为智能体连接并操作复杂的数字世界提供坚实基础。可无缝集成至Dify、Coze、元器等主流智能体平台。通过透明点数计费体系与模块化设计,为企业提供高效、低成本的定制化支持,加速智能化升级进程。
🏗️ 系统架构
整体架构图
Insight Agent 私有数据库挖掘:私有舆情数据库深度分析AI代理
Media Agent 多模态内容分析:具备强大多模态能力的AI代理
Query Agent 精准信息搜索:具备国内外网页搜索能力的AI代理
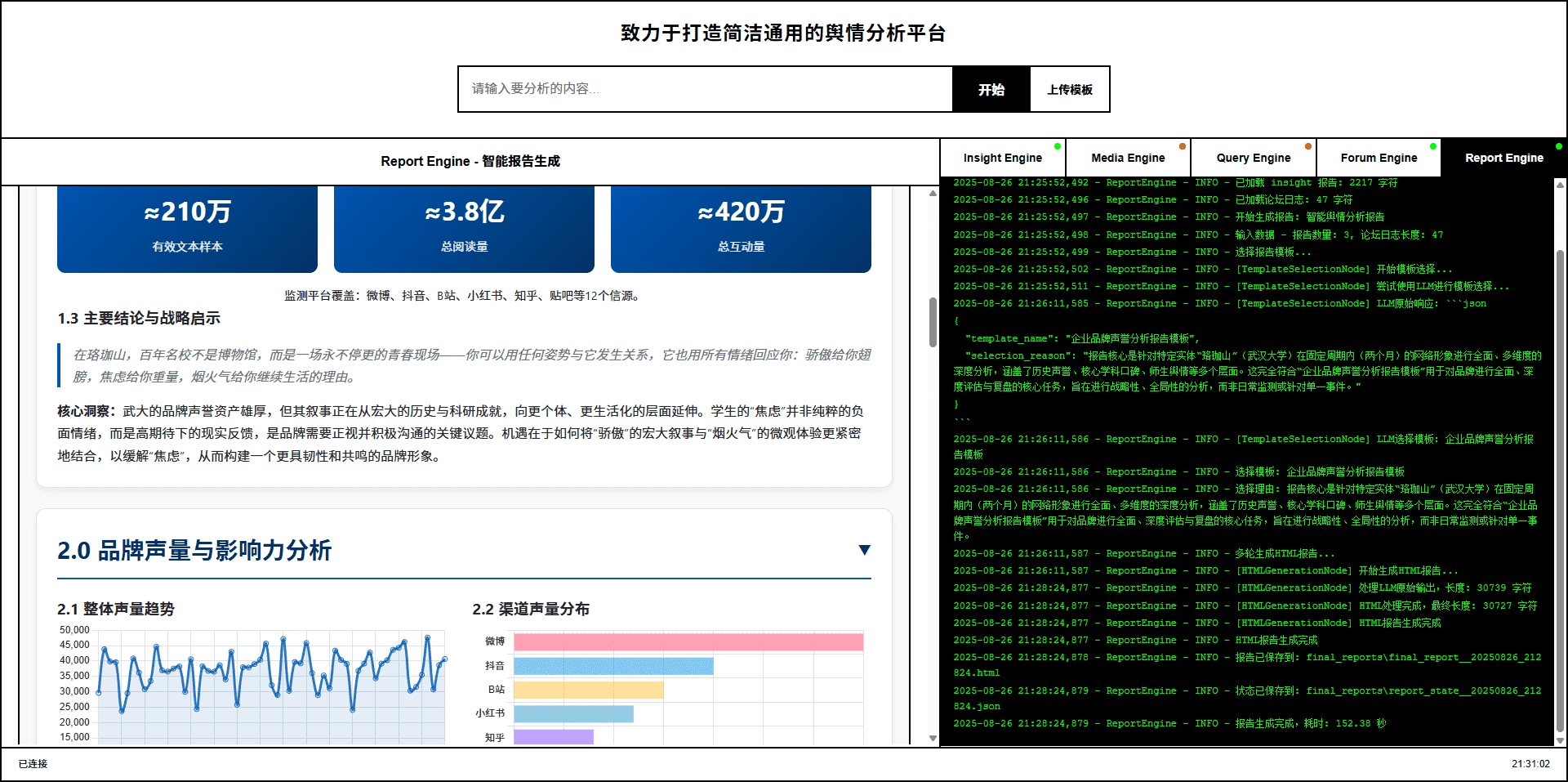
Report Agent 智能报告生成:内置模板的多轮报告生成AI代理
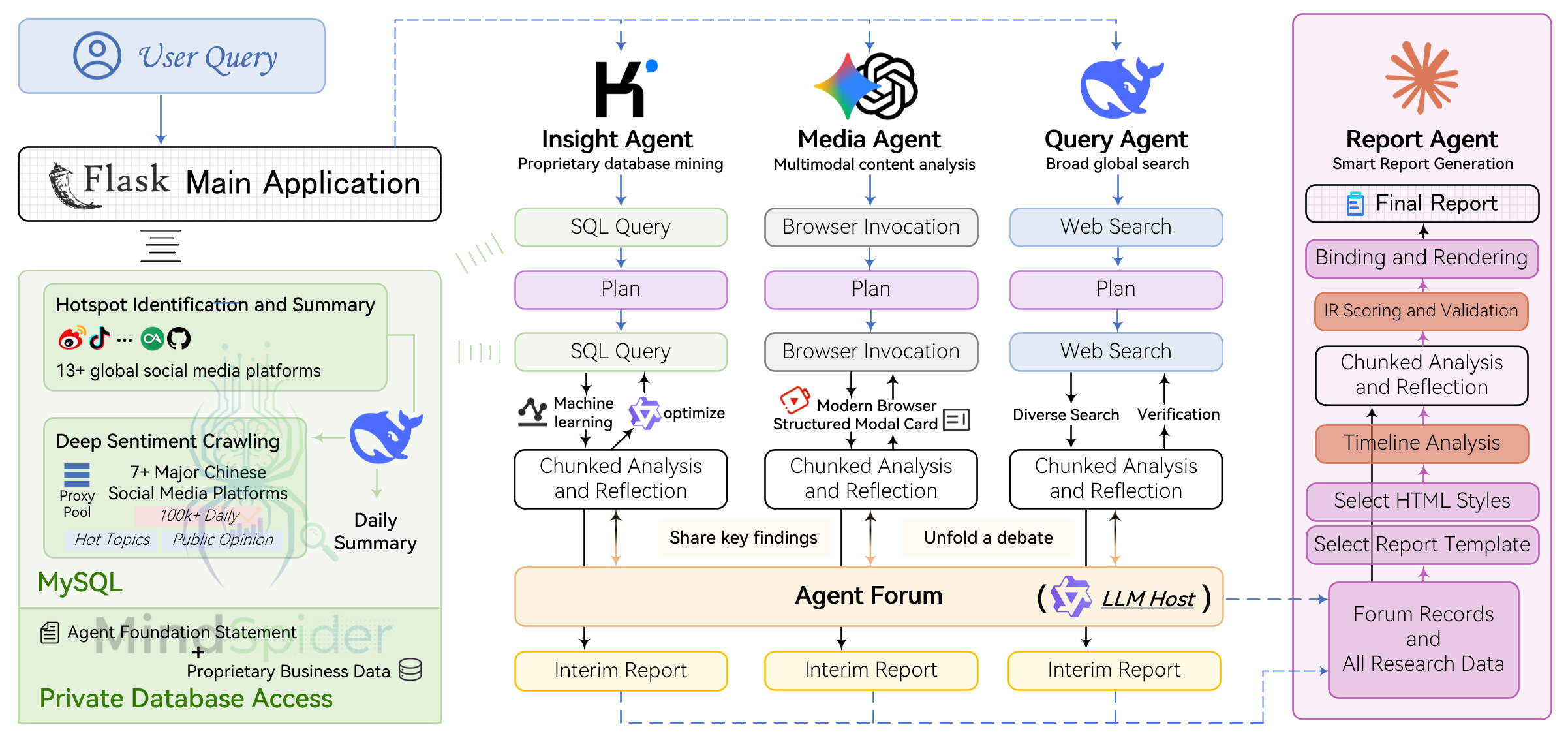
一次完整分析流程
| 步骤 | 阶段名称 | 主要操作 | 参与组件 | 循环特性 |
|---|---|---|---|---|
| 1 | 用户提问 | Flask主应用接收查询 | Flask主应用 | - |
| 2 | 并行启动 | 三个Agent同时开始工作 | Query Agent、Media Agent、Insight Agent | - |
| 3 | 初步分析 | 各Agent使用专属工具进行概览搜索 | 各Agent + 专属工具集 | - |
| 4 | 策略制定 | 基于初步结果制定分块研究策略 | 各Agent内部决策模块 | - |
| 5-N | 循环阶段 | 论坛协作 + 深度研究 | ForumEngine + 所有Agent | 多轮循环 |
| 5.1 | 深度研究 | 各Agent基于论坛主持人引导进行专项搜索 | 各Agent + 反思机制 + 论坛引导 | 每轮循环 |
| 5.2 | 论坛协作 | ForumEngine监控Agent发言并生成主持人引导 | ForumEngine + LLM主持人 | 每轮循环 |
| 5.3 | 交流融合 | 各Agent根据讨论调整研究方向 | 各Agent + forum_reader工具 | 每轮循环 |
| N+1 | 结果整合 | Report Agent收集所有分析结果和论坛内容 | Report Agent | - |
| N+2 | IR中间表示 | 动态选择模板和样式,多轮生成元数据,装订为IR中间表示 | Report Agent + 模板引擎 | - |
| N+3 | 报告生成 | 分块进行质量检测,基于IR渲染成交互式 HTML 报告 | Report Agent + 装订引擎 | - |
项目代码结构树
BettaFish/
├── QueryEngine/ # 国内外新闻广度搜索Agent
│ ├── agent.py # Agent主逻辑,协调搜索与分析流程
│ ├── llms/ # LLM接口封装
│ ├── nodes/ # 处理节点:搜索、格式化、总结等
│ ├── tools/ # 国内外新闻搜索工具集
│ ├── utils/ # 工具函数
│ ├── state/ # 状态管理
│ ├── prompts/ # 提示词模板
│ └── ...
├── MediaEngine/ # 强大的多模态理解Agent
│ ├── agent.py # Agent主逻辑,处理视频/图片等多模态内容
│ ├── llms/ # LLM接口封装
│ ├── nodes/ # 处理节点:搜索、格式化、总结等
│ ├── tools/ # 多模态搜索工具集
│ ├── utils/ # 工具函数
│ ├── state/ # 状态管理
│ ├── prompts/ # 提示词模板
│ └── ...
├── InsightEngine/ # 私有数据库挖掘Agent
│ ├── agent.py # Agent主逻辑,协调数据库查询与分析
│ ├── llms/ # LLM接口封装
│ │ └── base.py # 统一的OpenAI兼容客户端
│ ├── nodes/ # 处理节点:搜索、格式化、总结等
│ │ ├── base_node.py # 基础节点类
│ │ ├── search_node.py # 搜索节点
│ │ ├── formatting_node.py # 格式化节点
│ │ ├── report_structure_node.py # 报告结构节点
│ │ └── summary_node.py # 总结节点
│ ├── tools/ # 数据库查询和分析工具集
│ │ ├── keyword_optimizer.py # Qwen关键词优化中间件
│ │ ├── search.py # 数据库操作工具集(话题搜索、评论获取等)
│ │ └── sentiment_analyzer.py # 情感分析集成工具
│ ├── utils/ # 工具函数
│ │ ├── config.py # 配置管理
│ │ ├── db.py # SQLAlchemy异步引擎与只读查询封装
│ │ └── text_processing.py # 文本处理工具
│ ├── state/ # 状态管理
│ │ └── state.py # Agent状态定义
│ ├── prompts/ # 提示词模板
│ │ └── prompts.py # 各类提示词
│ └── __init__.py
├── ReportEngine/ # 多轮报告生成Agent
│ ├── agent.py # 总调度器:模板选择→布局→篇幅→章节→渲染
│ ├── flask_interface.py # Flask/SSE入口,管理任务排队与流式事件
│ ├── llms/ # OpenAI兼容LLM封装
│ │ └── base.py # 统一的流式/重试客户端
│ ├── core/ # 核心功能:模板解析、章节存储、文档装订
│ │ ├── template_parser.py # Markdown模板切片与slug生成
│ │ ├── chapter_storage.py # 章节run目录、manifest与raw流写入
│ │ └── stitcher.py # Document IR装订器,补齐锚点/元数据
│ ├── ir/ # 报告中间表示(IR)契约与校验
│ │ ├── schema.py # 块/标记Schema常量定义
│ │ └── validator.py # 章节JSON结构校验器
│ ├── nodes/ # 全流程推理节点
│ │ ├── base_node.py # 节点基类+日志/状态钩子
│ │ ├── template_selection_node.py # 模板候选收集与LLM筛选
│ │ ├── document_layout_node.py # 标题/目录/主题设计
│ │ ├── word_budget_node.py # 篇幅规划与章节指令生成
│ │ ──└── chapter_generation_node.py # 章节级JSON生成+校验
│ ├── prompts/ # 提示词库与Schema说明
│ │ ──└── prompts.py # 模板选择/布局/篇幅/章节提示词
│ ├── renderers/ # IR渲染器
│ │ ├── html_renderer.py # Document IR→交互式HTML
│ │ ├── pdf_renderer.py # HTML→PDF导出(WeasyPrint)
│ │ ├── pdf_layout_optimizer.py # PDF布局优化器
│ │ ──└── chart_to_svg.py # 图表转SVG工具
│ ├── state/ # 任务/元数据状态模型
│ │ ──└── state.py # ReportState与序列化工具
│ ├── utils/ # 配置与辅助工具
│ │ ├── config.py # Pydantic Settings与打印助手
│ │ ├── dependency_check.py # 依赖检查工具
│ │ ├── json_parser.py # JSON解析工具
│ │ ├── chart_validator.py # 图表校验工具
│ │ ──└── chart_repair_api.py # 图表修复API
│ ├── report_template/ # Markdown模板库
│ │ ├── 企业品牌声誉分析报告.md
│ │ ──└── ...
│ ──└── __init__.py
├── ForumEngine/ # 论坛引擎:Agent协作机制
│ ├── monitor.py # 日志监控和论坛管理核心
│ ├── llm_host.py # 论坛主持人LLM模块
│ ──└── __init__.py
├── MindSpider/ # 社交媒体爬虫系统
│ ├── main.py # 爬虫主程序入口
│ ├── config.py # 爬虫配置文件
│ ├── BroadTopicExtraction/ # 话题提取模块
│ │ ├── main.py # 话题提取主程序
│ │ ├── database_manager.py # 数据库管理器
│ │ ├── get_today_news.py # 今日新闻获取
│ │ ──└── topic_extractor.py # 话题提取器
│ ├── DeepSentimentCrawling/ # 深度舆情爬取模块
│ │ ├── main.py # 深度爬取主程序
│ │ ├── keyword_manager.py # 关键词管理器
│ │ ├── platform_crawler.py # 平台爬虫管理
│ │ ──└── MediaCrawler/ # 社媒爬虫核心
│ │ ├── main.py
│ │ ├── config/ # 各平台配置
│ │ ├── media_platform/ # 各平台爬虫实现
│ │ ──└── ...
│ ──└── schema/ # 数据库结构定义
│ ├── db_manager.py # 数据库管理器
│ ├── init_database.py # 数据库初始化脚本
│ ├── mindspider_tables.sql # 数据库表结构SQL
│ ├── models_bigdata.py # 大规模媒体舆情表的SQLAlchemy映射
│ ──└── models_sa.py # DailyTopic/Task等扩展表ORM模型
├── SentimentAnalysisModel/ # 情感分析模型集合
│ ├── WeiboSentiment_Finetuned/ # 微调BERT/GPT-2模型
│ │ ├── BertChinese-Lora/ # BERT中文LoRA微调
│ │ │ ├── train.py
│ │ │ ├── predict.py
│ │ │ ──└── ...
│ │ ──└── GPT2-Lora/ # GPT-2 LoRA微调
│ │ ├── train.py
│ │ ├── predict.py
│ │ ──└── ...
│ ├── WeiboMultilingualSentiment/ # 多语言情感分析
│ │ ├── train.py
│ │ ├── predict.py
│ │ ──└── ...
│ ├── WeiboSentiment_SmallQwen/ # 小参数Qwen3微调
│ │ ├── train.py
│ │ ├── predict_universal.py
│ │ ──└── ...
│ ──└── WeiboSentiment_MachineLearning/ # 传统机器学习方法
│ ├── train.py
│ ├── predict.py
│ ──└── ...
├── SingleEngineApp/ # 单独Agent的Streamlit应用
│ ├── query_engine_streamlit_app.py # QueryEngine独立应用
│ ├── media_engine_streamlit_app.py # MediaEngine独立应用
│ ──└── insight_engine_streamlit_app.py # InsightEngine独立应用
├── query_engine_streamlit_reports/ # QueryEngine单应用运行输出
├── media_engine_streamlit_reports/ # MediaEngine单应用运行输出
├── insight_engine_streamlit_reports/ # InsightEngine单应用运行输出
├── templates/ # Flask前端模板
│ ──└── index.html # 主界面HTML
├── static/ # 静态资源
│ ├── image/ # 图片资源
│ │ ──└── ...
│ ├── Partial README for PDF Exporting/ # PDF导出依赖配置说明
│ ──└── v2_report_example/ # 报告渲染示例
│ ──└── report_all_blocks_demo/ # 全块类型演示(HTML/PDF/MD)
├── logs/ # 运行日志目录
├── final_reports/ # 最终生成的报告文件
│ ├── ir/ # 报告IR JSON文件
│ ──└── *.html # 最终HTML报告
├── utils/ # 通用工具函数
│ ├── forum_reader.py # Agent间论坛通信工具
│ ├── github_issues.py # 统一生成GitHub Issue链接与错误提示
│ ──└── retry_helper.py # 网络请求重试机制工具
├── tests/ # 单元测试与集成测试
│ ├── run_tests.py # pytest入口脚本
│ ├── test_monitor.py # ForumEngine监控单元测试
│ ├── test_report_engine_sanitization.py # ReportEngine安全性测试
│ ──└── ...
├── app.py # Flask主应用入口
├── config.py # 全局配置文件
├── .env.example # 环境变量示例文件
├── docker-compose.yml # Docker多服务编排配置
├── Dockerfile # Docker镜像构建文件
├── requirements.txt # Python依赖包清单
├── regenerate_latest_html.py # 使用最新章节重装订并渲染HTML
├── regenerate_latest_md.py # 使用最新章节重装订并渲染Markdown
├── regenerate_latest_pdf.py # PDF重新生成工具脚本
├── report_engine_only.py # Report Engine命令行版本
├── README.md # 中文说明文档
├── README-EN.md # 英文说明文档
├── CONTRIBUTING.md # 中文贡献指南
├── CONTRIBUTING-EN.md # 英文贡献指南
└── LICENSE # GPL-2.0开源许可证
🚀 快速开始(Docker)
1. 启动项目
复制一份 .env.example 文件,命名为 .env ,并按需配置 .env 文件中的环境变量
执行以下命令在后台启动所有服务:
docker compose up -d
注:镜像拉取速度慢,在原
docker-compose.yml文件中,我们已经通过注释的方式提供了备用镜像地址供您替换
2. 配置说明
数据库配置(PostgreSQL)
请按照以下参数配置数据库连接信息,也支持Mysql可自行修改:
| 配置项 | 填写值 | 说明 |
|---|---|---|
DB_HOST |
db |
数据库服务名称 (对应 docker-compose.yml 中的服务名) |
DB_PORT |
5432 |
默认 PostgreSQL 端口 |
DB_USER |
bettafish |
数据库用户名 |
DB_PASSWORD |
bettafish |
数据库密码 |
DB_NAME |
bettafish |
数据库名称 |
| 其他 | 保持默认 | 数据库连接池等其他参数请保持默认设置。 |
大模型配置
我们所有 LLM 调用使用 OpenAI 的 API 接口标准
在完成数据库配置后,请正常配置所有大模型相关的参数,确保系统能够连接到您选择的大模型服务。
完成上述所有配置并保存后,系统即可正常运行。
🔧 源码启动指南
如果你是初次学习一个Agent系统的搭建,可以从一个非常简单的demo开始:Deep Search Agent Demo
环境要求
- 操作系统: Windows、Linux、MacOS
- Python版本: 3.9+
- Conda: Anaconda或Miniconda
- 数据库: PostgreSQL(推荐)或MySQL
- 内存: 建议2GB以上
1. 创建环境
如果使用Conda
# 创建conda环境
conda create -n your_conda_name python=3.11
conda activate your_conda_name
如果使用uv
# 创建uv环境
uv venv --python 3.11 # 创建3.11环境
2. 安装 PDF 导出所需系统依赖(可选)
这部分有详细的配置说明:配置所需依赖
3. 安装依赖包
如果跳过了步骤2,weasyprint库可能无法安装,PDF功能可能无法正常使用。
# 基础依赖安装
pip install -r requirements.txt
# uv版本命令(更快速安装)
uv pip install -r requirements.txt
# 如果不想使用本地情感分析模型(算力需求很小,默认安装cpu版本),可以将该文件中的"机器学习"部分注释掉再执行指令
4. 安装Playwright浏览器驱动
# 安装浏览器驱动(用于爬虫功能)
playwright install chromium
5. 配置LLM与数据库
复制一份项目根目录 .env.example 文件,命名为 .env
编辑 .env 文件,填入您的API密钥(您也可以选择自己的模型、搜索代理,详情见根目录.env.example文件内或根目录config.py中的说明):
# ====================== 数据库配置 ======================
# 数据库主机,例如localhost 或 127.0.0.1
DB_HOST=your_db_host
# 数据库端口号,默认为3306
DB_PORT=3306
# 数据库用户名
DB_USER=your_db_user
# 数据库密码
DB_PASSWORD=your_db_password
# 数据库名称
DB_NAME=your_db_name
# 数据库字符集,推荐utf8mb4,兼容emoji
DB_CHARSET=utf8mb4
# 数据库类型postgresql或mysql
DB_DIALECT=postgresql
# 数据库不需要初始化,执行app.py时会自动检测
# ====================== LLM配置 ======================
# 您可以更改每个部分LLM使用的API,只要兼容OpenAI请求格式都可以
# 配置文件内部给了每一个Agent的推荐LLM,初次部署请先参考推荐设置
# Insight Agent
INSIGHT_ENGINE_API_KEY=
INSIGHT_ENGINE_BASE_URL=
INSIGHT_ENGINE_MODEL_NAME=
# Media Agent
...
6. 启动系统
6.1 完整系统启动(推荐)
# 在项目根目录下,激活conda环境
conda activate your_conda_name
# 启动主应用即可
python app.py
uv 版本启动命令
# 在项目根目录下,激活uv环境
.venv\Scripts\activate
# 启动主应用即可
python app.py
注1:一次运行终止后,streamlit app可能结束异常仍然占用端口,此时搜索占用端口的进程kill掉即可
注2:数据爬取需要单独操作,见6.3指引
访问 http://localhost:5000 即可使用完整系统
6.2 单独启动某个Agent
# 启动QueryEngine
streamlit run SingleEngineApp/query_engine_streamlit_app.py --server.port 8503
# 启动MediaEngine
streamlit run SingleEngineApp/media_engine_streamlit_app.py --server.port 8502
# 启动InsightEngine
streamlit run SingleEngineApp/insight_engine_streamlit_app.py --server.port 8501
6.3 爬虫系统单独使用
这部分有详细的配置文档:MindSpider使用说明

MindSpider 运行示例
# 进入爬虫目录
cd MindSpider
# 项目初始化
python main.py --setup
# 运行话题提取(获取热点新闻和关键词)
python main.py --broad-topic
# 运行完整爬虫流程
python main.py --complete --date 2024-01-20
# 仅运行话题提取
python main.py --broad-topic --date 2024-01-20
# 仅运行深度爬取
python main.py --deep-sentiment --platforms xhs dy wb
6.4 命令行报告生成工具
该工具会跳过三个分析引擎的运行阶段,直接读取它们的最新日志文件,并在无需 Web 界面的情况下生成综合报告(同时省略文件增量校验步骤),默认会在 PDF 之后自动生成 Markdown(可用参数关闭)。通常用于对报告生成结果不满意、需要快速重试的场景,或在调试 Report Engine 时启用。
# 基本使用(自动从文件名提取主题)
python report_engine_only.py
# 指定报告主题
python report_engine_only.py --query "土木工程行业分析"
# 跳过PDF生成(即使系统支持)
python report_engine_only.py --skip-pdf
# 跳过Markdown生成
python report_engine_only.py --skip-markdown
# 显示详细日志
python report_engine_only.py --verbose
# 查看帮助信息
python report_engine_only.py --help
功能说明:
- 自动检查依赖:程序会自动检查PDF生成所需的系统依赖,如果缺失会给出安装提示
- 获取最新文件:自动从三个引擎目录(
insight_engine_streamlit_reports、media_engine_streamlit_reports、query_engine_streamlit_reports)获取最新的分析报告 - 文件确认:显示所有选择的文件名、路径和修改时间,等待用户确认(默认输入
y继续,输入n退出) - 直接生成报告:跳过文件增加审核程序,直接调用Report Engine生成综合报告
- 自动保存文件:
- HTML报告保存到
final_reports/目录 - PDF报告(如果有依赖)保存到
final_reports/pdf/目录 - Markdown报告(可用
--skip-markdown关闭)保存到final_reports/md/目录 - 文件命名格式:
final_report_{主题}_{时间戳}.html/pdf/md
- HTML报告保存到
注意事项:
- 确保三个引擎目录中至少有一个包含
.md报告文件 - 命令行工具与Web界面相互独立,不会相互影响
- PDF生成需要安装系统依赖,详见上文"安装 PDF 导出所需系统依赖"部分
快速重渲染最新结果:
regenerate_latest_html.py/regenerate_latest_md.py:从CHAPTER_OUTPUT_DIR中最新一次运行的章节 JSON 重装订 Document IR,并直接渲染 HTML 或 Markdown。regenerate_latest_pdf.py:读取final_reports/ir里最新的 IR,使用 SVG 矢量图表重新导出 PDF。
⚙️ 高级配置(已过时,已经统一为项目根目录.env文件管理,其他子agent自动继承根目录配置)
修改关键参数
Agent配置参数
每个Agent都有专门的配置文件,可根据需求调整,下面是部分示例:
# QueryEngine/utils/config.py
class Config:
max_reflections = 2 # 反思轮次
max_search_results = 15 # 最大搜索结果数
max_content_length = 8000 # 最大内容长度
# MediaEngine/utils/config.py
class Config:
comprehensive_search_limit = 10 # 综合搜索限制
web_search_limit = 15 # 网页搜索限制
# InsightEngine/utils/config.py
class Config:
default_search_topic_globally_limit = 200 # 全局搜索限制
default_get_comments_limit = 500 # 评论获取限制
max_search_results_for_llm = 50 # 传给LLM的最大结果数
情感分析模型配置
# InsightEngine/tools/sentiment_analyzer.py
SENTIMENT_CONFIG = {
'model_type': 'multilingual', # 可选: 'bert', 'multilingual', 'qwen'等
'confidence_threshold': 0.8, # 置信度阈值
'batch_size': 32, # 批处理大小
'max_sequence_length': 512, # 最大序列长度
}
接入不同的LLM模型
支持任意openAI调用格式的LLM提供商,只需要在/config.py中填写对应的KEY、BASE_URL、MODEL_NAME即可。
什么是openAI调用格式?下面提供一个简单的例子:
from openai import OpenAI client = OpenAI(api_key="your_api_key", base_url="https://aihubmix.com/v1") response = client.chat.completions.create( model="gpt-4o-mini", messages=[ {'role': 'user', 'content': "推理模型会给市场带来哪些新的机会"} ], ) complete_response = response.choices[0].message.content print(complete_response)
更改情感分析模型
系统集成了多种情感分析方法,可根据需求选择:
1. 多语言情感分析
cd SentimentAnalysisModel/WeiboMultilingualSentiment
python predict.py --text "This product is amazing!" --lang "en"
2. 小参数Qwen3微调
cd SentimentAnalysisModel/WeiboSentiment_SmallQwen
python predict_universal.py --text "这次活动办得很成功"
3. 基于BERT的微调模型
# 使用BERT中文模型
cd SentimentAnalysisModel/WeiboSentiment_Finetuned/BertChinese-Lora
python predict.py --text "这个产品真的很不错"
4. GPT-2 LoRA微调模型
cd SentimentAnalysisModel/WeiboSentiment_Finetuned/GPT2-Lora
python predict.py --text "今天心情不太好"
5. 传统机器学习方法
cd SentimentAnalysisModel/WeiboSentiment_MachineLearning
python predict.py --model_type "svm" --text "服务态度需要改进"
接入自定义业务数据库
1. 修改数据库连接配置
# config.py 中添加您的业务数据库配置
BUSINESS_DB_HOST = "your_business_db_host"
BUSINESS_DB_PORT = 3306
BUSINESS_DB_USER = "your_business_user"
BUSINESS_DB_PASSWORD = "your_business_password"
BUSINESS_DB_NAME = "your_business_database"
2. 创建自定义数据访问工具
# InsightEngine/tools/custom_db_tool.py
class CustomBusinessDBTool:
"""自定义业务数据库查询工具"""
def __init__(self):
self.connection_config = {
'host': config.BUSINESS_DB_HOST,
'port': config.BUSINESS_DB_PORT,
'user': config.BUSINESS_DB_USER,
'password': config.BUSINESS_DB_PASSWORD,
'database': config.BUSINESS_DB_NAME,
}
def search_business_data(self, query: str, table: str):
"""查询业务数据"""
# 实现您的业务逻辑
pass
def get_customer_feedback(self, product_id: str):
"""获取客户反馈数据"""
# 实现客户反馈查询逻辑
pass
3. 集成到InsightEngine
# InsightEngine/agent.py 中集成自定义工具
from .tools.custom_db_tool import CustomBusinessDBTool
class DeepSearchAgent:
def __init__(self, config=None):
# ... 其他初始化代码
self.custom_db_tool = CustomBusinessDBTool()
def execute_custom_search(self, query: str):
"""执行自定义业务数据搜索"""
return self.custom_db_tool.search_business_data(query, "your_table")
自定义报告模板
1. 在Web界面中上传
系统支持上传自定义模板文件(.md或.txt格式),可在生成报告时选择使用。
2. 创建模板文件
在 ReportEngine/report_template/ 目录下创建新的模板,我们的Agent会自行选用最合适的模板。
🤝 贡献指南
我们欢迎所有形式的贡献!
请阅读以下贡献指南:
🦖 下一步开发计划
现在系统完成了最后一步预测!访问查看【MiroFish-预测万物】:https://github.com/666ghj/MiroFish

⚠️ 免责声明
重要提醒:本项目仅供学习、学术研究和教育目的使用
合规性声明:
- 本项目中的所有代码、工具和功能均仅供学习、学术研究和教育目的使用
- 严禁将本项目用于任何商业用途或盈利性活动
- 严禁将本项目用于任何违法、违规或侵犯他人权益的行为
爬虫功能免责:
- 项目中的爬虫功能仅用于技术学习和研究目的
- 使用者必须遵守目标网站的robots.txt协议和使用条款
- 使用者必须遵守相关法律法规,不得进行恶意爬取或数据滥用
- 因使用爬虫功能产生的任何法律后果由使用者自行承担
数据使用免责:
- 项目涉及的数据分析功能仅供学术研究使用
- 严禁将分析结果用于商业决策或盈利目的
- 使用者应确保所分析数据的合法性和合规性
技术免责:
- 本项目按"现状"提供,不提供任何明示或暗示的保证
- 作者不对使用本项目造成的任何直接或间接损失承担责任
- 使用者应自行评估项目的适用性和风险
责任限制:
- 使用者在使用本项目前应充分了解相关法律法规
- 使用者应确保其使用行为符合当地法律法规要求
- 因违反法律法规使用本项目而产生的任何后果由使用者自行承担
请在使用本项目前仔细阅读并理解上述免责声明。使用本项目即表示您已同意并接受上述所有条款。
📄 许可证
本项目采用 GPL-2.0许可证。详细信息请参阅LICENSE文件。
🎉 支持与联系
获取帮助
常见问题解答:https://github.com/666ghj/BettaFish/issues/185
- 项目主页:GitHub仓库
- 问题反馈:Issues页面
- 功能建议:Discussions页面
联系方式
商务合作
- 企业定制开发
- 大数据服务
- 学术合作
- 技术培训
👥 贡献者
感谢以下优秀的贡献者们:

🌟 加入官方交流群


📈 项目统计


版本历史
v3.0.02025/12/23v2.1.02025/12/09v2.0.02025/11/28v1.2.02025/11/08v1.1.02025/11/04v1.0.02025/09/01常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。