Yi
Yi 是由零一万物(01.AI)从头训练的一系列开源大型语言模型,旨在打造下一代强大的双语人工智能助手。它基于 3 万亿 token 的多语言语料库进行训练,在语言理解、常识推理及阅读理解等核心能力上表现卓越,有效解决了高质量开源模型稀缺以及中英文场景下性能不平衡的痛点。
在技术亮点方面,Yi 系列模型在全球权威评测中屡获佳绩。其中,Yi-34B-Chat 曾在 AlpacaEval 榜单上位居全球第二,仅次于 GPT-4 Turbo,超越了包括 Claude 和 Mixtral 在内的众多知名模型;其基座模型也在开源界名列前茅,展现了极高的智能水平。此外,项目提供了完善的生态支持,涵盖从快速部署、量化压缩到微调训练的全流程工具链,并兼容多种主流推理框架。
Yi 非常适合各类用户群体:开发者可将其作为构建智能应用的坚实基座,轻松集成到现有系统中;研究人员能利用其开源权重深入探索大模型机制或进行垂直领域微调;企业用户则可借助其出色的双语能力优化客服、翻译等业务场景。无论是希望体验顶尖 AI 技术的普通爱好者,还是追求高效落地的专业团队,Yi 都是一个值得信赖的选择。
使用场景
某跨境电商公司的技术团队需要构建一个能同时处理海量英文产品评论和中文客服工单的智能分析系统,以实时提取用户情感倾向并生成回复建议。
没有 Yi 时
- 语言割裂严重:团队需分别部署英文和中文两套模型,导致架构复杂且维护成本高昂,难以实现双语上下文关联分析。
- 推理延迟过高:通用小模型在长文本(如详细评测)上表现不佳,而调用国外顶尖闭源 API 不仅网络延迟大,还面临数据出境合规风险。
- 领域适配困难:开源模型在电商垂直领域的术语理解上偏差较大,微调后容易出现“灾难性遗忘”,丢失原有的多语言能力。
- 资源消耗巨大:为了兼顾精度与速度,不得不采购昂贵的 GPU 集群来运行多个冗余模型,算力预算经常超标。
使用 Yi 后
- 原生双语统一:利用 Yi 基于 3T 多语料从头训练的特性,单模型即可完美覆盖中英混合输入,无需切换上下文,架构简化为单一服务。
- 性能与合规兼得:Yi-34B-Chat 在 AlpacaEval 等榜单表现接近 GPT-4 Turbo,本地化部署既消除了网络延迟,又确保了敏感用户数据不出境。
- 垂直领域精准:凭借强大的基座能力,仅需少量电商数据进行微调,Yi 就能准确识别“物流时效”、“材质触感”等专业术语的情感色彩。
- 降本增效显著:得益于高效的推理优化,团队在同等算力下吞吐量提升明显,大幅降低了单位请求的硬件成本。
Yi 以其卓越的原生双语能力和开源灵活性,帮助企业在保障数据主权的前提下,用更低成本实现了媲美顶尖闭源模型的业务智能化升级。
运行环境要求
- 未说明
未说明(文中提及支持量化版本如 4-bit/8-bit 以降低硬件门槛,但未列出具体显存或 CUDA 版本要求)
未说明
快速开始
English | 中文
构建下一代开源双语大模型
🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel
👩🚀 在 GitHub 上提问或讨论想法
📝 查看 Yi 技术报告
📚 在 Yi 学习中心 不断成长
💪 在 Yi 技术博客 学习更多知识
📕 目录
什么是 Yi?
简介
🤖 Yi 系列模型是由 01.AI 从零开始训练的下一代开源大型语言模型。
🙌 作为一款双语语言模型,Yi 系列模型基于 3T 多语言语料库进行训练,已成为全球最强大的 LLM 之一,在语言理解、常识推理、阅读理解等方面表现出色。例如:
Yi-34B-Chat 模型在 AlpacaEval 排行榜上位居第二(仅次于 GPT-4 Turbo),超越了 GPT-4、Mixtral、Claude 等其他 LLM(数据截至 2024 年 1 月)。
Yi-34B 模型在多个基准测试中,包括 Hugging Face Open LLM Leaderboard(预训练)和 C-Eval(数据截至 2023 年 11 月),在英语和中文两个语种中均排名第一,领先于 Falcon-180B、Llama-70B、Claude 等现有开源模型。
🙏 (感谢 Llama)得益于 Transformer 和 Llama 开源社区的努力,它们大大减少了从零构建模型所需的工作量,并使得 AI 生态系统中的工具得以共享使用。
如果你对 Yi 如何采用 Llama 架构以及其许可使用政策感兴趣,请参阅 Yi 与 Llama 的关系。 ⬇️
💡 TL;DR
Yi 系列模型采用了与 Llama 相同的模型架构,但并非 Llama 的衍生品。
Yi 和 Llama 都基于 Transformer 结构,自 2018 年以来,Transformer 已成为大型语言模型的标准架构。
基于 Transformer 架构,Llama 凭借其出色的稳定性、可靠的收敛性和强大的兼容性,已成为大多数先进开源模型的新基石,也因此被公认为包括 Yi 在内的诸多模型的基础框架。
正是由于 Transformer 和 Llama 架构的存在,其他模型能够充分利用其优势,从而减少从零构建模型所需的努力,并在各自的生态系统中共享使用相同的工具。
然而,Yi 系列模型并非 Llama 的衍生品,因为它们并未使用 Llama 的权重。
由于大多数开源模型都采用了 Llama 的结构,决定模型性能的关键因素在于训练数据集、训练流程以及训练基础设施。
Yi 以独特且自主的方式,完全从头开始构建了高质量的训练数据集、高效的训练流程以及稳健的训练基础设施。正是这些努力使 Yi 系列模型取得了优异的成绩,其性能紧随 GPT4 之后,并在 2023 年 12 月的 [Alpaca 排行榜] 上超越了 Llama。
[ 返回顶部 ⬆️ ]
新闻
🔥 2024-07-29: Yi Cookbook 1.0 正式发布,包含中英文教程与示例。
🎯 2024-05-13: Yi-1.5 系列模型 开源,进一步提升了代码、数学、推理及指令遵循能力。
🎯 2024-03-16: Yi-9B-200K 已开源并面向公众开放。
🎯 2024-03-08: Yi 技术报告 发表!
🔔 2024-03-07: Yi-34B-200K 的长文本处理能力得到增强。
在“大海捞针”测试中,Yi-34B-200K 的表现提升了 10.5%,从 89.3% 提升至令人印象深刻的 99.8%。我们仍在使用 50 亿 token 的长上下文数据混合集对该模型进行预训练,并展现出近乎全绿的成绩。
🎯 2024-03-06: Yi-9B 已开源并面向公众开放。
Yi-9B 在一系列类似规模的开源模型中(包括 Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5 等)表现最为突出,尤其在代码、数学、常识推理和阅读理解方面表现出色。
🎯 2024-01-23: Yi-VL 模型,Yi-VL-34B 和 Yi-VL-6B, 已开源并面向公众开放。
Yi-VL-34B 在最新基准测试中,包括 MMMU 和 CMMMU(基于截至 2024 年 1 月的数据),在所有现有开源模型中位居第一。
🎯 2023-11-23: 聊天模型 已开源并面向公众开放。
本次发布包含两款基于先前发布的基础模型的聊天模型、两款由 GPTQ 量化的 8 位模型,以及两款由 AWQ 量化的 4 位模型。
Yi-34B-ChatYi-34B-Chat-4bitsYi-34B-Chat-8bitsYi-6B-ChatYi-6B-Chat-4bitsYi-6B-Chat-8bits
您可以在以下平台交互体验部分模型:
🔔 2023-11-23: Yi 系列模型社区许可协议更新至 v2.1。
🎯 2023-11-05: 基础模型,Yi-6B-200K 和 Yi-34B-200K, 已开源并面向公众开放。
本次发布包含两款与此前版本参数规模相同的基础模型,区别在于上下文窗口扩展至 20 万 token。
🎯 2023-11-02: 基础模型,Yi-6B 和 Yi-34B, 已开源并面向公众开放。
首次公开发布包含两款双语(英/中)的基础模型,参数规模分别为 60 亿和 340 亿。两者均以 4 千序列长度进行训练,推理时可扩展至 3.2 万。
[ 返回顶部 ⬆️ ]
模型
Yi 模型拥有多种尺寸,可满足不同应用场景的需求。您还可以对 Yi 模型进行微调,以更好地适配您的具体要求。
如果您希望部署 Yi 模型,请确保满足软硬件要求。
聊天模型
| 模型 | 下载 |
|---|---|
| Yi-34B-Chat | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-34B-Chat-4bits | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-34B-Chat-8bits | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-6B-Chat | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-6B-Chat-4bits | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-6B-Chat-8bits | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
- 4 位系列模型采用 AWQ 量化。
- 8 位系列模型采用 GPTQ 量化。
- 所有量化后的模型使用门槛较低,可在消费级 GPU 上部署(如 3090、4090)。
基础模型
| 模型 | 下载 |
|---|---|
| Yi-34B | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-34B-200K | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-9B | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-9B-200K | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-6B | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-6B-200K | • 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
- 200k 大致相当于 40 万汉字。
- 如果您想使用 Yi-34B-200K 的旧版本(于 2023 年 11 月 5 日发布),请运行 git checkout 069cd341d60f4ce4b07ec394e82b79e94f656cf 来下载权重。
模型信息
- 对于聊天和基础模型
| 模型 | 简介 | 默认上下文窗口 | 预训练 token 数量 | 训练数据日期 |
|---|---|---|---|---|
| 6B 系列模型 | 它们适用于个人和学术用途。 | 4K | 3T | 截至 2023 年 6 月 |
| 9B 系列模型 | 它是 Yi 系列模型中在编码和数学方面表现最好的。 | Yi-9B 是在 Yi-6B 的基础上持续训练的,使用了 0.8T 的 token。 | ||
| 34B 系列模型 | 它们适用于个人、学术以及商业用途(尤其是中小企业)。这是一种经济实惠且具备涌现能力的成本效益解决方案。 | 3T |
对于聊天模型
关于聊天模型的局限性,请参阅下方说明。⬇️
- 幻觉:指模型生成事实不正确或不合逻辑的信息。随着模型回复变得更加多样化,出现基于不准确数据或缺乏逻辑推理的幻觉的可能性也会增加。
- 重新生成时的非确定性:在尝试重新生成或采样回复时,可能会出现结果不一致的情况。多样性的增加可能导致即使在相似的输入条件下,也会产生不同的结果。
- 累积误差:当模型回复中的错误随着时间推移而不断累积时就会发生这种情况。随着模型生成更多样化的回复,小的不准确性逐渐积累成较大误差的可能性会增加,尤其是在复杂的任务中,如长篇推理、数学问题求解等。
- 为了获得更加连贯和一致的回复,建议调整生成配置参数,例如温度、top_p 或 top_k。这些调整有助于在模型输出的创造性和连贯性之间取得平衡。
发布的聊天模型经过了监督微调(SFT)的专属训练。与其他标准聊天模型相比,我们的模型能够产生更多样化的回复,因此适用于各种下游任务,例如创意场景。此外,这种多样性有望提高生成更高质量回复的可能性,这将有利于后续的强化学习(RL)训练。
然而,这种更高的多样性可能会放大某些现有问题,包括:
[ 返回顶部 ⬆️ ]
如何使用 Yi?
快速入门
💡 提示: 如果您想开始使用 Yi 模型并探索不同的推理方法,请查看 Yi 烹饪书。
选择你的路径
请选择以下其中一个路径,开始你与 Yi 的旅程!
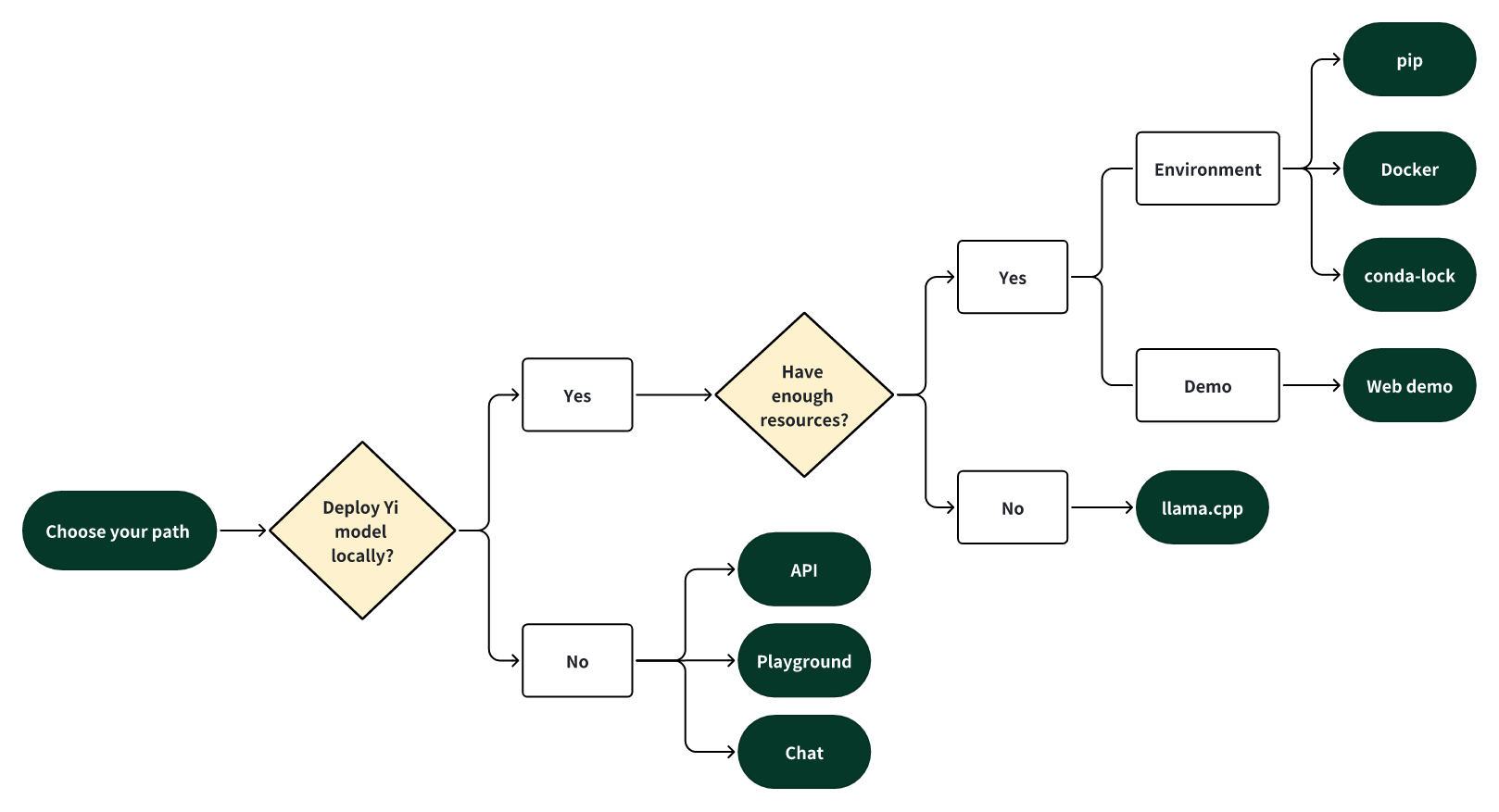
🎯 在本地部署 Yi
如果你更倾向于在本地部署 Yi 模型:
🙋♀️ 如果你拥有 充足 的资源(例如 NVIDIA A800 80GB),你可以选择以下方法之一:
🙋♀️ 如果你只有 有限 的资源(例如 MacBook Pro),可以使用 llama.cpp。
🎯 不在本地部署 Yi
如果你不希望在本地部署 Yi 模型,可以通过以下任意一种方式来体验 Yi 的能力。
🙋♀️ 使用 API 运行 Yi
如果你想探索 Yi 的更多功能,可以采用以下方法之一:
🙋♀️ 在 Playground 中运行 Yi
如果你想以更多自定义选项(如系统提示、温度、重复惩罚等)与 Yi 对话,可以尝试以下几种方式:
Yi-34B-Chat-Playground(Yi 官方)
Yi-34B-Chat-Playground(Replicate)
🙋♀️ 与 Yi 聊天
如果你想与 Yi 对话,可以使用以下在线服务,它们提供相似的用户体验:
Yi-34B-Chat(Hugging Face 上的 Yi 官方版本)
- 无需注册。
Yi-34B-Chat(Yi 官方测试版)
[ 返回顶部 ⬆️ ]
快速入门 - pip
本教程将指导你完成在 A800(80G)上本地运行 Yi-34B-Chat 并进行推理的全过程。
步骤 0:先决条件
确保已安装 Python 3.10 或更高版本。
如果你想运行其他 Yi 模型,请参阅 软硬件要求。
步骤 1:准备环境
要设置环境并安装所需包,请执行以下命令。
git clone https://github.com/01-ai/Yi.git
cd yi
pip install -r requirements.txt
步骤 2:下载 Yi 模型
你可以从以下来源下载 Yi 模型的权重和分词器:
步骤 3:进行推理
你可以按照以下方式对 Yi 的聊天模型或基础模型进行推理。
使用 Yi 聊天模型进行推理
创建一个名为
quick_start.py的文件,并将以下内容复制到其中。from transformers import AutoModelForCausalLM, AutoTokenizer model_path = '<your-model-path>' tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False) # 自 transformers 4.35.0 起,GPT-Q/AWQ 模型可使用 AutoModelForCausalLM 加载。 model = AutoModelForCausalLM.from_pretrained( model_path, device_map="auto", torch_dtype='auto' ).eval() # 提示内容:“hi” messages = [ {"role": "user", "content": "hi"} ] input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt') output_ids = model.generate(input_ids.to('cuda')) response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True) # 模型响应:“Hello! How can I assist you today?” print(response)运行
quick_start.py。python quick_start.py你将看到类似以下的输出。🥳
Hello! How can I assist you today?
使用 Yi 基础模型进行推理
Yi-34B
步骤与 pip - 使用 Yi 聊天模型进行推理 类似。
你可以直接使用现有的文件
text_generation.py。python demo/text_generation.py --model <your-model-path>你将看到类似以下的输出。🥳
输出。⬇️
提示:让我给你讲一个关于猫汤姆和老鼠杰瑞的有趣故事,
生成:让我给你讲一个关于猫汤姆和老鼠杰瑞的有趣故事,这发生在我小时候。我父亲有一栋大房子,里面养了两只猫来抓老鼠。有一天,我独自在家玩耍时,发现其中一只公猫正仰面躺在厨房门口附近,看起来好像想让我们做点什么,却因为周围人太多而起不来!它试了好几分钟,最后还是放弃了……
Yi-9B
输入
from transformers import AutoModelForCausalLM, AutoTokenizer MODEL_DIR = "01-ai/Yi-9B" model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype="auto") tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, use_fast=False) input_text = "# 写出快速排序算法" inputs = tokenizer(input_text, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_length=256) print(tokenizer.decode(outputs[0], skip_special_tokens=True))输出
# 写出快速排序算法 def quick_sort(arr): if len(arr) <= 1: return arr pivot = arr[len(arr) // 2] left = [x for x in arr if x < pivot] middle = [x for x in arr if x == pivot] right = [x for x in arr if x > pivot] return quick_sort(left) + middle + quick_sort(right) # 测试快速排序算法 print(quick_sort([3, 6, 8, 10, 1, 2, 1]))
[ 返回顶部 ⬆️ ]
快速入门 - Docker
使用 Docker 在本地运行 Yi-34B-chat:分步指南。⬇️
本教程将引导您完成在本地使用 A800 GPU 或 4*4090 运行 Yi-34B-Chat 并进行推理的每一个步骤。
步骤 0:先决条件
请确保已安装 Docker 和 NVIDIA 容器工具包。
步骤 1:启动 Docker
docker run -it --gpus all \
-v <your-model-path>: /models
ghcr.io/01-ai/yi:latest
或者,您也可以从 registry.lingyiwanwu.com/ci/01-ai/yi:latest 拉取 Yi 的 Docker 镜像。
步骤 2:进行推理
您可以按照如下方式使用 Yi 聊天模型或基础模型进行推理。
使用 Yi 聊天模型进行推理
步骤与 pip - 使用 Yi 聊天模型进行推理 类似。
注意,唯一的区别是需要将 model_path = '<your-model-mount-path>' 替换为 model_path = '<your-model-path>'。
使用 Yi 基础模型进行推理
步骤与 pip - 使用 Yi 基础模型进行推理 类似。
注意,唯一的区别是需要将 --model <your-model-mount-path>' 替换为 model <your-model-path>。
快速入门 - conda-lock
您可以使用 conda-lock 为 Conda 环境生成完全可复现的锁定文件。⬇️
您可以参考 conda-lock.yml 来获取依赖项的确切版本。此外,您还可以使用
micromamba 来安装这些依赖项。
要安装依赖项,请按照以下步骤操作:
按照 此处 的说明安装 micromamba。
执行
micromamba install -y -n yi -f conda-lock.yml,以创建名为yi的 Conda 环境并安装必要的依赖项。
快速入门 - llama.cpp
以下教程将指导您完成在本地运行量化模型(Yi-chat-6B-2bits)并进行推理的每一个步骤。
使用 llama.cpp 在本地运行 Yi-chat-6B-2bits:分步指南。⬇️
本教程将指导您完成在本地运行量化模型(Yi-chat-6B-2bits)并进行推理的每一个步骤。
步骤 0:先决条件
本教程假设您使用配备 16GB 内存和 Apple M2 Pro 芯片的 MacBook Pro。
请确保您的机器上已安装
git-lfs。
步骤 1:下载 llama.cpp
要克隆 llama.cpp 仓库,运行以下命令。
git clone git@github.com:ggerganov/llama.cpp.git
步骤 2:下载 Yi 模型
2.1 若要仅通过指针克隆 XeIaso/yi-chat-6B-GGUF,运行以下命令。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/XeIaso/yi-chat-6B-GGUF
2.2 若要下载量化后的 Yi 模型(yi-chat-6b.Q2_K.gguf),运行以下命令。
git-lfs pull --include yi-chat-6b.Q2_K.gguf
步骤 3:进行推理
要使用 Yi 模型进行推理,您可以采用以下方法之一。
方法 1:在终端中进行推理
要使用 4 个线程编译 llama.cpp 并进行推理,请进入 llama.cpp 目录,然后运行以下命令。
提示
请将
/Users/yu/yi-chat-6B-GGUF/yi-chat-6b.Q2_K.gguf替换为您模型的实际路径。默认情况下,模型以补全模式运行。
如需更多输出自定义选项(例如系统提示、温度、重复惩罚等),可运行
./main -h查看详细说明和用法。
make -j4 && ./main -m /Users/yu/yi-chat-6B-GGUF/yi-chat-6b.Q2_K.gguf -p "如何喂养您的宠物狐狸?请用 6 个简单步骤回答这个问题:\n第 1 步:" -n 384 -e
...
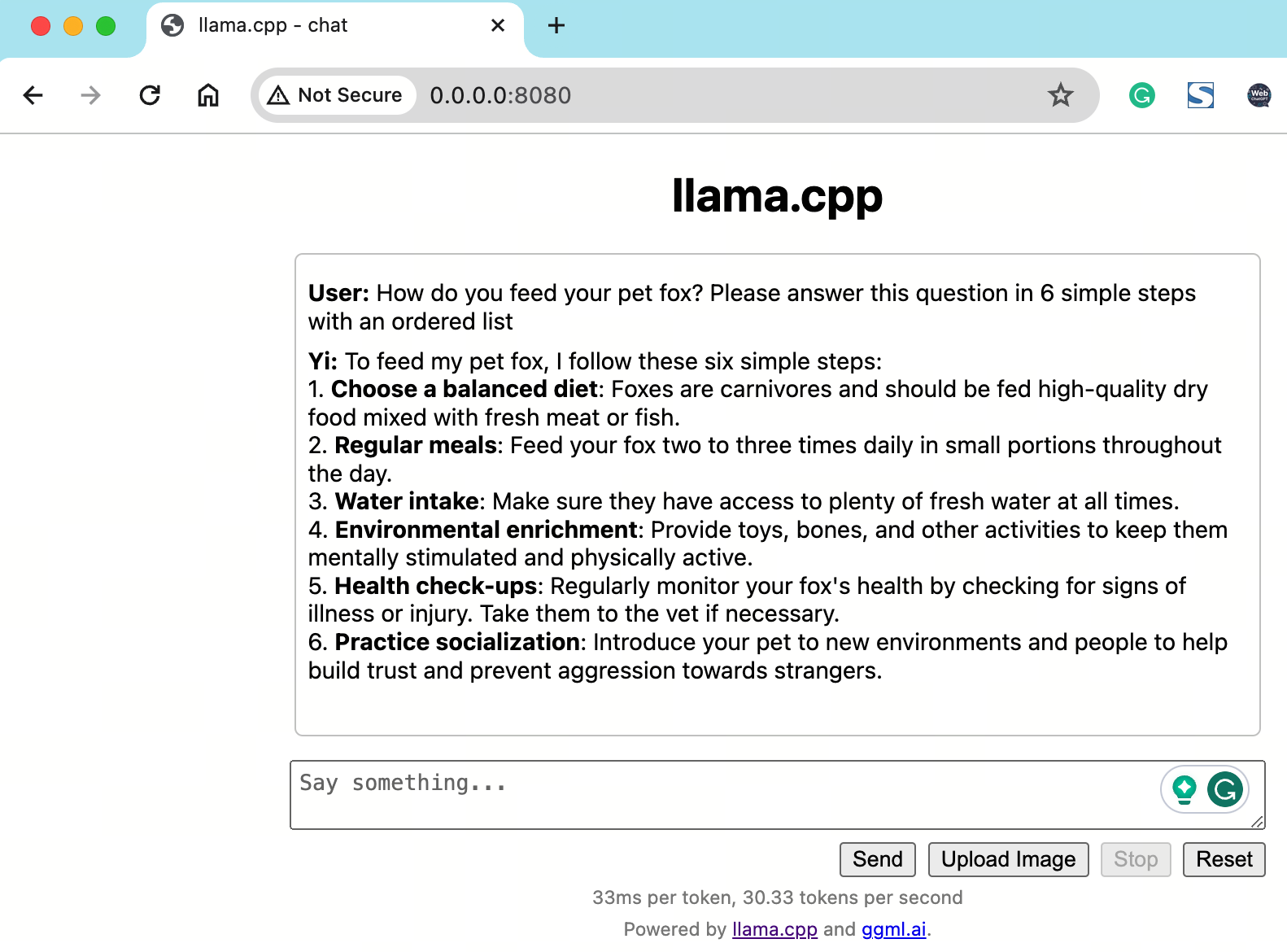
如何喂养您的宠物狐狸?请用 6 个简单步骤回答这个问题:
第 1 步:为您的宠物狐狸选择合适的食物。您应选择高质量、均衡的猎物,这些猎物应符合其独特的饮食需求。这些可能包括活体或冷冻的老鼠、大鼠、鸽子或其他小型哺乳动物,以及新鲜的水果和蔬菜。
第 2 步:根据狐狸的种类及其个人偏好,每天喂食一到两次。务必确保它们全天都能获得新鲜的水。
第 3 步:为您的宠物狐狸提供合适的环境。确保它有一个舒适的休息场所、充足的活动空间,以及玩耍和锻炼的机会。
第 4 步:如果可能的话,让您的宠物与其他动物互动。与其他生物的互动可以帮助它们培养社交技能,防止无聊或压力。
第 5 步:定期检查您的狐狸是否有疾病或不适的迹象。准备好在必要时提供兽医护理,尤其是针对寄生虫、牙齿健康问题或感染等常见问题。
第 6 步:了解您的宠物狐狸的需求,并注意任何可能影响其福祉的风险或担忧。定期咨询兽医,以确保您提供最佳的护理。
...
现在您已成功向 Yi 模型提问并获得了答案!🥳
方法 2:在网页中进行推理
要初始化一个轻量且快速的聊天机器人,运行以下命令。
cd llama.cpp ./server --ctx-size 2048 --host 0.0.0.0 --n-gpu-layers 64 --model /Users/yu/yi-chat-6B-GGUF/yi-chat-6b.Q2_K.gguf然后您将看到如下输出:
... llama_new_context_with_model: n_ctx = 2048 llama_new_context_with_model: freq_base = 5000000.0 llama_new_context_with_model: freq_scale = 1 ggml_metal_init: allocating ggml_metal_init: found device: Apple M2 Pro ggml_metal_init: picking default device: Apple M2 Pro ggml_metal_init: ggml.metallib not found, loading from source ggml_metal_init: GGML_METAL_PATH_RESOURCES = nil ggml_metal_init: loading '/Users/yu/llama.cpp/ggml-metal.metal' ggml_metal_init: GPU name: Apple M2 Pro ggml_metal_init: GPU family: MTLGPUFamilyApple8 (1008) ggml_metal_init: hasUnifiedMemory = true ggml_metal_init: recommendedMaxWorkingSetSize = 11453.25 MB ggml_metal_init: maxTransferRate = built-in GPU ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 128.00 MiB, ( 2629.44 / 10922.67) llama_new_context_with_model: KV self size = 128.00 MiB, K (f16): 64.00 MiB, V (f16): 64.00 MiB ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 0.02 MiB, ( 2629.45 / 10922.67) llama_build_graph: non-view tensors processed: 676/676 llama_new_context_with_model: compute buffer total size = 159.19 MiB ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 156.02 MiB, ( 2785.45 / 10922.67) Available slots: -> Slot 0 - max context: 2048 llama server listening at http://0.0.0.0:8080要访问聊天机器人界面,打开您的网页浏览器,在地址栏中输入
http://0.0.0.0:8080。
在提示框中输入一个问题,例如“如何喂养您的宠物狐狸?请用 6 个简单步骤回答这个问题”,您将收到相应的答案。
[ 返回顶部 ⬆️ ]
网页演示
您可以为 Yi 聊天 模型构建一个 Web UI 演示(请注意,在此场景下不支持 Yi 基础模型)。
步骤 3. 要在本地启动 Web 服务,请运行以下命令。
python demo/web_demo.py -c <your-model-path>
您可以通过在浏览器中输入控制台提供的地址来访问 Web UI。
[ 返回顶部 ⬆️ ]
微调
bash finetune/scripts/run_sft_Yi_6b.sh
完成后,您可以使用以下命令比较微调后的模型和基础模型:
bash finetune/scripts/run_eval.sh
对于高级用法(例如基于自定义数据进行微调),请参阅下方的说明。⬇️
Yi 6B 和 34B 的微调代码
准备工作
从镜像中获取
默认情况下,我们使用来自 BAAI/COIG 的小型数据集来微调基础模型。
您也可以按照以下 jsonl 格式准备自定义数据集:
{ "prompt": "Human: 你是谁?Assistant:", "chosen": "我是 Yi。" }
然后将这些数据挂载到容器中,以替换默认的数据集:
docker run -it \
-v /path/to/save/finetuned/model/:/finetuned-model \
-v /path/to/train.jsonl:/yi/finetune/data/train.json \
-v /path/to/eval.jsonl:/yi/finetune/data/eval.json \
ghcr.io/01-ai/yi:latest \
bash finetune/scripts/run_sft_Yi_6b.sh
从本地服务器中获取
请确保您已安装 conda。如果没有,请执行以下操作:
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
source ~/.bashrc
然后创建一个 conda 环境:
conda create -n dev_env python=3.10 -y
conda activate dev_env
pip install torch==2.0.1 deepspeed==0.10 tensorboard transformers datasets sentencepiece accelerate ray==2.7
硬件配置
对于 Yi-6B 模型,建议使用配备 4 张 GPU 的节点,每张 GPU 的显存需大于 60GB。
对于 Yi-34B 模型,由于零卸载技术会消耗大量 CPU 内存,请务必谨慎限制 34B 微调训练中使用的 GPU 数量。请使用 CUDA_VISIBLE_DEVICES 来限制 GPU 数量(如 scripts/run_sft_Yi_34b.sh 中所示)。
典型的 34B 模型微调硬件配置为:配备 8 张 GPU 的节点(通过 CUDA_VISIBLE_DEVICES=0,1,2,3 限制为 4 张),每张 GPU 的显存需大于 80GB,且总 CPU 内存需大于 900GB。
快速开始
将 LLM 基础模型下载到 MODEL_PATH(6B 和 34B)。典型的模型文件夹结构如下:
|-- $MODEL_PATH
| |-- config.json
| |-- pytorch_model-00001-of-00002.bin
| |-- pytorch_model-00002-of-00002.bin
| |-- pytorch_model.bin.index.json
| |-- tokenizer_config.json
| |-- tokenizer.model
| |-- ...
从 Hugging Face 下载数据集到本地存储 DATA_PATH,例如 Dahoas/rm-static。
|-- $DATA_PATH
| |-- data
| | |-- train-00000-of-00001-2a1df75c6bce91ab.parquet
| | |-- test-00000-of-00001-8c7c51afc6d45980.parquet
| |-- dataset_infos.json
| |-- README.md
finetune/yi_example_dataset 包含示例数据集,这些数据集改编自 BAAI/COIG。
|-- $DATA_PATH
|--data
|-- train.jsonl
|-- eval.jsonl
进入 scripts 文件夹,复制并粘贴脚本,然后运行。例如:
cd finetune/scripts
bash run_sft_Yi_6b.sh
对于 Yi-6B 基础模型,设置 training_debug_steps=20 和 num_train_epochs=4 可以输出一个聊天模型,整个过程大约需要 20 分钟。
对于 Yi-34B 基础模型,初始化过程相对较长,请耐心等待。
评估
cd finetune/scripts
bash run_eval.sh
随后您将看到来自基础模型和微调后模型的回答。
[ 返回顶部 ⬆️ ]
量化
GPT-Q
python quantization/gptq/quant_autogptq.py \
--model /base_model \
--output_dir /quantized_model \
--trust_remote_code
完成之后,您可以按照以下方式评估生成的模型:
python quantization/gptq/eval_quantized_model.py \
--model /quantized_model \
--trust_remote_code
详情请参阅下方说明。⬇️
GPT-Q 量化
GPT-Q 是一种 PTQ(训练后量化)方法。它可以在保持模型精度的同时节省内存并带来潜在的速度提升。
Yi 模型可以轻松地进行 GPT-Q 量化。我们将在下面提供一个分步教程。
为了运行 GPT-Q,我们将使用 AutoGPTQ 和 exllama。Hugging Face Transformers 已经集成了 optimum 和 auto-gptq,以对语言模型执行 GPT-Q 量化。
进行量化
我们提供了 quant_autogptq.py 脚本,供您执行 GPT-Q 量化:
python quant_autogptq.py --model /base_model \
--output_dir /quantized_model --bits 4 --group_size 128 --trust_remote_code
运行量化后的模型
您可以使用 eval_quantized_model.py 来运行量化后的模型:
python eval_quantized_model.py --model /quantized_model --trust_remote_code
AWQ
python quantization/awq/quant_autoawq.py \
--model /base_model \
--output_dir /quantized_model \
--trust_remote_code
完成之后,您可以按照以下方式评估生成的模型:
python quantization/awq/eval_quantized_model.py \
--model /quantized_model \
--trust_remote_code
详情请参阅下方说明。⬇️
AWQ 量化
AWQ 是一种 PTQ(训练后量化)方法。它是一种高效且准确的低比特权重量化(INT3/4),适用于大型语言模型。
Yi 模型可以轻松地进行 AWQ 量化。我们将在下面提供一个分步教程。
为了运行 AWQ,我们将使用 AutoAWQ。
进行量化
我们提供了 quant_autoawq.py 脚本,供您执行 AWQ 量化:
python quant_autoawq.py --model /base_model \
--output_dir /quantized_model --bits 4 --group_size 128 --trust_remote_code
运行量化后的模型
您可以使用 eval_quantized_model.py 来运行量化后的模型:
python eval_quantized_model.py --model /quantized_model --trust_remote_code
[ 返回顶部 ⬆️ ]
部署
如果您想部署 Yi 模型,请确保满足软件和硬件要求。
软件要求
在使用 Yi 量化模型之前,请确保已安装以下正确的软件。
| 模型 | 软件 |
|---|---|
| Yi 4-bit 量化模型 | AWQ 和 CUDA |
| Yi 8-bit 量化模型 | GPTQ 和 CUDA |
硬件要求
在将 Yi 部署到您的环境中之前,请确保您的硬件满足以下要求。
对话模型
| 模型 | 最小显存 | 推荐 GPU 示例 |
|---|---|---|
| Yi-6B-Chat | 15 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) |
| Yi-6B-Chat-4bits | 4 GB | 1 x RTX 3060 (12 GB) 1 x RTX 4060 (8 GB) |
| Yi-6B-Chat-8bits | 8 GB | 1 x RTX 3070 (8 GB) 1 x RTX 4060 (8 GB) |
| Yi-34B-Chat | 72 GB | 4 x RTX 4090 (24 GB) 1 x A800 (80GB) |
| Yi-34B-Chat-4bits | 20 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) 1 x A100 (40 GB) |
| Yi-34B-Chat-8bits | 38 GB | 2 x RTX 3090 (24 GB) 2 x RTX 4090 (24 GB) 1 x A800 (40 GB) |
以下是不同批量情况下的详细最小显存要求。
| 模型 | batch=1 | batch=4 | batch=16 | batch=32 |
|---|---|---|---|---|
| Yi-6B-Chat | 12 GB | 13 GB | 15 GB | 18 GB |
| Yi-6B-Chat-4bits | 4 GB | 5 GB | 7 GB | 10 GB |
| Yi-6B-Chat-8bits | 7 GB | 8 GB | 10 GB | 14 GB |
| Yi-34B-Chat | 65 GB | 68 GB | 76 GB | > 80 GB |
| Yi-34B-Chat-4bits | 19 GB | 20 GB | 30 GB | 40 GB |
| Yi-34B-Chat-8bits | 35 GB | 37 GB | 46 GB | 58 GB |
基础模型
| 模型 | 最小显存 | 推荐 GPU 示例 |
|---|---|---|
| Yi-6B | 15 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) |
| Yi-6B-200K | 50 GB | 1 x A800 (80 GB) |
| Yi-9B | 20 GB | 1 x RTX 4090 (24 GB) |
| Yi-34B | 72 GB | 4 x RTX 4090 (24 GB) 1 x A800 (80 GB) |
| Yi-34B-200K | 200 GB | 4 x A800 (80 GB) |
[ 返回顶部 ⬆️ ]
常见问题解答
如果您在使用 Yi 系列模型时有任何疑问,以下提供的答案可以作为您的参考。⬇️
💡微调
- 基础模型还是对话模型——该选择哪一个进行微调?
选择哪种预训练语言模型进行微调,主要取决于您可用的计算资源以及任务的具体需求。- 如果您拥有大量的微调数据(比如超过1万条样本),那么基础模型可能是您的首选。
- 相反,如果您拥有的微调数据量较少,那么对话模型可能更适合您。
- 通常建议同时微调基础模型和对话模型,比较它们的表现,然后根据具体需求选择最合适的模型。
- Yi-34B 和 Yi-34B-Chat 进行全参数微调有什么区别?
在 `Yi-34B` 和 `Yi-34B-Chat` 上进行全参数微调的主要区别在于微调方法及其效果。 - Yi-34B-Chat 采用特殊微调(SFT)方法,生成的回复更接近人类对话风格。 - 基础模型的微调则更为通用,且具有较高的性能潜力。 - 如果您对自己的数据质量有信心,可以选择使用 `Yi-34B` 进行微调。 - 如果您希望模型生成的回复更贴近人类对话风格,或者对数据质量有所顾虑,那么 `Yi-34B-Chat` 可能是更好的选择。
💡量化
- 量化模型与原始模型相比,性能差距有多大?
- 性能差异主要取决于所使用的量化方法以及这些模型的具体应用场景。例如,对于 AWQ 官方提供的模型而言,在基准测试中,量化可能会导致性能小幅下降几个百分点。
- 从主观感受来看,在逻辑推理等场景下,即使只有1%的性能变化,也可能影响输出结果的准确性。
💡综合
我在哪里可以找到用于问答任务的微调数据集?
- 您可以在 Hugging Face 等平台上找到问答任务的微调数据集,例如 m-a-p/COIG-CQIA 数据集就非常容易获取。
- 此外,Github 上也提供了微调框架,比如 hiyouga/LLaMA-Factory,其中整合了现成的数据集。
微调 Yi-34B FP16 需要多少显存?
微调 34B FP16 所需的显存大小取决于具体的微调方法。如果是全参数微调,则需要8张每张80 GB显存的GPU;而像 LoRA 这样的经济型方案则所需显存较少。更多细节请参阅 [hiyouga/LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory)。此外,为了优化性能,也可以考虑使用 BF16 而不是 FP16 进行微调。是否有第三方平台支持 Yi-34b-200k 模型的聊天功能?
如果您正在寻找第三方聊天平台,可以选择 [fireworks.ai](https://fireworks.ai/login?callbackURL=https://fireworks.ai/models/fireworks/yi-34b-chat)。
学习中心
如果您想学习 Yi,这里有许多有用的教育资源可供您参考。⬇️
欢迎来到 Yi 学习中心!
无论您是经验丰富的开发者还是初学者,都可以在这里找到丰富的学习资源,帮助您更好地理解并掌握 Yi 模型的相关知识,包括深度博客文章、全面的视频教程、实践指南等等。
这里的内容由众多精通 Yi 的专家和热情爱好者无私分享而来。我们衷心感谢大家的宝贵贡献!
同时,我们也诚挚邀请您加入我们的共建行列,为 Yi 贡献一份力量。如果您已经为 Yi 做过贡献,请不要犹豫,在下方表格中展示您的优秀成果吧。
有了这些资源的帮助,相信您已经准备好开启一段精彩的 Yi 学习之旅了!祝您学习愉快!🥳
教程
博客教程
GitHub 项目
| 可交付成果 | 日期 | 作者 |
|---|---|---|
| yi-openai-proxy | 2024-05-11 | 苏洋 |
| 基于零一万物 Yi 模型和 B 站构建大语言模型高质量训练数据集 | 2024-04-29 | 正经人王同学 |
| 基于视频网站和零一万物大模型构建大语言模型高质量训练数据集 | 2024-04-25 | 正经人王同学 |
| 基于零一万物yi-34b-chat-200k输入任意文章地址,点击按钮即可生成无广告或推广内容的简要笔记,并生成分享图给好友 | 2024-04-24 | 正经人王同学 |
| Food-GPT-Yi-model | 2024-04-21 | Hubert S |
视频教程
为什么选择 Yi?
生态系统
Yi 拥有全面的生态系统,提供一系列工具、服务和模型,以丰富您的使用体验并最大化生产力。
上游
Yi 系列模型沿用了与 Llama 相同的模型架构。选择 Yi,您可以充分利用 Llama 生态系统中现有的工具、库和资源,无需重新开发新工具,从而提升开发效率。
例如,Yi 系列模型以 Llama 模型的格式保存。您可以直接使用 LlamaForCausalLM 和 LlamaTokenizer 加载模型。更多信息请参阅 使用聊天模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("01-ai/Yi-34b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("01-ai/Yi-34b", device_map="auto")
[ 返回顶部 ⬆️ ]
下游
💡 小贴士
欢迎创建 PR,分享您使用 Yi 系列模型所构建的优秀成果。
为了帮助他人快速理解您的工作,建议采用
<模型名称>: <模型简介> + <模型亮点>的格式。
推理服务
如果您希望在几分钟内快速上手 Yi,可以使用以下基于 Yi 构建的服务。
Yi-34B-Chat:您可以通过以下平台与 Yi 对话:
- Yi-34B-Chat | Hugging Face
- Yi-34B-Chat | Yi 平台:注意 目前仅限白名单用户使用。欢迎申请(填写 英文 或 中文 表单)并亲身体验!
Yi-6B-Chat (Replicate):您可以通过设置额外参数并调用 API 来使用该模型,获得更多选项。
ScaleLLM:您可使用此服务在本地运行 Yi 模型,同时享受更高的灵活性和自定义能力。
量化
如果您计算资源有限,可以使用 Yi 的量化模型,如下所示。
这些量化模型虽然精度有所降低,但效率更高,例如推理速度更快、内存占用更小。
微调
如果您希望探索 Yi 繁荣家族中的多样化能力,可以深入研究以下微调模型。
- TheBloke Models:该网站托管了许多基于各种 LLM(包括 Yi)微调的模型。
这并非 Yi 的完整列表,但按下载量排序,列举几个示例:
SUSTech/SUS-Chat-34B:该模型在所有 70B 以下的模型中排名第一,并且性能优于两倍规模的 deepseek-llm-67b-chat。您可以在 Open LLM Leaderboard 上查看结果。
OrionStarAI/OrionStar-Yi-34B-Chat-Llama:该模型在 OpenCompass LLM Leaderboard 的 C-Eval 和 CMMLU 测试中,表现超越了其他模型(如 GPT-4、Qwen-14B-Chat、Baichuan2-13B-Chat)。
NousResearch/Nous-Capybara-34B:该模型使用 Capybara 数据集训练,上下文长度为 20 万,训练了 3 个 epoch。
API
- amazing-openai-api:该工具可将 Yi 模型的 API 直接转换为 OpenAI API 格式。
- LlamaEdge:该工具利用 Rust 编写的便携式 Wasm(WebAssembly)文件,为 Yi-34B-Chat 构建了一个兼容 OpenAI 的 API 服务器。
[ 返回顶部 ⬆️ ]
技术报告
有关 Yi 系列模型的详细能力,请参阅 Yi: 由 01.AI 开放的基础模型。
引用
@misc{ai2024yi,
title={Yi: Open Foundation Models by 01.AI},
author={01. AI and : and Alex Young and Bei Chen and Chao Li and Chengen Huang and Ge Zhang and Guanwei Zhang and Heng Li and Jiangcheng Zhu and Jianqun Chen and Jing Chang and Kaidong Yu and Peng Liu and Qiang Liu and Shawn Yue and Senbin Yang and Shiming Yang and Tao Yu and Wen Xie and Wenhao Huang and Xiaohui Hu and Xiaoyi Ren and Xinyao Niu and Pengcheng Nie and Yuchi Xu and Yudong Liu and Yue Wang and Yuxuan Cai and Zhenyu Gu and Zhiyuan Liu and Zonghong Dai},
year={2024},
eprint={2403.04652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
基准测试
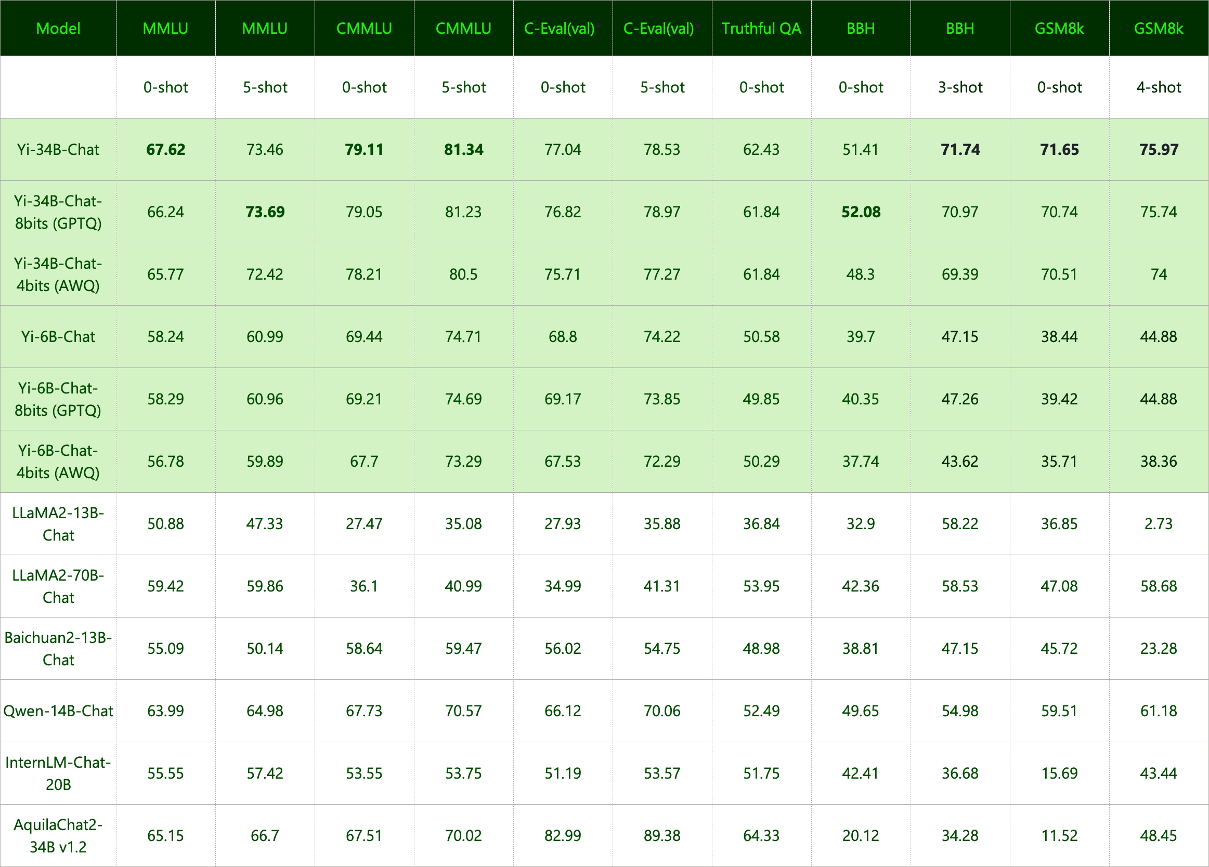
聊天模型性能
Yi-34B-Chat 模型表现出色,在 MMLU、CMMLU、BBH、GSM8k 等多项基准测试中位居所有开源模型之首。
评估方法与挑战。⬇️
- 评估方法:我们使用零样本和少样本两种方式对各类基准进行了评估,TruthfulQA 除外。
- 零样本 vs. 少样本:在聊天模型中,通常更倾向于采用零样本方法。
- 评估策略:我们的评估策略是在明确或隐含地遵循指令(例如通过少样本示例)的情况下生成响应,随后从生成的文本中提取相关答案。
- 面临的挑战:部分模型并不擅长以少数数据集指令所要求的特定格式输出,这导致了次优的结果。
*:C-Eval 的结果基于验证数据集进行评估
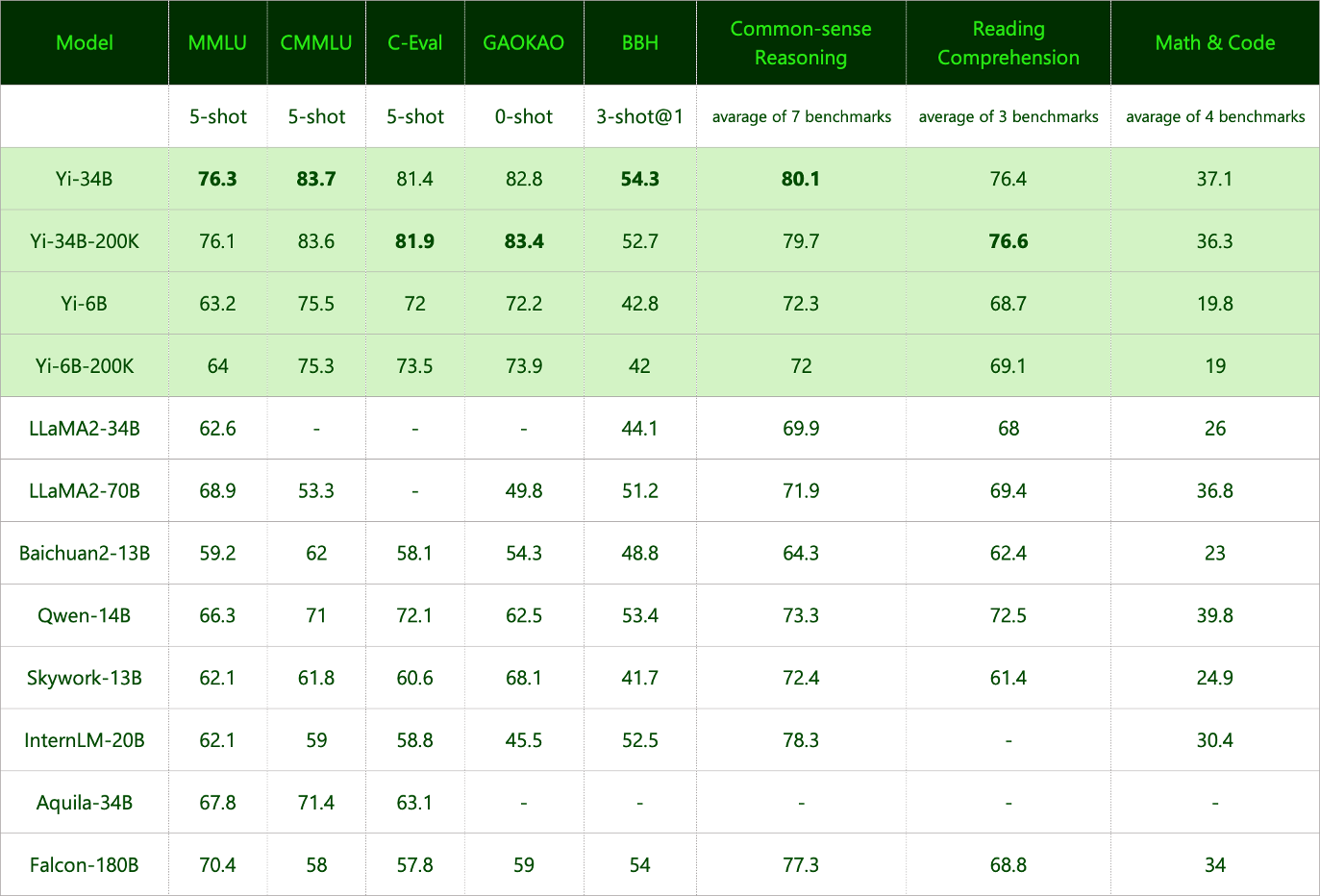
基础模型性能
Yi-34B 和 Yi-34B-200K
Yi-34B 和 Yi-34B-200K 模型在开源模型中表现突出,尤其在 MMLU、CMMLU、常识推理、阅读理解等方面表现出色。
评估方法。⬇️
- 结果差异:在对开源模型进行基准测试时,我们发现自身流水线的结果与 OpenCompass 等公开来源报告的结果存在差异。
- 调查结果:深入分析表明,不同模型在提示词、后处理策略以及采样技术上的差异可能导致显著的结果偏差。
- 统一的基准测试流程:我们的方法遵循原始基准测试的标准——使用一致的提示词和后处理策略,并在评估过程中采用贪婪解码,不对生成内容进行任何后处理。
- 尝试获取未公开的分数:对于原始作者未报告的分数(包括以不同设置报告的分数),我们尝试用自身的流水线重新计算。
- 全面的模型评估:为全面评估模型能力,我们采用了 Llama2 中的方法。具体而言,我们加入了 PIQA、SIQA、HellaSwag、WinoGrande、ARC、OBQA 和 CSQA 来评估常识推理能力。同时,还引入了 SquAD、QuAC 和 BoolQ 来评估阅读理解能力。
- 特殊配置:CSQA 仅采用 7 抽样设置进行测试,其余测试均采用 0 抽样设置。此外,我们在“数学与代码”类别下引入了 GSM8K(8 抽样@1)、MATH(4 抽样@1)、HumanEval(0 抽样@1)和 MBPP(3 抽样@1)。
- Falcon-180B 的说明:由于技术限制,Falcon-180B 未在 QuAC 和 OBQA 上进行测试。其性能评分是其他任务的平均值,考虑到这两项任务的得分普遍较低,Falcon-180B 的实际能力可能并未被低估。
Yi-9B
Yi-9B 在一系列类似规模的开源模型中几乎处于最佳位置(包括 Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5 等),尤其在代码、数学、常识推理和阅读理解方面表现优异。
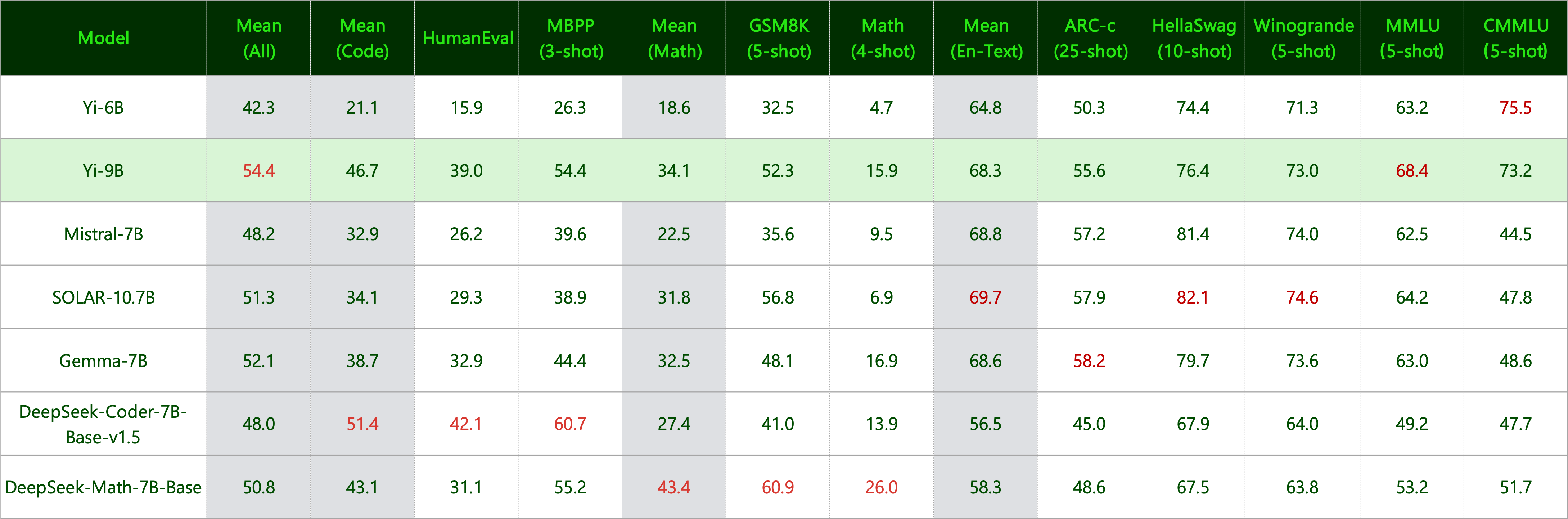
在 综合 能力方面(Mean-All),Yi-9B 表现优于 DeepSeek-Coder、DeepSeek-Math、Mistral-7B、SOLAR-10.7B 和 Gemma-7B,位居同类开源模型之首。
在 编码 能力方面(Mean-Code),Yi-9B 的表现仅次于 DeepSeek-Coder-7B,超越了 Yi-34B、SOLAR-10.7B、Mistral-7B 和 Gemma-7B。
在 数学 能力方面(Mean-Math),Yi-9B 的表现仅次于 DeepSeek-Math-7B,超过了 SOLAR-10.7B、Mistral-7B 和 Gemma-7B。
在 常识与推理 能力方面(Mean-Text),Yi-9B 的表现与 Mistral-7B、SOLAR-10.7B 和 Gemma-7B 不相上下。
[ 返回顶部 ⬆️ ]
谁可以使用 Yi?
所有人都可以!🙌 ✅
Yi 系列模型的代码和权重依据 Apache 2.0 许可证 进行分发,这意味着 Yi 系列模型可供个人使用、学术研究以及商业用途,且完全免费。
[ 返回顶部 ⬆️ ]
其他
致谢
衷心感谢每一位为 Yi 社区做出贡献的人!正是你们的努力,让 Yi 不仅仅是一个项目,更成为一个充满活力、不断发展的创新家园。

[ 返回顶部 ⬆️ ]
免责声明
我们在训练过程中使用了数据合规性检查算法,以尽可能确保训练后的模型符合规范。然而,由于数据的复杂性和语言模型应用场景的多样性,我们无法保证模型在所有情况下都能生成正确且合理的输出。请注意,模型仍有可能产生问题输出的风险。对于因误用、误导、非法使用及相关虚假信息而引发的风险和问题,以及由此产生的任何数据安全顾虑,我们概不负责。
[ 返回顶部 ⬆️ ]
许可证
Yi-1.5 系列模型的代码和权重依据 Apache 2.0 许可证 进行分发。
如果您基于此模型创建衍生作品,请在您的衍生作品中包含以下署名:
本作品是基于 01.AI 的 [您所使用的 Yi 系列模型] 的衍生作品,依据 Apache 2.0 许可证使用。
[ 返回顶部 ⬆️ ]
版本历史
0.1.0常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。