k8s-vgpu-scheduler
k8s-vgpu-scheduler(现更名为 Project-HAMi)是一款专为 Kubernetes 集群设计的 GPU 资源管理调度器。它旨在解决传统模式下 GPU 必须整卡分配导致的资源浪费问题,特别适用于显存和算力利用率较低的场景,如多模型推理服务、教学环境或云端小实例部署。
该工具主要面向需要在 K8s 上高效运行 AI 工作负载的开发者、运维工程师及研究人员。其核心亮点在于实现了细粒度的 GPU 资源共享:用户不再受限于独占整张显卡,而是可以按需申请特定的显存大小(如 3000MB)或算力比例。此外,k8s-vgpu-scheduler 支持“虚拟显存”技术,允许利用主机内存作为交换空间,使任务能够突破物理显存限制,从而运行更大批量的模型训练或容纳更多并发任务。
安装后,无需修改现有的任务配置文件即可自动启用增强功能,同时支持指定使用或避开特定类型的 GPU 设备。通过智能调度算法,它还能在多个 GPU 节点间平衡负载,显著提升集群整体的资源利用率和经济性,是让 AI 基础设施更灵活、高效的关键组件。
使用场景
某云教育平台需在有限的 GPU 集群上,同时支撑数百名学生进行深度学习模型训练与推理实验。
没有 k8s-vgpu-scheduler 时
- 资源严重浪费:每个学生任务必须独占整张物理显卡,即便模型仅需 1GB 显存,也会占用整卡 16GB,导致大量算力闲置。
- 并发能力受限:由于无法切分显卡,集群只能串行处理少量任务,学生排队等待时间过长,教学效率低下。
- 大模型无法运行:部分进阶课程需要加载超大模型,显存需求超过物理上限,直接导致任务启动失败(OOM)。
- 调度缺乏灵活性:管理员无法指定任务使用特定型号显卡或限制其显存用量,难以精细化管理集群负载。
使用 k8s-vgpu-scheduler 后
- 实现细粒度共享:支持将单张物理 GPU 切分为多个虚拟实例,每位学生可按需分配如"2GB 显存 +20% 算力”,资源利用率提升数倍。
- 大幅提升并发:同一张显卡可同时承载多个轻量级训练任务,学生无需排队,实验吞吐量显著增加。
- 突破显存物理限制:开启虚拟显存功能后,利用主机内存作为交换空间,成功运行了原本因显存不足而失败的大批量训练任务。
- 智能调度与隔离:通过注解灵活指定显卡类型或避免使用某些节点,并严格限制每个任务的显存边界,防止相互干扰。
k8s-vgpu-scheduler 通过显存虚拟化与细粒度切分技术,将昂贵的 GPU 资源从“独占奢侈品”转变为可高效共享的“公共服务”,极大降低了 AI 教学与研发的门槛。
运行环境要求
- Linux
- 必需
- 支持 NVIDIA GPU (驱动>=384.81), Cambricon MLU, Hygon DCU
- 需安装 nvidia-docker > 2.0 及 nvidia-container-toolkit
- 显存大小和 CUDA 版本取决于具体物理显卡,工具支持指定显存大小(如 3000M)或使用百分比,并支持显存超分(虚拟显存)
未说明(取决于宿主机及任务需求,开启虚拟显存功能时利用宿主机内存作为交换空间)

快速开始
英文版|中文版
OpenAIOS Kubernetes vGPU 调度器
![]()

支持的设备
注意 本项目已更名为 project-HAMi,我们保留旧仓库以确保兼容性。
简介
4paradigm k8s vGPU调度器是一个用于在Kubernetes集群中管理GPU的“一体化”解决方案,它具备您对Kubernetes GPU管理工具的所有期望功能,包括:
GPU共享:每个任务可以分配部分GPU资源,而不是整张GPU卡,从而实现多任务之间的GPU资源共享。
设备内存控制:GPU可以按固定大小(如3000M)或占总显存的百分比(如50%)进行分配,并确保不会超出限制。
虚拟设备内存:通过使用主机内存作为交换空间,您可以超额分配GPU设备内存。
GPU类型指定:您可以通过设置nvidia.com/use-gputype或nvidia.com/nouse-gputype注解来指定某个GPU任务应使用或避免使用的GPU类型。
易于使用:您无需修改任务的YAML文件即可使用我们的调度器。安装完成后,所有GPU作业都会自动得到支持。此外,如果您愿意,还可以将资源名称指定为nvidia.com/gpu以外的其他名称。
k8s vGPU调度器基于4paradigm k8s-device-plugin(4paradigm/k8s-device-plugin)的功能扩展,例如物理GPU的分割、内存和计算单元的限制等。在此基础上,它增加了调度模块,以平衡不同GPU节点之间的GPU使用情况。此外,用户还可以通过指定设备内存和计算核心的使用量来分配GPU资源。更进一步地,vGPU调度器能够虚拟化设备内存(实际使用的设备内存可以超过物理显存),从而运行一些需要大量显存的任务,或者增加共享任务的数量。有关详细信息,请参阅基准测试报告。
使用场景
- 当Pod需要按特定的设备内存用量或计算核心数分配资源时。
- 需要在包含多个GPU节点的集群中均衡GPU资源使用时。
- 设备内存和计算单元利用率较低的情况,例如在一张GPU上运行10个TensorFlow Serving实例。
- 需要大量小型GPU资源的场景,例如教学环境中为多名学生共享一台GPU,或云平台提供小型GPU实例。
- 在物理设备内存不足的情况下,可以启用虚拟设备内存功能,例如训练大规模数据集和大型模型时。
先决条件
以下是运行NVIDIA设备插件所需的先决条件:
- NVIDIA驱动程序 ≥ 384.81
- nvidia-docker版本 > 2.0
- Kubernetes版本 ≥ 1.16
- glibc ≥ 2.17
- 内核版本 ≥ 3.10
- Helm > 3.0
快速开始
准备您的GPU节点
以下步骤需要在所有GPU节点上执行。
本README假定NVIDIA驱动程序和nvidia-container-toolkit已经预先安装好。
同时假设您已将nvidia-container-runtime配置为默认的底层运行时。
请参阅:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html
基于Debian系统的docker和containerd示例
安装nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/libnvidia-container.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
配置docker
当使用docker运行kubernetes时,编辑通常位于/etc/docker/daemon.json的配置文件,将nvidia-container-runtime设置为默认的底层运行时:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
然后重启docker:
$ sudo systemctl daemon-reload && systemctl restart docker
配置containerd
当使用containerd运行kubernetes时,编辑通常位于/etc/containerd/config.toml的配置文件,将nvidia-container-runtime设置为默认的底层运行时:
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
然后重启containerd:
$ sudo systemctl daemon-reload && systemctl restart containerd
之后,您需要为可由4pd-k8s-scheduler调度的GPU节点打上标签gpu=on,否则这些节点将无法被我们的调度器管理。
kubectl label nodes {nodeid} gpu=on
在 Kubernetes 中启用 vGPU 支持
首先,您需要使用以下命令检查您的 Kubernetes 版本:
kubectl version
然后,在 Helm 中添加我们的仓库:
helm repo add vgpu-charts https://4paradigm.github.io/k8s-vgpu-scheduler
在安装过程中,您需要根据您的 Kubernetes 服务器版本设置 Kubernetes 调度器镜像版本。例如,如果您的集群服务器版本是 1.16.8,则应使用以下命令进行部署:
helm install vgpu vgpu-charts/vgpu --set scheduler.kubeScheduler.imageTag=v1.16.8 -n kube-system
您可以通过调整 配置来自定义安装。
您可以通过以下命令验证安装是否成功:
$ kubectl get pods -n kube-system
如果 vgpu-device-plugin 和 vgpu-scheduler 这两个 Pod 处于 Running 状态,则说明您的安装已成功。
运行 GPU 作业
现在,容器可以使用 nvidia.com/gpu 资源类型来请求 NVIDIA vGPU:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 2 # 请求 2 个 vGPU
nvidia.com/gpumem: 3000 # 每个 vGPU 包含 3000m 设备内存(可选,整数)
nvidia.com/gpucores: 30 # 每个 vGPU 使用整个 GPU 的 30%(可选,整数)
请注意,如果任务无法分配到任何 GPU 节点上(即您请求的 nvidia.com/gpu 数量超过了任何节点上的 GPU 数量),该任务将陷入 pending 状态。
现在您可以在容器中执行 nvidia-smi 命令,并查看 vGPU 和物理 GPU 之间的显存差异。
警告: 如果您在使用 NVIDIA 镜像的设备插件时未请求 vGPU,机器上的所有 vGPU 将暴露在您的容器中。
更多示例
点击 这里 查看更多示例。
调度器 Webhook 服务 NodePort
默认调度器端口为 31998,您可以在安装时使用 --set deivcePlugin.service.schedulerPort 来设置其他值。
监控 vGPU 状态
安装后会自动启用监控功能。您可以通过访问以下地址获取节点的 vGPU 状态:
http://{nodeip}:{monitorPort}/metrics
默认监控端口为 31992,您可以在安装时使用 --set deivcePlugin.service.httpPort 来设置其他值。
Grafana 仪表板 示例
注意 在进行任何 GPU 操作之前,不会收集节点的状态信息。
升级
要将 k8s-vGPU 升级到最新版本,您只需更新仓库并重新启动 Chart 即可:
$ helm uninstall vgpu -n kube-system
$ helm repo update
$ helm install vgpu vgpu -n kube-system
卸载
helm uninstall vgpu -n kube-system
调度
当前的调度策略是选择任务最少的 GPU,从而在多个 GPU 之间均衡负载。
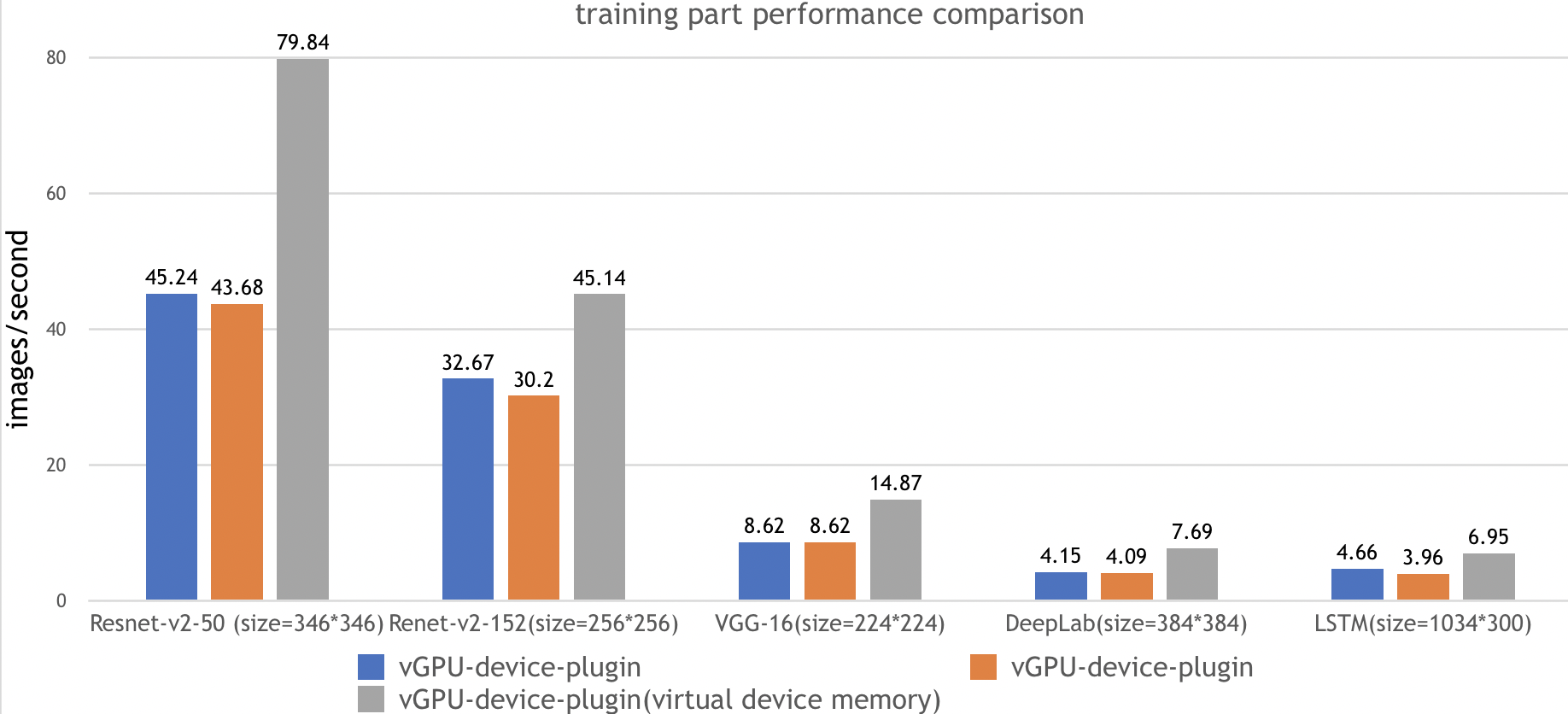
基准测试
我们使用了 ai-benchmark 中的三个实例来评估 vGPU 设备插件的性能,具体如下:
| 测试环境 | 描述 |
|---|---|
| Kubernetes 版本 | v1.12.9 |
| Docker 版本 | 18.09.1 |
| GPU 类型 | Tesla V100 |
| GPU 数量 | 2 |
| 测试实例 | 描述 |
|---|---|
| nvidia-device-plugin | k8s + nvidia k8s-device-plugin |
| vGPU-device-plugin | k8s + VGPU k8s-device-plugin,不使用虚拟设备内存 |
| vGPU-device-plugin(使用虚拟设备内存) | k8s + VGPU k8s-device-plugin,使用虚拟设备内存 |
测试用例:
| 测试编号 | 案例 | 类型 | 参数 |
|---|---|---|---|
| 1.1 | Resnet-V2-50 | 推理 | batch=50,size=346*346 |
| 1.2 | Resnet-V2-50 | 训练 | batch=20,size=346*346 |
| 2.1 | Resnet-V2-152 | 推理 | batch=10,size=256*256 |
| 2.2 | Resnet-V2-152 | 训练 | batch=10,size=256*256 |
| 3.1 | VGG-16 | 推理 | batch=20,size=224*224 |
| 3.2 | VGG-16 | 训练 | batch=2,size=224*224 |
| 4.1 | DeepLab | 推理 | batch=2,size=512*512 |
| 4.2 | DeepLab | 训练 | batch=1,size=384*384 |
| 5.1 | LSTM | 推理 | batch=100,size=1024*300 |
| 5.2 | LSTM | 训练 | batch=10,size=1024*300 |
测试结果: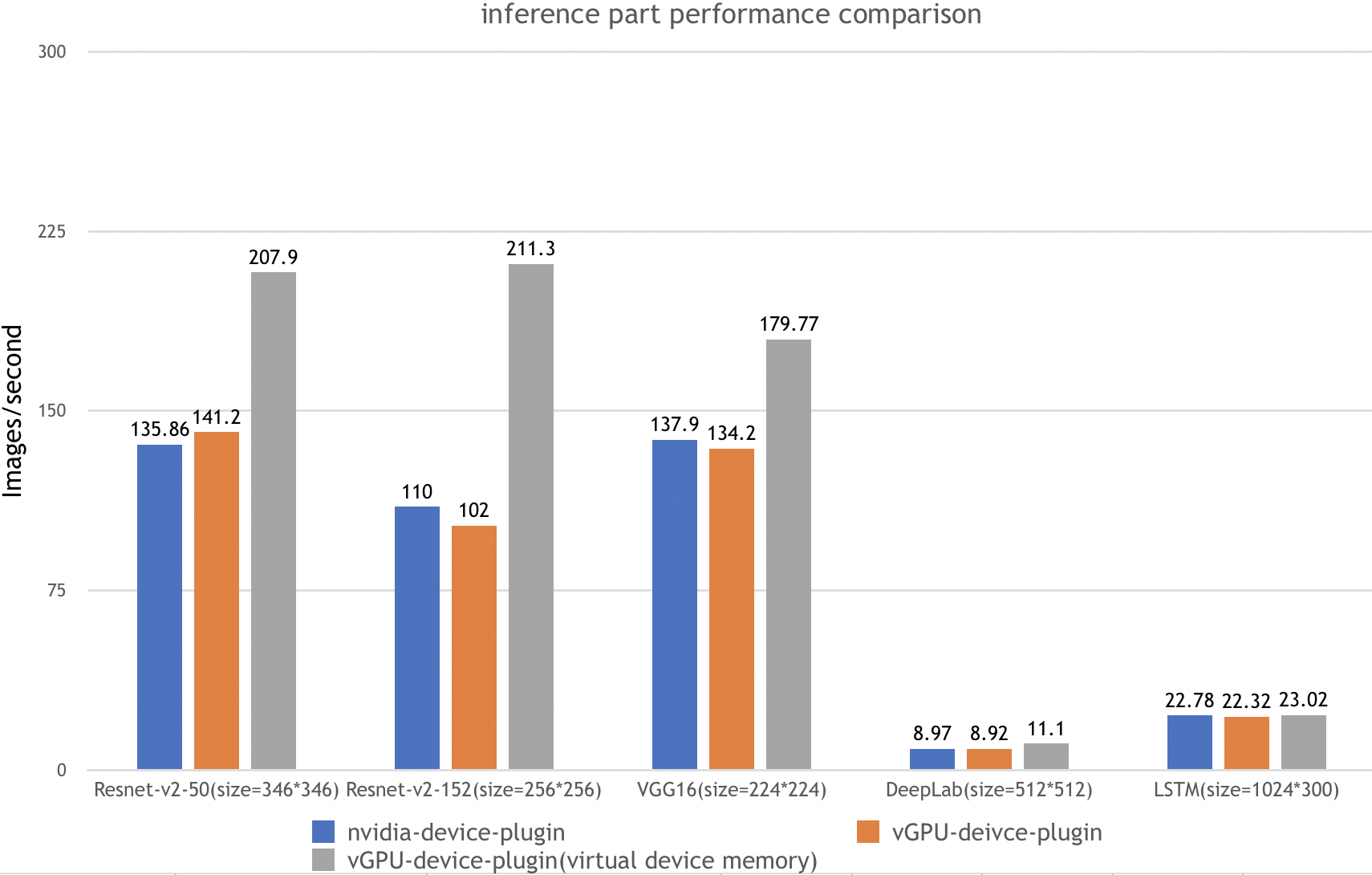
重现步骤:
- 安装 k8s-vGPU 调度器,并正确配置。
- 运行基准测试作业。
$ kubectl apply -f benchmarks/ai-benchmark/ai-benchmark.yml
- 使用 kubctl logs 查看结果。
$ kubectl logs [pod id]
功能
- 可以指定每个物理 GPU 分配的 vGPU 数量。
- 限制 vGPU 的设备内存。
- 允许通过指定设备内存来分配 vGPU。
- 限制 vGPU 的流式多处理器。
- 允许通过指定设备核心使用率来分配 vGPU。
- 对现有程序无需任何修改。
实验性功能
虚拟设备内存
vGPU 的设备内存可以超过 GPU 的物理设备内存。此时,超出部分将被存储在 RAM 中,这会对性能产生一定影响。
已知问题
- 目前 A100 MIG 仅支持“none”和“mixed”模式。
- 目前带有 “nodeName” 字段的任务无法被调度,请改用 “nodeSelector”。
- 目前仅支持计算任务,不支持视频编解码处理。
待办事项
- 支持视频编解码处理。
- 支持多实例 GPU (MIG)。
测试
- TensorFlow 1.14.0/2.4.1
- torch 1.1.0
- mxnet 1.4.0
- mindspore 1.1.1
以上框架均已通过测试。
问题与贡献
作者
- 李孟轩 (limengxuan@4paradigm.com)
- 裴兆友 (peizhaoyou@4paradigm.com)
- 史广川 (shiguangchuan@4paradigm.com)
- 郑钊 (zhengzhao@4paradigm.com)
联系方式
负责人及维护者:李孟轩
欢迎通过以下方式联系我:
邮箱:<limengxuan@4paradigm.com>
电话:+86 18810644493
微信:xuanzong4493
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。